

There has been a wholesale change in the narrative around enterprise data. Executives have spent the last 10 years accumulating huge amounts of data, building huge data lakes, and treating storage as the gold standard. Today, that paradigm is obsolete. In 2026, raw data becomes a differentiator only if it is interwoven, governed, and operationalized.
From depositing data passively to implementing AI actively, the foundation of this journey lies solely in solid big data integration tools. In the absence of an integrated data pipeline architecture, machine learning models starve, predictive analytics collapse, and operational silos harden. This executive guide goes under the hood of how a new breed of on-trend big data integration software acts as the enterprise’s central nervous system in the era of modern AI and outlines strategic selection, architectural best practices, and the ROI impact of getting integration right.
The Extreme Value of Big Data Integration and What It Means at the Board Level
Data integration is no longer an IT operational challenge alone; it’s a strategic issue tabled in the boardroom. An organization’s inability to unify its disparate data sources is a fundamental barrier to its execution of digital transformation.
Moving from Data Collection to Data Orchestration
Traditionally, data in enterprises was ingested and dropped into static repositories by rudimentary data ingestion tools, reshuffling the focus to data orchestration tools. This evolution marked a pivot from collecting everything to connecting everything. Real-time data synchronization, continuous governance, and automation of workflows alike are the must-haves of modern enterprise data architecture that simply bring datasets contextualized at the BI/AI layer where they now live.
Leaders understand that the gateway to intelligent automation lies in integrated data, which is the process of consolidating disparate data flows—ranging from on-premise mainframes to multi-cloud settings—into a single, accurate source of truth.
The High Price of Poor Data Integration
The costs for broken data ecosystems are massive. A widely referenced Gartner report estimates that poor data quality costs the typical enterprise roughly $12.9 million each year. But the real cost goes far beyond direct financial loss:
- Foiled Time-to-Market: Dev teams end up hunting down reports for weeks instead of building solutions
- Wrecked AI Projects: Large language models driven by patchy, unverified information create fanciful narratives and defective predictions.
- Compliance Risks: A lack of tracking the data lineage across the hybrid integration landscape creates a high risk of massive regulatory fines.
Competitive Advantage – Data Integration
In contrast, mature data consolidation platforms let you move with unparalleled speed. When the right big data integration tool is deployed by an enterprise, it holds the power to:
- 360-Degree Customer Views: Merging CRM, transactional, and behavioral data to personalize customer journeys at scale.
- Operational Resilience: Integrating real-time data to track supply chains, anticipate bottlenecks, and pivot in the moment.
- Accelerated innovation: Provide data scientists with an AI-ready data infrastructure to focus on writing the algorithm instead of manually wrangling.
McKinsey’s research on the “data-driven enterprise” has found that the companies that see significant EBIT contributions from AI are those that focus on integrated, accessible data practices. It is the ultimate differentiator.
Big data integration tools must be evaluated based on the size, volume, and variety of the data. To understand the landscape, one must look beyond marketing flights of fancy and into the functional reality of these platforms.
Definition and Core Capabilities
At heart, big data integration tools are dedicated software solutions that extract data from many sources, transform it into a common format, and load it into one destination (such as a data warehouse or data lake).
A suite of modern big data integration software provides various core capabilities:
- Connectivity: Out-of-the-box connectors for hundreds of SaaS apps, legacy databases, and cloud platforms.
- Transformation: Sophisticated data transformation tooling that cleanses, aggregates, and normalizes data in transit or at rest.
- Scalability: Distributed data processing engines that can work with petabytes of data without sacrificing performance.
- Governance: Auditing, masking, and lineage tracking as native capabilities to meet compliance.

Key Differences Between Traditional ETL and Modern Cloud-Native Data Integration
The past ETL (Extract, Transform, and Load) model was batch-based and required strict reliance on on-premises hardware. It was slow, fragile, and hard to scale.
Modern cloud-native data platforms work with an ELT (Extract, Load, Transform) flow. They first load raw data and then transform it within the destination. This solution for scalable data integration radically decreases processing time, can ingest unstructured data as is, and has native support for real-time streaming.
Main Types of Big Data Integration Tools
The vendor landscape is vast, but broadly speaking, solutions can be divided into the five categories below. Choosing the right fit greatly depends on an enterprise’s unique data modernization strategy.
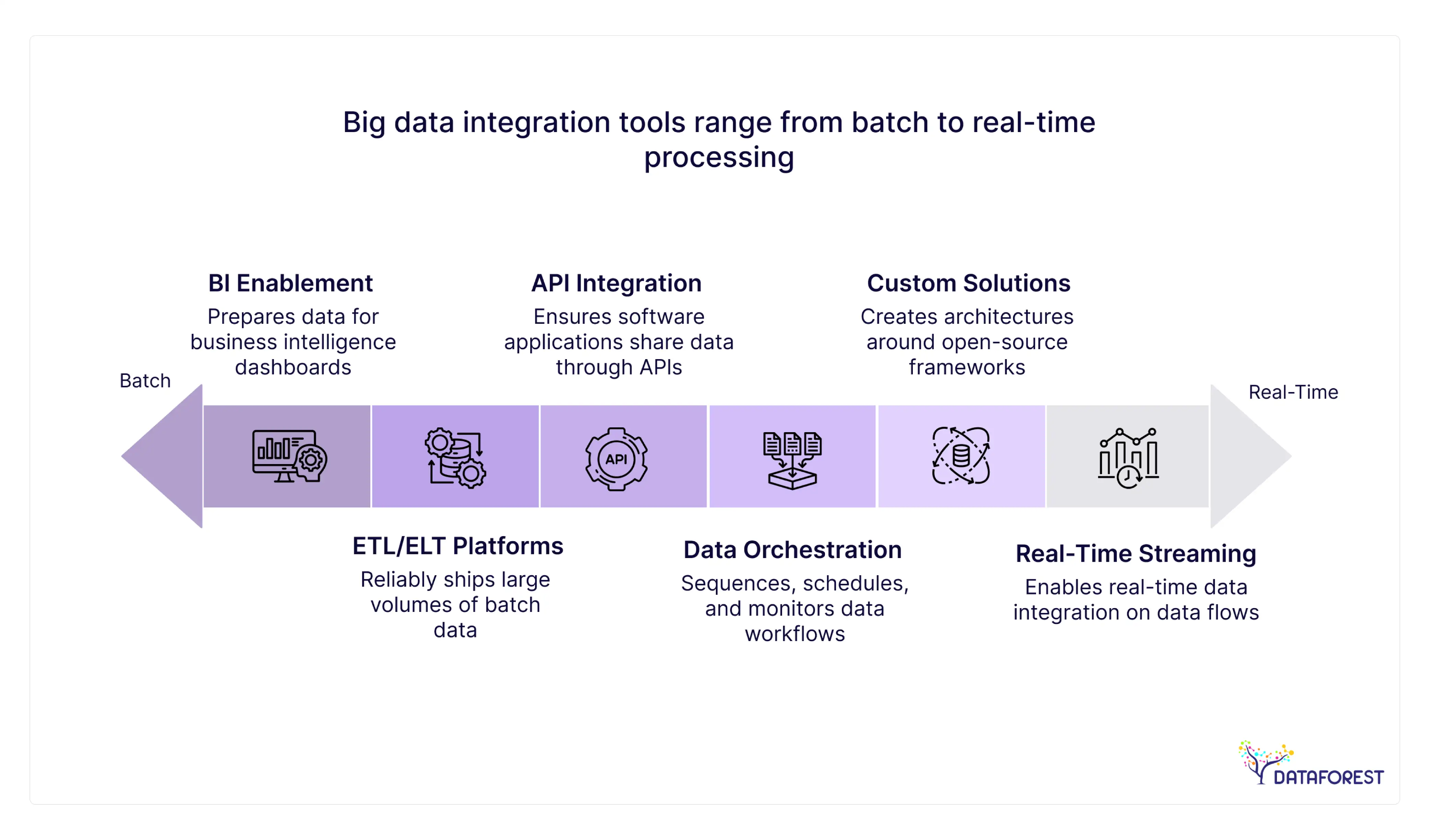
ETL / ELT Platforms
These are the workhorses of enterprise data integration. Platforms like Talend, Informatica, and more recent cloud-native solutions such as Fivetran and dbt specialize in reliably shipping large volumes of batch data. They offer an excellent way to synchronize CRM data, balance sheets, and other operational metrics into a single repository for historical analysis.
BI and Reporting Enablement
A key subset of ETL/ELT functionality is the preparation of data for business intelligence. Enterprise data synchronization solutions offer the same: clean, latency-free data streaming into BI dashboards. A financial company, for instance, needs a robust reporting solution where data modeling has to be absolutely stringent so that C-level executives can make decisions based on the absolute truth and nothing but approximated estimates.
Real-Time Data Streaming Platforms
Batch processing isn't enough when milliseconds count. Platforms such as Apache Kafka and Confluent enable real-time data integration. They operate on data flows, so businesses can respond in real-time (e.g., a fraud alert from fintech or dynamic pricing from e-commerce) to event streams.
API & Application Integration Platforms
Commonly referred to as Integration Platform as a Service (iPaaS), tools like MuleSoft and Boomi emphasize software applications sharing data through APIs. These are not about transferring huge data volumes but rather ensuring that an update from Salesforce can immediately be spotted in a custom ERP system. For more on this, check out DATAFOREST's analysis of what an API-based data integration solution looks like.
Data Orchestration & Workflow Tools
These systems (e.g., Apache Airflow, Dagster) become the air traffic controllers for your automated data workflows. They don’t move the data themselves — they just sequence, schedule, and monitor the various data-loaded tools and transformation scripts to make sure all parts of a pipeline run properly and alert engineers if anything fails.Relying solely on alerts often means reacting to problems rather than preventing them; a comprehensive strategy for data pipeline monitoring and observability provides the deep insights necessary to proactively identify anomalies, predict failures, and maintain the integrity of these complex data workflows.
Custom-Built Data Integration Solutions
Off-the-shelf software is often inadequate for enterprises with highly specialized, proprietary, or deeply complex ecosystems. In these cases, engineering teams create their own architectures around open-source frameworks, Python, and cloud-native microservices. This allows for complete control over performance, security, and integration logic.

How to Select the Best Big Data Integration Tool
Choosing an enterprise-grade platform is a 5- to 10-year decision for your IT roadmap. It demands a persistent and multidimensional assessment.
Aligning with Business Objectives
Begin with the end in mind. Are you optimizing for real-time customer analytics, or are you trying to consolidate legacy systems after a merger?
If your goal is to BI-enable everything quickly, the best approach is a cloud data integration tool that takes care of any schema drift without you ever knowing it occurred.
If advanced analytics or ML capabilities are your end goal, you should select tools that specialize in distributed data processing and integrate ML pipelines.
Technical Considerations
The next step is to evaluate the platforms against your current and future tech stack. Key criteria include:
- Connector Ecosystem: Are your specific ERP, CRM, and homegrown cloud apps natively supported?
- Throughput & Latency: Will it support the peak amounts of data that you want to throw at it?
- Security: Field-level encryption, role-based access control, GDPR/CCPA compliant?
Organizational Readiness
No matter how innovative the big data integration is, if your team cannot run it, it fails. Evaluate the technical expertise of your data engineering team. Low-code/no-code platforms democratize the space and give data analysts more power, but hardcore engineers may get annoyed with limited control at a granular code level. Top data engineering companies can fill this capability gap during deployment.
Building vs Buying: When Off-the-Shelf Tools Are Insufficient
The enterprise IT strategy of whether to build vs. buy is the age-old question. Although standard platforms have quickly evolved, they are not a silver bullet.
Limitations of Out-of-the-Box Platforms
Off-the-shelf platforms for data integration often do a poor job of:
- Niche Legacy Systems: No connectors to highly specific homebrewed, decades-old mainframes.
- Unstructured data: Breakdown of analysis on complex, multi-dimensional JSONs, sound or tone (music, voice, noise), and video files that are becoming imperative for cutting-edge AI
- Vendor Lock-In: Squeezed pricing models based on the quantity of data, which could take all the available budget as the enterprise grows
Advantages of Custom Data Integration Architecture
For very specialized workflows, building a custom solution might be the best option with unparalleled strategic advantages. A custom data pipeline architecture will guarantee:
- Absolute Performance Tuning: Tailoring compute resources to hit the mark for your data loads.
- Intrinsically Vendor-Less: Avoid vendor lock-in by relying on open standards such as SQL with both native-style and code-less builders.
- Cost Predictability: Breaking Free From Volume-Based SaaS Pricing Models Exponential Cost Curves
Hybrid: Combining the Two Approaches
A hybrid approach is what most Fortune 500 companies take towards data integration. They “buy” standard ELT tools for commodity data (e.g., moving Salesforce to Snowflake) and “build” custom microservices for their core, competitive-advantage data streams. It strikes a balance between speed-to-market and specialized performance.

Enterprise Data Integration: Architecture Best Practices
No tool can be more than its architecture. As a data consolidation platform, the expectations are high, and adherence to engineering principles is paramount.
Designing a Scalable Data Architecture
Scalability needs to be designed in from the first day. Using decoupled architectures allows compute and storage to scale independently. Consider a data mesh or data fabric approach to allow different business domains to own their data products, while ensuring compliance with centralized integration standards.
Data Governance, Security & Compliance by Default
Security cannot be an afterthought. Establish automated data integration processes to remove PII as the data is ingested. Use strong metadata management to create complete data lineage—enabling auditors to follow the path of a BI dashboard back through data sources and all the way up to its origin.
AI-Ready Data Pipelines
Pipelines need to be “AI-ready” in order to fully harness the power of AI-driven digital transformation. This basically means getting over mere structural transformation and adding the capabilities of feature engineering at the data stream itself. Feature stores leverage automated data flows that continuously deliver clean, normalized, and contextualized data to your machine learning models.
Industry Use Cases
Deployment of a big data integration kit is wildly different depending on the sector’s regulatory climate and operational tempo.
Fintech & Financial Services
Data integration in finance is a matter of risk management and instantaneous fraud detection. By aggregating transaction logs, credit histories, and behavioral data, financial institutions can deploy AI models that identify anomalies in milliseconds. In addition, secure data lake integration guarantees compliance with rigorous reporting standards such as Basel III. Learn more about DATAFOREST client identification work in finance.
Retail & E-commerce
Retailers vying for consumer attention need supply chain efficiency. Combining point-of-sale data, stock levels, and e-commerce analytics leads to dynamic pricing and super-targeted marketing. E-commerce scraping directly into internal forecasting models is often a key piece here.
Utilities & IoT
The problem for energy and manufacturing is volume and velocity. For instance, millions of IoT sensors on smart grids or factory floors emit continuous telemetry. Advanced data synchronization solutions ingest this unstructured time-series data and layer it with maintenance schedules to identify assets at risk of failure before the event, leading to significantly reduced downtime.
SaaS & Digital Platforms
Integration powers user experiences and internal back office automation at digital-first companies. Seamless API integrations by SaaS platforms can embed analytics, synchronize user permissions across microservices, and keep the ecosystem of products responsive.
Medical Lab Achieves 50% Compute Savings via Databricks Migration
.webp)

Medical Lab Achieves 50% Compute Savings via Databricks Migration
Partnering with a Strategic Data Partner to Accelerate Results
Enterprise data integration is one of the most complex implementations. Over-dependence on internal teams means that there’s always legacy work, and technical debt grows. Engaging a specialized consultancy such as DATAFOREST accelerates time to value.
Everything from Tool Selection to End-to-End Architecture
A partner does not just install software; they advanced analytics. Use Case 1: DATAFOREST consultants review your current build environment, help you choose the best big data integration software for your needs, and create a robust and future-proof topology to strategize for your business.
Custom AI & ML Integration
Normal integrators only combine data. As the Data Science and Generative AI leaders, DATAFOREST guarantees that your pipelines are built for a specific purpose to support intricate models. Be it embedding foundation models for enterprise innovation or spinning up a real-time AI voice agent for cold calling, the data foundation is built for advanced analytics.
Web Scraping & Enrichment of External Data
Sometimes, you have to go beyond internal data. DATAFOREST specializes in scraping data, building custom integrations that feed immense chunks of alternative external datasets (market trends, competitor statistics, public sentiment), and combining them cleanly with your internal dataset to provide you with an analytical advantage on a whole new level.
Full Digital Transformation Execution
DATAFOREST delivers end-to-end execution with everything from custom software development to complex web applications. Your solution is the catalyst for a holistic transformation throughout your enterprise.

How to Implement Big Data Integration in the Enterprise
A phased, disciplined approach is necessary for success. It is not about the “big bang” implementation but rather taking many small steps towards faster value delivery.
Phase 1: Data Audit & Approach
Just like with taking pictures, you probably start by mapping the landscape as it currently is. Identify data silos, evaluate the quality of existing datasets, and define business use cases that will offer the highest immediate ROI. Create an explicit data-driven transformation mandate with executive sponsorship.
Phase 2: Architecture Design
Design the blueprint. Vote on cloud or hybrid models, batch or streaming needs, and set high-level security and governance frameworks. This phase establishes for you the determining factor of whether you need a barn door wide open data lake integration or a locked-down, intricate, inside-the-hall-closet data warehouse integration.
Phase 3: Tool Selection & Pilot
Evaluate vendors based on the architecture. Pilot the selected big data integration tool on a well-defined, high-value, low-risk use case (for example, marketing analytics consolidation). This demonstrates technical viability and captures early stakeholder buy-in.
Phase 4: Scaling & Optimization
After the pilot, start the gradual migration of essential data workloads. You’ll automate data workflows and build processes to rigorously monitor the health of your pipelines, while also iterating on optimizing compute costs as your volume of data increases.
Phase 5: Continue AI Enablement & Improvement
Once a unified, clean data foundation is established, look up. Start implementing machine learning models, adding generative AI capabilities, and moving the enterprise from descriptive analytics to prescriptive, AI-based foresight.
The Future of Enterprise Data
The data within not just your enterprise but your entire enterprise ecosystem (including users, partners, and consumers) will become more complex as we head into 2026 and beyond. With the rise of AI, edge computing, and multi-cloud environments, data integration is sure to remain the number one technical challenge for the C-suite.
Investing in the right big data integration tools today isn't just for organizing information; it's also about laying the groundwork to endure tomorrow. Organizations that conquer their data pipelining will have hyper-agility, out-innovate competitors, and convert raw data into the strongest possible strategic weapon. Those who won’t integrate will just get kicked to the curb.
Are you ready to construct the data future of your enterprise? Schedule a consultation with DATAFOREST's principal architects to discuss your specific integration challenges via our contact form.
FAQ
How do tools for integrating big data affect the ROI of an enterprise?
Big data integration tools have a direct impact on ROI because they reduce manual engineering efforts required for data preparation, speed up the time-to-market for new BI and AI initiatives, and eliminate massive financial penalties due to poor data quality (which Gartner estimates at almost $12.9M per year in average enterprises). When we make one source of truth, these tools accelerate optimized supply chains, targeted marketing, and data-enabled transformation.
How can big data integration software power your AI and machine learning projects?
AI is inherently based on clean, contextualized data. The delivery mechanism is provided by big data integration platforms that help automate the extraction, cleansing, and formatting of scattered sources. It guarantees the flow of high-fidelity information to machine learning data pipelines, ultimately curtailing model drift, minimizing hallucinations, and finally building an AI-ready data infrastructure.
When should an enterprise build a custom data integration architecture rather than buy off-the-shelf tools?
Enterprise customers should consider custom solutions if they are dealing with hyper-proprietary legacy systems that do not have standard connectors, highly complex unstructured data (such as specialized IoT telemetry or video), or when the volume-based pricing of standardized SaaS becomes financially intolerable. A hybrid approach, buying for commodity data and building for core IP, is often the enterprise data architecture sweet spot.
The 5 biggest risks of using big data integration tools without having a proper data strategy in place?
Deploying without a strategy leads to “garbage in, garbage out” faster. These risks include replicating existing data quality problems, overspending on cloud compute by not optimizing transformations, failing to establish senior executive buy-in, or creating a complex and hard-to-maintain data pipeline architecture. Planning is critical; we need to set out a strategic roadmap and have it drive the software procurement process and data audit.
How Big Data Integration Tools Remove Data Silos Across Departments?
Leveraging large connector libraries and viable data orchestration features, these platforms pull in data automatically from siloed department systems (ex, Marketing's HubSpot, Finance's SAP, Sales' Salesforce). By passing this data into a centralized data consolidation platform (think cloud warehouse), they can stamp out departmental silos and generate cross-functional visibility.
Which Industries Should Invest In Advanced Big Data Integration Tools?
Although all sectors benefit, data-intensive industries have the most immediate impact. Fintech uses it for real-time fraud detection; retail applies it to dynamic pricing and inventory management; manufacturing taps into IoT-enabled predictive maintenance; and healthcare implements AI-powered integration of data to centralize patient records, while still adhering closely to HIPAA. Find out more about particular industry use cases on the DATAFOREST industry page.


.webp)







