
.webp)
A burger joint decided to play the data game with a humorous flavor. They implemented a recommendation engine to analyze customer preferences, predicting topping combinations that would tickle taste buds. The model considered everything — from weather patterns to lunar phases — because, you know, a full moon might mean extra cheese cravings. As a result, accurate burger suggestions entertained customers and significantly boosted sales. Who knew data science could turn a fast-food joint into a culinary wizard? If this sounds familiar, book a call.
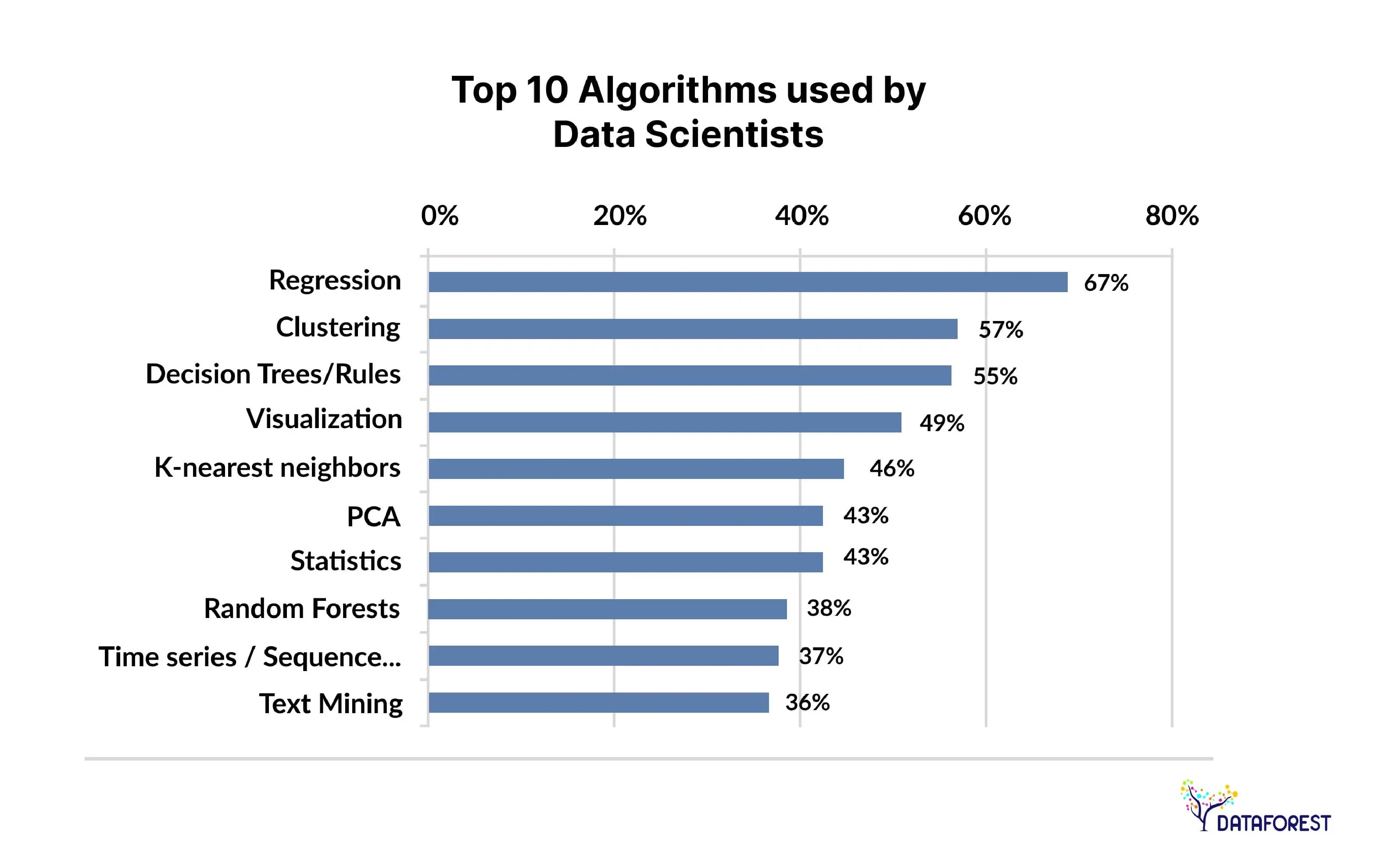
Data Science Algorithms Through Everyday Analogies
These approaches are like recipes in a cookbook: linear regression is your trusted measuring cup, a decision tree acts like step-by-step instructions, and random forests are the versatile spice blends. By comparing such methods to familiar kitchen scenarios, beginners can grasp the essence of data science methods as quickly as following a cooking recipe. To explore how these methods apply to your business, book a call with us.
How These Methods Drive Decisions
Data science algorithms are step-by-step instructions that sift through mountains of information to find patterns, make predictions, and help in decision-making. Imagine them as the brains of the operation, crunching numbers and turning raw data into meaningful insights.
Performance Measurement



They easily understand industry-specific data and KPIs, and their efficiency as a team allows them to deliver results quickly.
They quickly understand industry-specific data and KPIs, and their efficiency as a team allows them to deliver results quickly.
In the grand scheme of analysis, an algorithm acts like a detective on a mission. It examines the evidence, uncovers hidden relationships, and presents a story that might be hiding within the data. The whole discipline is about making informed choices grounded in observed patterns. Businesses rely on these algorithmic insights to guide strategy and make better decisions.

Transforming Data into Insights
These methods play a central role in transforming raw input into actionable insights. Imagine raw data as a chaotic puzzle — the algorithm is the puzzle master that organizes the pieces, revealing the bigger picture. It systematically analyzes patterns, trends, and relationships, extracting valuable information that would otherwise remain hidden. These tools help businesses gain the clarity and direction needed to make informed decisions, navigate challenges, and stay ahead in the fast-paced world of data-driven strategies.
How These Techniques Came to Be
The family of problem-solving tools behind modern analytics evolved over time. It began with pioneers developing linear regression for trend prediction; later, decision trees, k-means clustering, and support vector machines emerged to address new challenges in handling and interpreting information. Each method, like a unique chapter in a digital saga, was crafted through a blend of mathematical ingenuity, trial and error, and a constant quest to transform raw data into insights.
Supervised Learning Approaches
Supervised learning algorithms are the mentors of the data world. They thrive on labeled examples, learning from them to make predictions or classify new data. Think of them as the diligent students in a classroom, guided by a teacher (the labeled data) to excel in tasks.
Unsupervised Learning Approaches
Unsupervised methods are the explorers, delving into the uncharted territory of unlabeled data. They seek patterns and relationships without explicit guidance, like discovering hidden gems in an unexplored landscape. Clustering algorithms, such as k-means, are their go-to tools for organizing and making sense of the data wilderness.
Semi-supervised and Reinforcement Learning Algorithms
Semi-supervised and reinforcement learning techniques operate in a realm of both guidance and exploration. The semi-supervised variety blends labeled and unlabeled data, finding a middle ground where insights are uncovered with partial assistance. On the other hand, reinforcement learning is the adventurer, learning through trial and error, much like a gamer navigating through a virtual world.
Statistical Approaches
Statistical methods are the mathematicians of the field, using probability theory and mathematical models to draw inferences, analyze patterns, and make predictions. They're like the statisticians analyzing game statistics to predict the outcome of the next match — leveraging probability for a deeper understanding.

Data Mining Algorithms
Data mining algorithms are the treasure hunters, sifting through vast datasets to uncover valuable information. They extract patterns, associations, and outliers, much like mining for gold in a rich deposit. These algorithms are essential for businesses looking to extract actionable insights and drive informed decision-making.
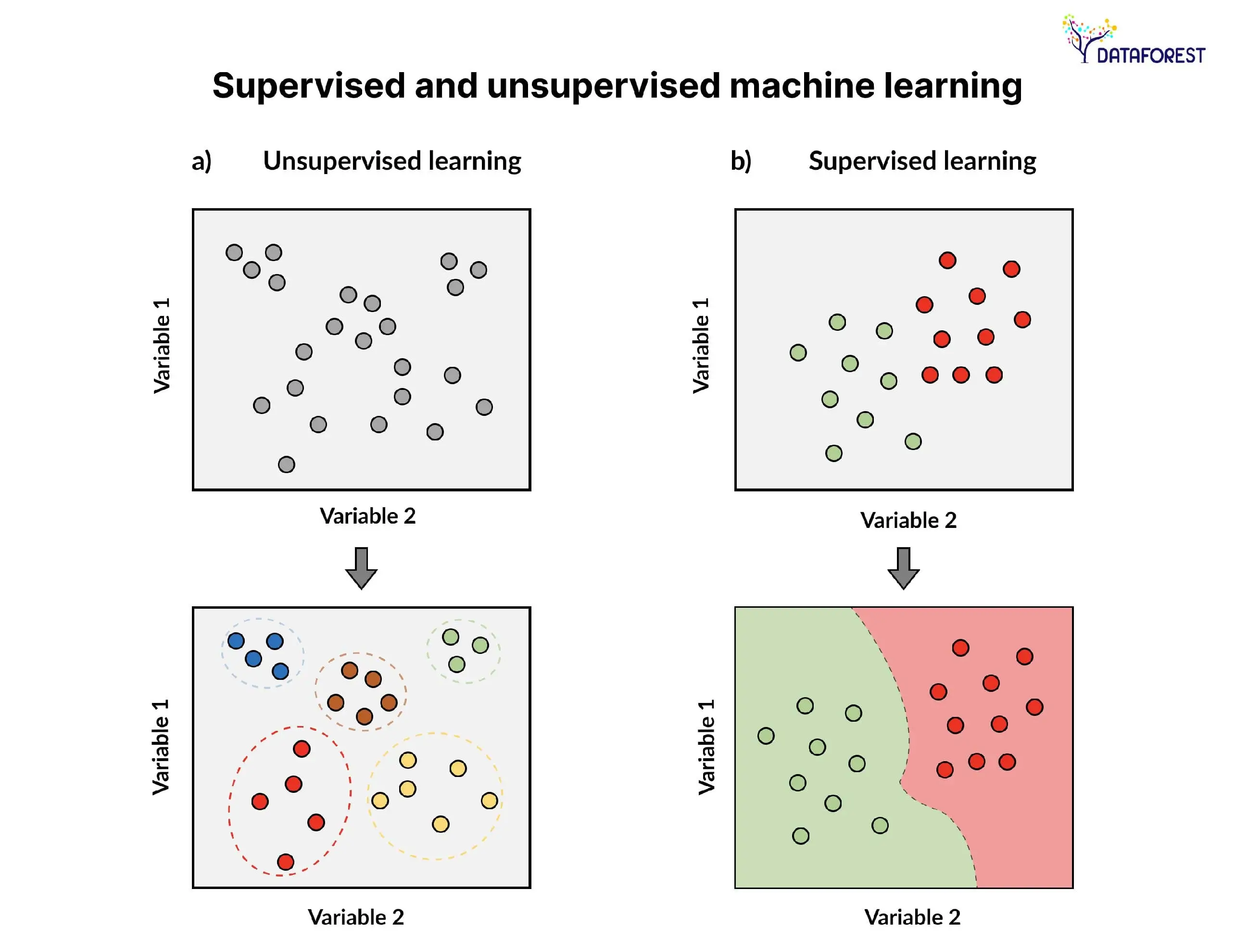
How Common Data Science Algorithms Emerged from Innovation
The typical toolkit was formed through a dynamic interplay of necessity, innovation, and real-world problem-solving. Each member of this family is designed to tackle specific challenges.
- Researchers delved into mathematics, statistics, and computer science to develop the building blocks that would later form the basis of these tools.
- Methods like decision trees were crafted to address complex decision-making scenarios, drawing inspiration from human thought processes.
- Innovations like k-means clustering were born from the need to organize and make sense of diverse datasets, identifying natural groupings within the chaos.
- Random forests aggregate multiple decision trees to improve predictive accuracy, showcasing the power of collaboration in algorithmic design.
- Supervised learning algorithms brought a new dimension to predictive analytics. Unsupervised approaches ventured into unlabeled data, exploring patterns autonomously.
- The toolkit adapted to real-world applications, with statistical methods entering the scene to draw inferences, mirroring how statisticians analyze data.
- The introduction of data mining algorithms marked a phase where the methods became akin to detectives, mining for hidden insights within large datasets.
The standard repertoire we know today was shaped by a continuous problem-solving process, theoretical exploration, and practical adaptation.
Widely Used Methods Across Categories
This table provides a quick overview of the categories, common algorithms, use cases, applications, and critical features for each widely used algorithm type.
How Data Science Algorithms Transform Data
These algorithms function by learning from examples, updating their parameters through iterative refinement, handling the unknown through generalization, and tuning hyperparameters for optimal performance.
Input and Output
- Input: A model is like a chef in a kitchen, and the data it works with are its ingredients. It accepts input in various forms: numbers, text, images, and more.
- Output: The algorithm processes the input and produces a result, which could be predictions, classifications, clusters, or other valuable insights.
Learning from Examples
- Supervised Learning: A model is trained on a dataset with input-output pairs, and through this guidance, it makes predictions or assigns class labels to new, unseen records.
- Unsupervised Learning: Here the algorithm explores unlabeled data, searching for patterns or structures without predefined outputs. Clustering methods, for example, group similar points without explicit guidance.
Iterative Refinement
- Learning Process: Such learners constantly refine their understanding. During training, they make predictions, compare them to actual outcomes, and adjust internal parameters to minimize the difference — it's like tuning a guitar.
- Feedback Loop: The more data the model processes, the better it gets at making accurate predictions or uncovering hidden patterns.

Feature Engineering and Dimensionality Reduction
- Feature Engineering: A model is a detective, and the features in your data are its clues. Feature engineering involves selecting, transforming, or creating new attributes to enhance the model's ability to find meaningful patterns.
- Dimensionality Reduction: Sometimes the data is too complex, like a cluttered room. Reduction techniques simplify it without losing essential information, making the room tidier for better analysis.
Handling the Unseen
- After learning from examples, the methods generalize their knowledge to handle new, unseen cases. It's like teaching kids to recognize different animals: once they know what a cat looks like, they can identify new cats they've never seen.
Parameters and Hyperparameters
- Parameters: Each model carries internal settings, like the volume control on a stereo. During training, these get adjusted to optimize performance.
- Hyperparameters: Hyperparameters are like the stereo's equalizer settings — external configurations that control overall behavior. Choosing the correct values is crucial for fine-tuning performance.

Selecting the Perfect Data Science Algorithms
Choosing the right algorithm is like picking the perfect tool for a DIY project — it's the key to unlocking the full potential of your data project. In the table below, we navigate the considerations that guide the decision-making process, ensuring that your selection aligns with the unique demands of your data.
How to Choose the Right Approach
As data scientists, our role extends beyond crunching numbers — it's about understanding the unique contours of each task and strategically selecting the method that aligns seamlessly with the nature of the data and the problem at hand. By emphasizing considerations like dataset characteristics, problem types, and performance metrics, DATAFOREST empowers clients to make informed decisions. Navigating this landscape is a nuanced art that involves interpreting the needs of the data and sculpting tailored solutions. Complete the form, and our team will analyze your challenge and propose a tailored solution.
FAQ
Are data science algorithms only used in machine learning?
While these algorithms are extensively used in machine learning, their applications extend beyond this domain. They also play crucial roles in statistical analysis, data mining, and various analytical processes, showcasing their versatility in extracting valuable insights from diverse datasets.
Do I need to be a programmer to work with them?
While programming skills can significantly enhance your ability to apply these methods, some user-friendly tools and platforms allow individuals with minimal coding experience to engage in analysis and implementation. However, a foundational understanding of core concepts and methodologies is essential to leverage these tools effectively.
Can they work with both structured and unstructured data?
The toolkit is versatile and can handle structured data, such as databases and spreadsheets, as well as unstructured data, such as text and images. This adaptability allows for meaningful analysis and insight extraction across various formats.
What is the role of data ethics here?
Data ethics is essential for ensuring the fair, transparent, and responsible use of information. It helps prevent bias, discrimination, and misuse. Establishing ethical guidelines safeguards privacy, upholds societal values, and promotes the responsible development and deployment of these systems across applications.
What makes data science algorithms so versatile?
In this discipline, logistic regression serves as a foundational, single-layer method, while neural networks use complex, multi-layered architectures to uncover intricate patterns and relationships. Spanning everything from a single regression line to deep networks, the field keeps reinventing how machine learning turns data into predictions and decisions.


%20(1).webp)







