

A regional retail chain operated more than 120 stores and stored sales, inventory, and supplier data in separate systems. Engineers built automated integration pipelines that collected records from point-of-sale databases, warehouse systems, and supplier APIs every hour. The pipelines loaded cleaned tables into a centralized analytics platform used by finance, logistics, and store managers. Daily reports that once required several hours of manual work now appear each morning with current numbers, thanks to automated data integration. If you are interested in this type of digital transformation, please request a call.
.webp)
Why Is Automated Data Integration Critical in 2026?
Poor data integration forces organizations to collect and process records from different systems. Engineers spend hours translating files, resolving schema conflicts, and adding tables before analysis begins. Business leaders then receive reports that arrive late and often have conflicting scores. The problem will be even worse in 2026 when companies run multiple SaaS platforms, cloud databases, and event streams. Automated data integration eliminates that conflict and provides reliable information for daily operations and AI models.
Connected platforms allow leaders to respond to market shifts in real time. Executives rely on accurate figures to track revenue, manage supply chains, and guide investment plans. Teams must build automated pipelines to move high-quality records from the edge to the warehouse. Fragmented silos slow down decision-makers and increase technical debt. Automation eliminates manual errors to ensure that every model delivers accurate predictions for the business.
U.S. Manufacturer Unifies Enterprise Data, Cuts Manual Work 80–90%
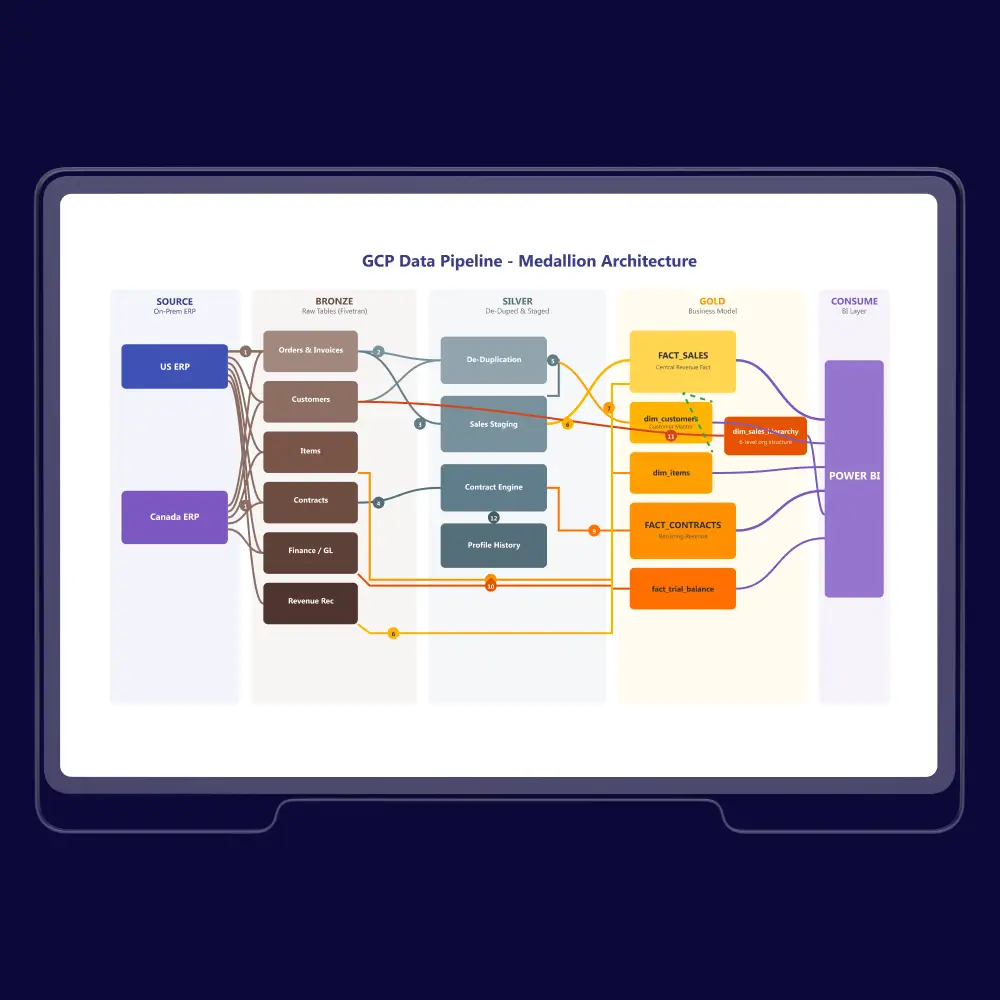

Enterprise Data Platform with Medallion Architecture
How Does Automated Data Integration Accelerate the Enterprise?
Automated data integration systems deliver high-quality records to every production model for the business. Teams reduce technical debt by building scalable pipelines that synchronize info across the global cluster. Leaders achieve faster deployment cycles and improved record accuracy through a unified platform.
Manually adding new operations slows down
Manual integration allows engineers to manually download files, map fields, and add data. Each new data source introduces documents, spreadsheets, and workflows that break down under system changes. Organizations spend most of their time managing pipelines instead of building analytics products. Reports are slow to arrive and often have different numbers between departments. In 2026, the proliferation of SaaS tools, cloud platforms, and streaming data will make manual integration untenable for enterprise systems.
Automation drives results
- Consolidation of cut store records → Reduce processing delays.
- Enable automatic API authentication → Improve record accuracy.
- View work pipelines → Detect defects before they hit the dashboard.
- Increase the amount of data → Provide real-time metrics to each organization.
- Automatic management of data structure → Reduce the operational burden through automated data integration.
Systems scale faster with automation
Leaders must deploy automated API integration services to detect failures before they stop production. Teams reduce technical debt by moving away from legacy scripts. These automated data integration systems ensure that every database stays synchronized across the global cluster.
Choose what is important to you and order a call to explore automated data integration.
What Components Make for Effective Automated Data Integration?
Modern businesses can rely on automated pipelines to move statistics between multiple systems every day. Integration fields, connectors, transformation engines, and control constraints form the basis of these pipelines. Together, these components transform scattered business records into a reliable feed for analytics and AI systems.
Platforms that run integration pipelines
Automated data integration platforms connect operational systems, cloud services, and databases through standardized connectors. These tools schedule pipelines that extract, transform, and load records into a centralized platform. Monitoring dashboards track pipeline status, data volume, and error events in real time. A reliable platform turns dozens of disconnected sources into a steady flow of analytics-ready datasets.
Interfaces that connect sources
Connectors and adapters link enterprise platforms, SaaS tools, and databases to integration pipelines. APIs allow systems to exchange records through structured requests and responses. Standard interfaces reduce the need for custom scripts and manual data extraction. A strong connector layer allows integration platforms to collect info from many systems with stable and repeatable processes, speeding up efforts to automate data integration.
Engines convert raw records
Transformation engines convert messy records into structured formats for the business as part of automated data integration workflows. These systems clean information before it reaches the warehouse to reduce technical debt. Reliable processing delivers high-quality fuel for accurate predictions to every production model. Teams use these engines to automate the flow of facts across the entire cluster.
Systems protect the records
Data governance frameworks define how teams access and manage information within the warehouse. Automated security protocols detect unauthorized access attempts across every connected API. Leaders must build strict controls to ensure that sensitive database records remain compliant. Secure systems reduce risk while allowing teams to scale operations safely across the global cluster.
How Can Leaders Build Scalable Data Integration?
Strategic alignment ensures that every API call within automated data integration delivers value to the bottom line. Engineers must build cloud-native pipelines to handle increasing record volumes across the global cluster. Automated monitoring protects the warehouse by detecting silent errors before they reach the dashboard.
Teams must connect systems to goals
Leaders align technical pipelines with corporate objectives to ensure that every API call adds value. This synchronization prevents engineering teams from building isolated features that do not impact the bottom line. For example, strategic alignment allows the warehouse to deliver insights that directly reduce operational costs or improve customer retention. Fragmented goals lead to wasted resources and a cluttered database environment. By focusing on business results, organizations can scale production models that solve real-world problems.
Evaluate sources before pipeline design
Organizations must review every source before connecting it to automated data integration pipelines. Teams examine schema structure, update frequency, ownership, and access controls across each system. For example, data profiling tools measure missing fields, duplicate records, and inconsistent identifiers. Engineers then rank sources by reliability and business value before building ingestion pipelines. This assessment step prevents weak sources from corrupting analytics tables and machine learning datasets.
Build for the future cluster
Cloud-native architectures allow teams to scale database resources instantly as record volumes increase. Many enterprises rely on a modern data architecture service to design scalable serverless pipelines that reduce infrastructure management and lower operational costs. For example, the shift ensures that every API remains responsive even during peak production loads. Static systems break when the business expands into new global markets. By migrating to the cloud, organizations deliver reliable data to every model across the enterprise.
Pipeline monitoring
Automated tracers show every record moving through automated data integration. Systems should detect API delays or errors before they impact the dashboard. Data consistency ensures that the database remains the same even as tables change over time. Manual checks don’t catch silent errors that can compromise long-term quality. Organizations investing in custom dashboard development can visualize pipeline health, monitor data quality metrics, and track operational KPIs through centralized executive dashboards that provide immediate visibility into integration performance. By building in early warnings, organizations can reduce downtime and provide reliable fuel for any business model.
Deloitte notes that integration platforms are evolving into AI-enabled decision engines. Automation improves speed, cost efficiency, and insight generation. Modern enterprises must modernize data architecture and governance simultaneously.
How Can Enterprises Overcome Data Integration Challenges?
Enterprises must unify fragmented records across a global cluster to maintain data accuracy. Automated pipelines connect legacy database systems to the cloud without disrupting stable production operations. These secure platforms reduce technical debt and allow teams to deliver clean facts to every warehouse.
Systems unify fragmented data
Modern enterprises must manage hundreds of unique record formats across a global cluster. Automated pipelines ingest structured and unstructured data to create a single truth in the warehouse. Leaders use these tools to connect diverse API sources without writing manual transformation scripts. Consistent records allow every production model to deliver accurate results for the business.
Connect modern platforms to legacy cores
Organizations struggle with legacy database systems that do not support modern API standards. Automated integration tools bridge this gap by creating a unified layer between old records and new cloud services. Teams use these platforms to extract info from on-premise silos without disrupting stable production operations. This compatibility allows leaders to modernize their warehouse architecture while maintaining existing business rules.
Organizations can master new systems
Organizations need to learn how to manage automated platforms instead of writing manual scripts for databases. Training programs bridge the gap between legacy engineering and modern pipeline design. Leaders foster a culture that relies on automated solutions rather than manual processes in the store. Good change management ensures that transitioning to an API-first architecture improves the organization's productivity.
Automation secures the enterprise
Automated protocols ensure that every record moving through the pipeline stays compliant with global regulations. Teams build encryption and access controls directly into the API to prevent unauthorized data leaks. This centralized approach allows leaders to monitor the entire cluster for potential security threats in real time. Secure systems reduce the risk of manual error and provide a clear audit trail for the database.

How Do Leaders Deliver Results with Automated Data?
Fragmented systems and manual workflows stop the growth of global organizations. Teams build automated pipelines to connect legacy database records to a central warehouse. These systems reduce downtime and improve record accuracy across every production cluster.
Factory data unification
Fragmented shop floor records prevented leadership from monitoring real-time production efficiency across the global cluster. Sensors and legacy machines used different protocols that could not communicate with the central database.
The team built automated pipelines to ingest raw signals directly into a unified cloud warehouse. This API-first architecture synchronized equipment logs with the supply chain management system.
Organizations reduced downtime by 22% by detecting equipment failures before they stopped the line.
Accurate records allowed the production model to optimize energy usage and lower operational costs.
Omni-channel inventory management
Siloed inventory systems have created permanent gaps between online stores and physical store accounts. Slow handovers delayed inventory notifications and left frustrated customers ordering products that were unavailable in many locations.
The company has built real-time pipelines to coordinate each task with a central database. This automated API class quickly connects point-of-sale systems to the cloud store to update records.
Inventory accuracy has improved to 99%, and the number of canceled orders has decreased. Managers now use real-time dashboards to monitor inventory levels and quickly ship products to customers thanks to real-time data integration and automated data transformation.
Global system integration
Divisions maintained separate data warehouse silos that prevented management from reviewing consolidated financial statements. Manual repair processes delayed quarterly closings and increased the risk of reporting errors in the store.
The company has announced automated pipelines to integrate records from every global company into a central platform. Engineering teams used an integrated API class to compare different types of data across the organization.
Budget closing times fell by 40% because companies no longer had to manually enter data. Managers have access to a real-time dashboard to monitor global performance and make quick strategic decisions.
Bain & Company flags that AI success depends more on data architecture than algorithms. Automated pipelines enable consistent data access across teams. Data governance and integration must be treated as strategic assets.

How Does DATAFOREST Accelerate Enterprise Data Automation?
DATAFOREST builds automated pipelines to unify fragmented records across complex global systems. Engineers deploy custom API layers to connect legacy database silos with modern cloud services. These systems automate data transformation to deliver clean facts directly to the executive warehouse. Automated validation checks catch errors before they impact the final dashboard or production model. Leaders use these integrated platforms to improve decision speed and reduce long-term technical debt.
Please complete the form to try the automated data integration benefits.
Questions on the Automated Data Integration
How can automated data integration improve decision-making for executives?
Automated pipelines deliver real-time records from fragmented silos directly to a unified executive warehouse. This system eliminates the manual delays and human errors that often corrupt high-level financial reports. Leaders use these clean facts to build accurate production models and make faster strategic decisions for the enterprise. Combining data quality management with data orchestration gives executives confidence in the numbers.
Which business processes benefit most from automating data integration?
Financial consolidation and supply chain monitoring benefit most by replacing manual reconciliation with automated pipelines. These systems synchronize fragmented database records to provide a single truth for real-time inventory and sales tracking. Leaders use this automated API layer to scale operations and deliver accurate facts to every executive's warehouse. Processes with heavy reconciliation tasks benefit from both ETL automation and dedicated master data management (MDM).
Can small or mid-sized companies implement automated data integration cost-effectively?
Small companies use low-code platforms and cloud-native connectors to automate pipelines with minimal initial investment. Serverless architectures allow these organizations to pay only for the records they process within the database. These systems reduce overhead by synchronizing information across every API without the need for a large engineering team. Tools that deliver accessible data integration automation and simplified data cleansing workflows make this possible.
How does automated data integration support AI and machine learning initiatives?
Automated pipelines synchronize massive volumes of raw records to provide a reliable foundation for training machine learning models. These systems detect and correct inconsistencies in real time to prevent corrupted facts from reaching the production cluster. Modern architectures use modular connectors to deliver high-quality context that autonomous AI agents need for accurate decision-making. Ensuring strong data quality management and leveraging AI-driven data integration pipelines accelerates model development and reduces bias.
How can automated integration help unify data across cloud and on-premise systems?
Automated integration connects local data centers to the cloud using encrypted tunnels and high-bandwidth network links to maintain secure data flow. Centralized management tools allow organizations to monitor systems and enforce policies across both environments through a single interface. These systems automate ongoing data synchronization to keep databases current while simplifying the migration of large record volumes. Hybrid approaches often combine on-premise connectors with cloud data integration and enterprise data consolidation patterns.
Which tools or platforms are most effective for large-scale automated integration?
Large enterprises deploy Informatica and IBM DataStage to manage complex data flows across global networks. Fivetran and Airbyte automate the movement of data from hundreds of sources into a central cloud warehouse. Cloud services like Azure Data Factory and AWS Glue allow teams to expand their systems without managing hardware. These platforms support both ETL automation and ELT pipelines while enabling full data integration and automation across the enterprise.


.webp)







