AI Ethics, Strategy & Applied AI Concepts
AI Ethics
Definition: AI Ethics is the branch of applied ethics that addresses the moral questions surrounding the design, development, and deployment of artificial intelligence systems. It provides the principles and frameworks businesses use to ensure that AI acts fairly, transparently, and in alignment with human values and societal well-being.
For organizations, this translates into practical governance: who is accountable when an AI makes a wrong decision, how is personal data protected, and how do we prevent automated systems from discriminating against individuals or groups?
Technical Insight: AI Ethics encompasses multiple sub-disciplines: Fairness (ensuring equal treatment across demographic groups), Accountability (traceability of decisions), Transparency (model explainability), and Privacy (data minimization, consent). Operationalizing ethics requires tooling like model cards, datasheets for datasets, and bias audits integrated into the MLOps pipeline before and after deployment.
Ethics in AI
Definition: Ethics in AI refers to the active practice of embedding ethical considerations throughout every stage of an AI project lifecycle — from problem framing and data collection, through model training, to deployment and monitoring. While 'AI Ethics' describes the field, 'Ethics in AI' describes the doing: the specific policies, checklists, and review processes an organization implements.
This is increasingly a regulatory necessity, not just a moral choice, especially under frameworks like the EU AI Act, which mandates risk assessments for high-risk AI applications in healthcare, credit, and hiring.
Technical Insight: Practically, Ethics in AI is implemented through structured processes: ethical impact assessments at the project start, adversarial testing for harmful outputs, human-in-the-loop (HITL) review for high-stakes decisions, and continuous post-deployment monitoring for distributional drift and disparate impact across protected groups. Red-teaming exercises are also used to proactively find failure modes before launch.
Explainable AI (XAI)
Definition: Explainable AI (XAI) refers to methods and techniques that make the outputs and decisions of artificial intelligence models understandable to humans. As AI models — particularly deep learning systems — grow more powerful, they become 'black boxes': they produce accurate predictions but cannot explain why. XAI solves this problem.
In regulated industries like banking (credit scoring) and healthcare (diagnostic tools), explainability is legally required. A customer denied a loan must receive a human-readable explanation, not just an algorithmic decision.
Technical Insight: Leading XAI techniques include LIME (Local Interpretable Model-agnostic Explanations), which approximates a complex model locally with a simple one, and SHAP (SHapley Additive exPlanations), which assigns each feature a contribution value using cooperative game theory. Attention visualization is used for Transformer-based models. XAI approaches are categorized as global (explaining the overall model behavior) or local (explaining a single prediction).
Bias in AI
Definition: Bias in AI refers to systematic and unfair errors in an AI model's outputs, which result in discriminatory or skewed outcomes for certain groups of people. Bias most commonly enters through training data that reflects historical human prejudices — for example, a hiring algorithm trained on past decisions may learn to penalize CVs from women if the historical data showed fewer women being hired.
Unchecked AI bias creates serious legal, reputational, and ethical risks for businesses deploying these systems at scale.
Technical Insight: Bias is categorized by origin: Data Bias (unrepresentative or historically skewed training datasets), Algorithmic Bias (the model's objective function optimizing in ways that create disparate outcomes), and Measurement Bias (flawed proxies used as targets). Mitigation techniques occur at three stages — pre-processing (resampling, re-weighting data), in-processing (fairness constraints in the loss function), and post-processing (adjusting decision thresholds per demographic group). Metrics like Demographic Parity, Equalized Odds, and Individual Fairness quantify it.
AutoML
Definition: AutoML (Automated Machine Learning) is the process of automating the end-to-end pipeline of building and applying machine learning models. Instead of requiring a data scientist to manually select algorithms, engineer features, and tune hyperparameters, AutoML tools perform these steps automatically, making ML accessible to teams without deep ML expertise.
For businesses, AutoML dramatically shortens the time-to-deployment of ML solutions — what used to take months of expert iteration can be reduced to days for standard problems like churn prediction or sales forecasting.
Technical Insight: AutoML automates three key steps: Feature Engineering (creating input variables from raw data), Neural Architecture Search (NAS) or Algorithm Selection (choosing the best model type), and Hyperparameter Optimization (using techniques like Bayesian Optimization or evolutionary algorithms). Platforms like Google Cloud AutoML, H2O.ai, and AutoGluon handle the full pipeline. The main limitation is that AutoML excels on tabular data but struggles with highly novel or domain-specific problems requiring bespoke architectures.

Named Entity Recognition (NER)
Definition: Named Entity Recognition (NER) is a Natural Language Processing (NLP) task that identifies and classifies named entities within unstructured text into predefined categories — such as persons, organizations, locations, dates, monetary values, and products. It is a foundational technique for transforming raw text into structured, actionable data.
Business applications include extracting company names from news articles for competitive intelligence, pulling contract dates from legal documents automatically, and tagging products in customer reviews.
Technical Insight: Modern NER systems use transformer-based architectures (like BERT fine-tuned for token classification), where each token in a sequence is assigned an entity label using the BIO (Beginning, Inside, Outside) tagging scheme. Earlier approaches relied on CRF (Conditional Random Fields) and rule-based systems. NER performance is typically measured by F1-score across entity categories. Domain-specific NER (e.g., biomedical for gene/protein names) requires fine-tuning on specialized corpora.
Sentiment Analysis
Definition: Sentiment Analysis (also called Opinion Mining) is an NLP technique that automatically identifies and extracts the emotional tone — positive, negative, or neutral — expressed in a piece of text. It converts qualitative human opinions into quantifiable data that businesses can act upon.
Practical uses include monitoring brand perception across social media in real time, analyzing customer support ticket sentiment to prioritize urgent cases, and aggregating product review sentiment to guide product development decisions.
Technical Insight: Sentiment analysis ranges in granularity: document-level (overall tone of a review), sentence-level, and aspect-based (e.g., 'the battery life is poor but the screen is excellent'). Deep learning models, especially fine-tuned BERT-family transformers, significantly outperform lexicon-based approaches. Key challenges include handling sarcasm, domain-specific language, and multilingual content. Outputs can be binary, multi-class (e.g., 1–5 stars), or continuous sentiment scores.
Anomaly Detection
Definition: Anomaly Detection is a machine learning technique that identifies data points, patterns, or behaviors that deviate significantly from the established norm. These deviations — called anomalies or outliers — often signal a critical event requiring investigation: a fraudulent transaction, a server about to fail, or unusual manufacturing defects on a production line.
It is a cornerstone of proactive operations, allowing organizations to detect threats or failures automatically before they escalate into costly problems.
Technical Insight: Anomaly detection approaches span three paradigms: Supervised (requires labeled normal vs. anomalous examples — rare in practice), Unsupervised (e.g., Isolation Forest, Autoencoders, One-Class SVM — learns what 'normal' looks like and flags deviations), and Semi-supervised. Time-series anomaly detection often uses LSTM networks or statistical models like ARIMA. A key challenge is class imbalance — anomalies are inherently rare, making precision/recall tradeoffs central to system design.
Natural Language Processing (NLP)
Definition: Natural Language Processing (NLP) is the field of AI that enables computers to understand, interpret, and generate human language — whether written or spoken. It is the technology powering chatbots, virtual assistants, search engines, machine translation, and document summarization tools.
For businesses, NLP is the bridge between unstructured human language (which makes up over 80% of enterprise data) and structured systems that can act on that information — unlocking value trapped in emails, contracts, support tickets, and reports.
Technical Insight: The NLP pipeline typically involves Tokenization, Part-of-Speech (POS) Tagging, Dependency Parsing, Named Entity Recognition, and downstream tasks like classification or generation. The field was transformed by the Transformer architecture (2017) and pre-trained language models (BERT, GPT family), which learn rich contextual representations from massive text corpora. Core NLP tasks include Machine Translation, Text Summarization, Question Answering, and Information Extraction. Evaluation uses benchmarks like GLUE, SuperGLUE, and SQuAD.


AI Strategy, Ethics & Applied AI: Responsible Intelligence in Practice

Share
Table of contents:
80%+ Reduction in Manual Job Data Handling Using an AI Platform
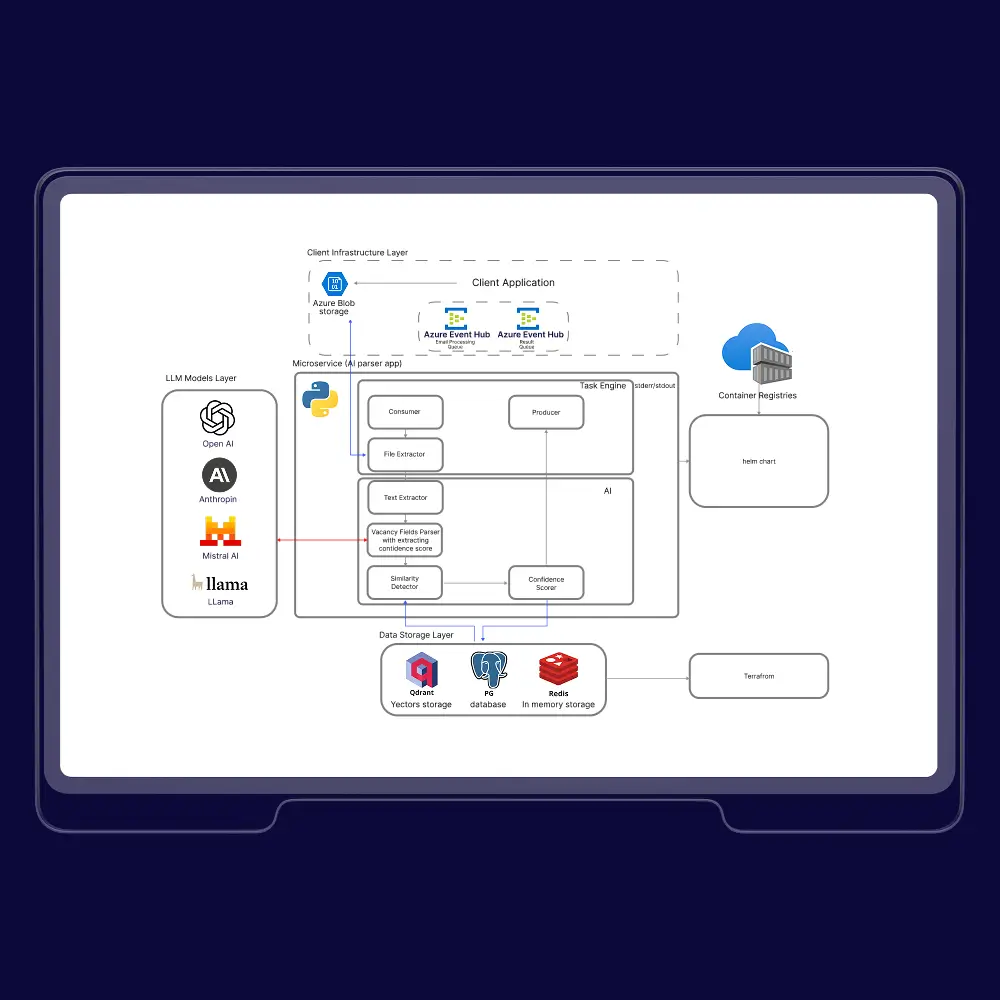

Cut Manual Data processing with an AI Platform
Real-Time AI Voice Agent for Cold Calling
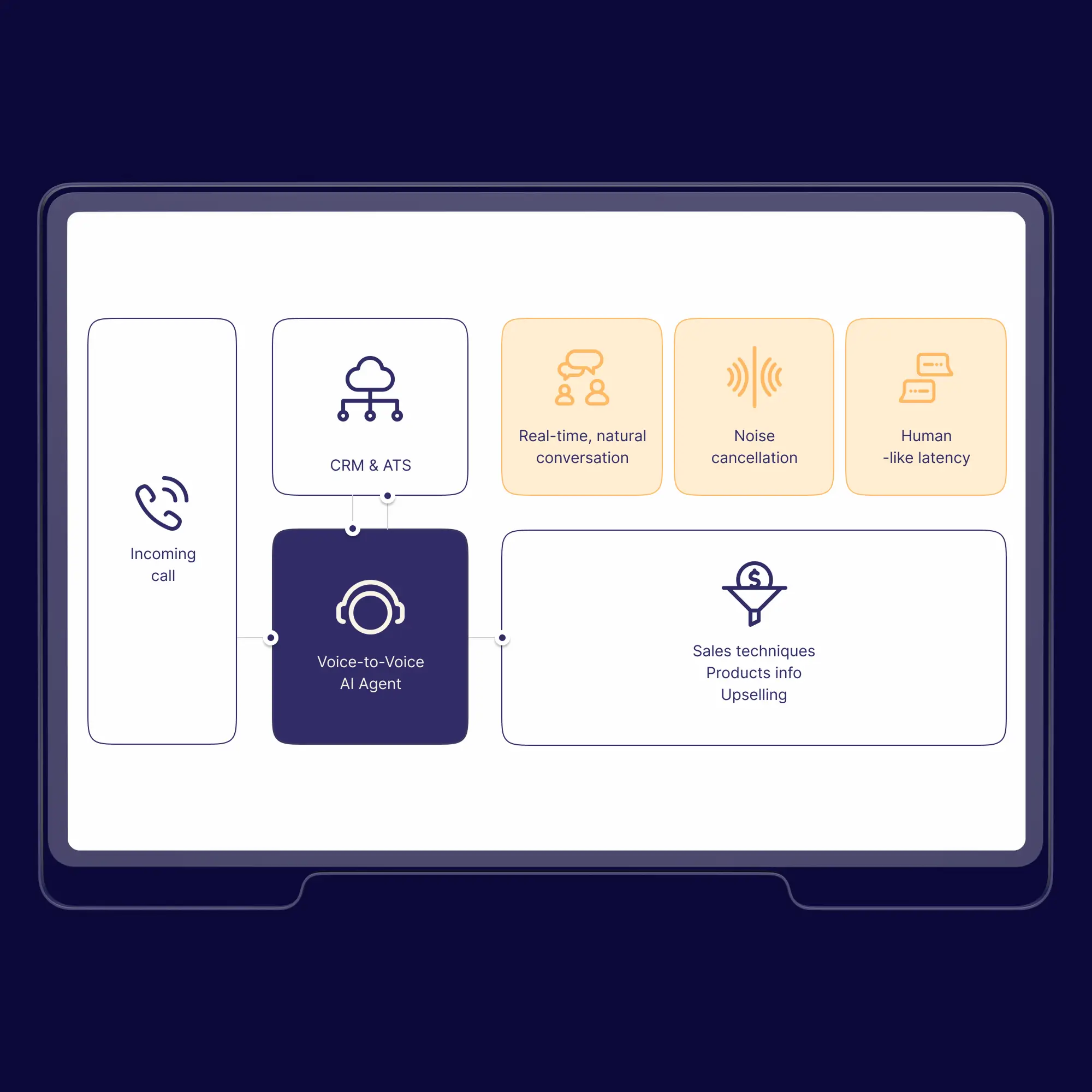
AI-Powered Cold Calling: Real-Time Voice-to-Voice Conversations
80%+ Reduction in Manual Job Data Handling Using an AI Platform
Cut Manual Data processing with an AI Platform
Latest publications
All publications
Generative AI in Social Media: You're Great! But Is It Really You?
.webp)
AI in IT: Proactive Decision-Making in a Technology Infrastructure
