

A law firm builds RAG to pull from thousands of case files and legal precedents when drafting briefs. Instead of lawyers spending hours searching archives, the system finds relevant cases in seconds and feeds them to the LLM for analysis. If you think this is your case, then arrange a call.
Why Do LLMs Keep Making Things Up When You Need Them Most?
Forbes reports that hallucination rates remain a major issue in 2025, and in some cases, "reasoning" models can show higher rates of false confident outputs. LLMs hallucinate because they generate text based on patterns, not facts. When stakes are high and accuracy matters, these models will confidently state things that simply aren't true. The bigger problem isn't the hallucination itself—it's that you can't predict when it will happen or how badly it will derail your operations.
What Are Hallucinations in LLMs?
An LLM hallucination occurs when the model confidently states something that's simply incorrect. Maybe it invents a research study that never existed, or claims Shakespeare wrote a play called "The Merchant of Mars." The weird part is how convincing these false claims sound when you first hear them. What's going on under the hood is that these systems have learned to string words together based on examples, but nobody has taught them to verify if those words correspond to reality. It's a brilliant student who can write beautiful essays about topics they know nothing about—the writing flows perfectly, but the facts are entirely made up.
Why Hallucinations Are a Critical Concern for Enterprises
When your legal team asks an AI question-answering system about recent court rulings and receives citations to cases that never occurred, someone's going to have an awkward conversation with a judge. The absolute nightmare is that these hallucinations look exactly like good answers until you dig deeper and realize the whole foundation is imaginary. Finance departments have already learned this the hard way when models cheerfully invent market data or regulatory changes that sound entirely reasonable. Unlike a junior employee making mistakes, these systems don't show any uncertainty when they're completely wrong about something important. The scariest part might be how these false confident answers can ripple through an organization, influencing decisions and strategies based on information that simply doesn't exist.
How Hallucinations Affect Business Efficiency and Decision-Making
Picture this: your marketing team spends three weeks building a campaign around AI-generated competitor analysis, only to discover halfway through that two of the "key competitors" don't actually exist. Now multiply that scenario across departments—procurement teams chasing phantom suppliers, HR citing made-up employment laws, product managers planning features based on fake customer research. The efficiency hit is from all the downstream work that has to be unwound and redone. Decision-makers start developing what you might call "AI trust issues"—they either ignore valuable insights because they're paranoid about accuracy, or they double-check everything manually, which defeats the whole point of automation. What really hurts is when leadership makes strategic pivots based on compelling but fictional data points, burning months of resources before anyone realizes the foundation was never solid.
LLM-Powered Recommendation System
.webp)

LLM-Powered Recommendation System
How Does RAG in LLM Turn Unreliable AI Into the Most Trusted Assistant?
RAG in LLM doesn't improve LLM accuracy—it fundamentally changes how these systems work by providing them with access to current information, rather than relying solely on outdated training data. It's the difference between asking someone with a perfect memory from 2022 versus someone who can quickly look up today's facts before answering. The breakthrough is having an AI system that knows when to admit it needs to check its sources.
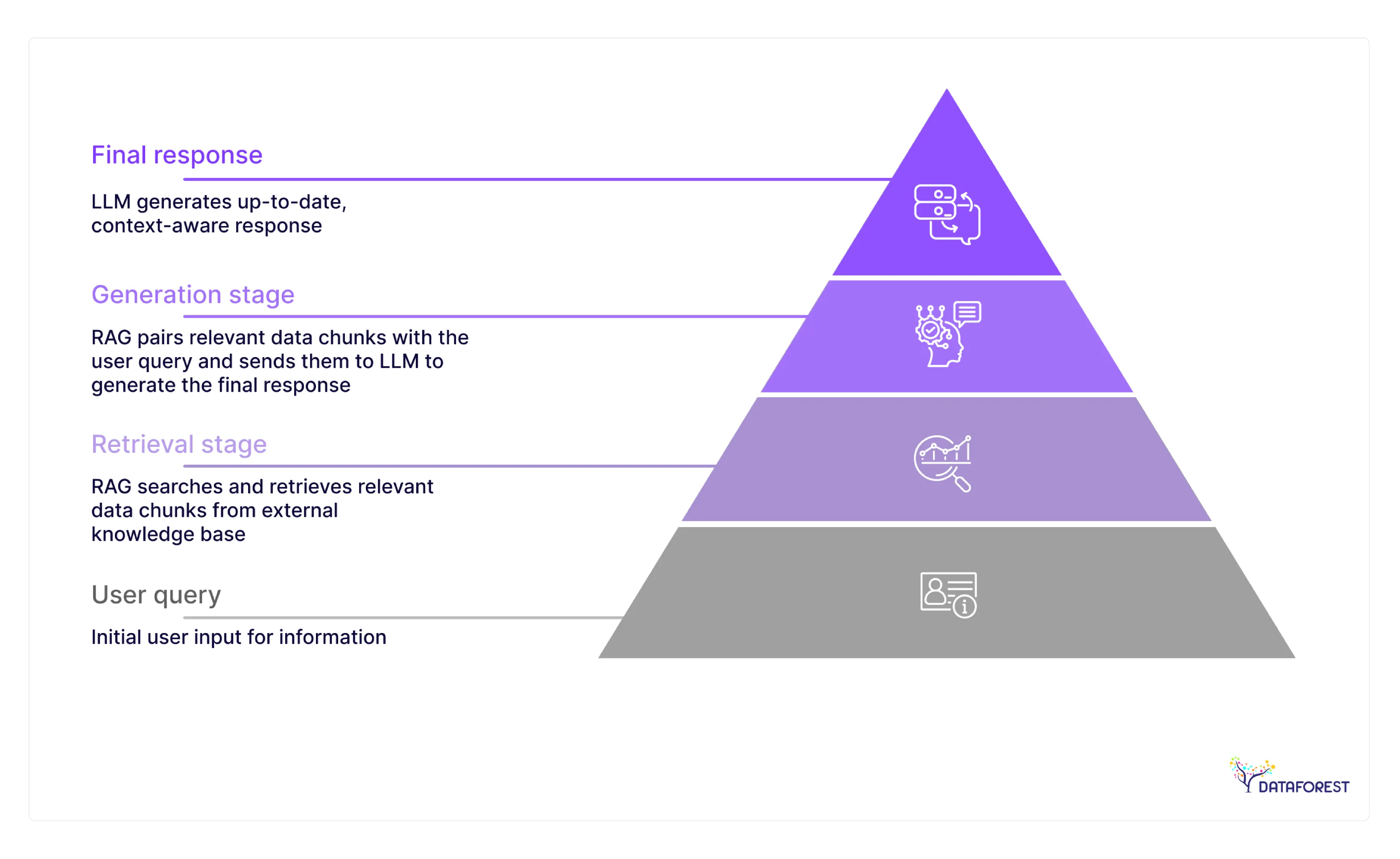
What is Retrieval-Augmented Generation (RAG)?
RAG in natural language understanding is teaching an AI to become a better researcher before it answers. Instead of relying on whatever the model memorized during training, RAG first searches through specific databases or documents to find relevant, up-to-date information about your question. Then it takes fresh search results and uses them as reference material while crafting its response—kind of like how a good journalist fact-checks their sources before writing an article. The magic happens because you're combining the AI's natural language abilities with access to current, reliable information that it can actually point to and cite.
How RAG in LLM Works in Practice
When you ask a RAG-based LLM about quarterly earnings, it doesn't immediately start generating text—instead, it first runs a LLM retrieval search through your company's financial documents, SEC filings, or whatever databases you've connected to it. The system pulls back the most relevant chunks of information, maybe last quarter's actual revenue figures and this quarter's preliminary reports. Then the RAG LLM takes those real document excerpts and uses them as source material while writing its response, weaving the factual data into a coherent answer. What you get back is an analysis grounded in specific documents that the system can actually reference and quote from, ensuring factual consistency in LLM outputs.

What Makes RAG the Missing Piece in an LLM Strategy?
RAG for LLM doesn't patch the holes in traditional LLMs—it rebuilds the foundation by connecting AI responses to verifiable, current sources. The result is finally having an AI system that can be both creative and trustworthy simultaneously.
Getting Facts Right Instead of Sounding Right
RAG in LLM cuts down on those embarrassing moments when your AI states something completely wrong. By anchoring responses in actual documents and data sources, the system can distinguish between what it thinks might be true and what it can actually prove. You end up with answers that don't just sound convincing—they're backed by factual evidence you can trace and verify.
Access to What's Happening Now
Traditional LLMs are stuck in whatever time period they were trained on, but RAG model LLM systems can tap into today's information. Whether it's this morning's market data, last week's policy changes, or yesterday's customer feedback, the AI can incorporate fresh information into responses. This means business decisions are based on current reality.
Breaking Free from Training Limitations
Instead of being locked into whatever the model learned months or years ago, RAG for LLM lets you feed the system exactly the knowledge it needs for your specific use case. Your legal AI can work with your firm's case database, your customer service bot can reference your actual product manuals, and your financial analyst can pull from your real transaction history. The AI becomes genuinely helpful for your specific business, rather than generally intelligent.
How Does RAG in LLM Stop LLMs From Making Things Up?
The secret isn't making LLMs smarter—it's giving them something concrete to work with instead of forcing them to wing it from memory. RAG in LLM essentially transforms your AI from someone guessing at answers to someone who actually looks things up first. The difference is like asking a student to write an essay with their textbook open versus making them rely purely on whatever they remember from last semester, improving LLM accuracy.
When AI Finally Learns to Check Its Homework
External data sources act like a reality check for LLMs—instead of letting the model fabricate plausible-sounding nonsense, RAG for LLM forces it to ground its responses in actual documents and verified information. It is the difference between a know-it-all who makes stuff up versus someone who actually pulls out their phone to fact-check before answering your question. The RAG architecture can still be creative and conversational, but now it must base those responses on real evidence rather than statistical patterns from the training data. When the AI can point to specific sources and say "according to this document," hallucinations don't decrease—they become much easier to spot and correct.
Why Your AI Doesn't Need to Be a Walking Encyclopedia Anymore
RAG in LLM essentially takes the pressure off LLMs to remember everything perfectly by letting them specialize in what they do best—understanding and synthesizing information rather than storing it. Instead of cramming every possible fact into the model's parameters like some kind of digital hoarder, RAG in LLM lets the AI focus on being a skilled researcher and writer who knows how to find and use relevant sources. This division of labor means the model doesn't have to juggle remembering obscure details while also trying to construct coherent responses, which is where a lot of hallucinations originally came from. The result is an AI that's less likely to confidently state wrong information because it's not trying to recall everything from an imperfect internal database, enabling context-aware LLM capabilities.
An AI That Shows Its Work
RAG in LLM transforms generative AI from a mysterious black box into something more like a research assistant who can point to their sources when you ask, "Where did you get that information?" Instead of getting responses that sound authoritative but could be fabricated entirely, you can trace each claim back to specific documents, databases, or sources. This transparency doesn't just help you verify the accuracy—it lets you understand the reasoning behind the response and even dig deeper into the original sources if needed. When your AI can essentially footnote its own responses with real citations, trust stops being a leap of faith and becomes a verifiable process.
Case Studies of LLM Applications with RAG
Legal Research Firm Cuts Case Prep Time by 60%
A mid-sized law firm implemented RAG systems to search through decades of case law and legal precedents, rather than having junior associates spend weeks in the library. When preparing for a complex intellectual property case, their knowledge-augmented LLM pulled relevant rulings from similar patent disputes across multiple jurisdictions and highlighted key legal arguments that had succeeded before. What used to take their team three weeks of research can now be completed in two days, and the AI can cite specific case numbers and court decisions that lawyers can immediately verify.
Healthcare System Reduces Diagnostic Errors with Real-Time Medical Literature
A regional hospital network connected its RAG LLM to current medical journals, treatment protocols, and its own patient database to help doctors stay current with rapidly evolving treatment options. When an emergency room physician encountered an unusual combination of symptoms, the system quickly surfaced recent case studies from medical literature showing similar presentations and successful treatment approaches. The result was faster, more accurate diagnoses backed by the latest research, particularly valuable for rare conditions where individual doctors might see only a handful of cases in their entire career.
Financial Services Company Transforms Customer Support
A credit card company deployed RAG-powered chatbots to give its customer service representatives instant access to current regulations, product terms, and individual account details without switching between multiple systems. When customers call with questions about rewards programs or dispute policies, representatives can now provide personalized answers in real-time rather than putting people on hold to check with supervisors. Customer satisfaction scores increased by 40% because representatives finally had the tools to provide definitive answers.
What Happens When Your AI Gets Reliable?
RAG-based LLM changes how your organization can use artificial intelligence for critical business functions. Instead of treating AI as a creative assistant, you need to fact-check; you suddenly have a system that can handle high-stakes decisions and customer interactions with confidence. The shift from "interesting but risky" to "dependable and scalable" is what turns AI from an expensive experiment into a genuine competitive advantage.
Schedule a call to complement reality with a profitable tech solution.
Why Is DATAFOREST the Ideal Partner for Implementing RAG in LLM?
In today’s AI landscape, implementing RAG in LLM demands more than raw tools—it requires deep expertise in both data engineering and machine learning. DATAFOREST excels at building transparent, scalable RAG for enterprise AI solutions tailored to the complex needs of medium and large enterprises. With a focus on trust and customization, the team helps organizations unlock reliable, high-impact RAG LLM systems built on solid infrastructure and clean data practices.
What Sets DATAFOREST Apart
We’ve spent 20 years sharpening our skills in business automation, large-scale data analysis, and advanced software engineering. We don’t just build ML models—we build the rivers of data that feed them: ETL pipelines, cloud-native infrastructures, API integrations, data lakes, and real-time workflows. Our generative AI and data infrastructure work turns raw, messy information into AI-ready datasets through governance, cleaning, deduplication, and normalization. We guide ML and AI initiatives end-to-end, from proof-of-concept to deployment, monitoring, and optimization, making sure solutions are both efficient and reliable. And above all, we combine technical rigor with transparency and scalability, so every system we deliver is built to last and easy to trust.
Our Tailored Solutions for Medium & Large Enterprises
We begin by diving deep into your enterprise’s core processes—mapping out workflows, data sources, legacy systems, and strategic goals—to craft software that fits you, not the market’s lowest common denominator. From there, we build modular, scalable platforms (including ERP systems, custom web apps, SaaS, and multi-vendor architectures) so that as you grow, your tech infrastructure grows with you, not against you. We also integrate existing systems—such as CRMs, inventory, and finance —alongside external APIs, and layer in AI/ML or generative AI, providing intelligent automation, predictive insights, and dynamic dashboards that feel seamless. Our solutions are battle-tested for performance, featuring optimized RAG pipelines, high-throughput web scraping and data ingestion, resilient cloud infrastructures, and built-in monitoring and observability from the start. And throughout, we maintain tight alignment with your compliance, data privacy, and ROI needs so nothing is “nice to have”—it’s all part of delivering real business value.
Transparent, Scalable Solutions You Can Rely On
We strive to work openly with our clients, sharing clear roadmaps, risks, and implementation progress so nothing feels like a black box. Drawing on numerous completed projects, we build systems that grow with you—handling increased data volume, usage, or complexity without faltering. Our designs emphasize simplicity and maintainability: from modular cloud infrastructure and data pipelines to governance frameworks that make scaling predictable rather than chaotic. We take care to embed monitoring, performance tuning, and cost optimization early on, ensuring the solution is efficient now and remains efficient later. And every decision we make is informed by feedback, trust, and a sense of responsibility—not just chasing the latest tech.

Hallucinations in LLMs—Containment, Not Elimination
Deloitte researchers published an applied paper in SemEval-2025 about token-level hallucination detection, showing approaches that extract LLM internal signals and map them to hallucination spans. Hallucinations aren’t a “bug” you can patch out—they’re a consequence of how large language models work.
Here’s why:
- Statistical guessing at scale. LLMs predict the next token based on patterns, not facts. That means they sometimes produce outputs that sound right but aren’t grounded in reality.
- Training tradeoffs. If you train a model always to answer, it will confidently invent when uncertain. If you train it to abstain more often, it looks less “helpful” and frustrates users.
- Evaluation incentives. Current benchmarks often reward fluency and coverage more than honesty about uncertainty, which nudges models toward polished but false completions.
What’s improving:
- Retrieval-augmented generation (RAG). Plugging models into live databases or document stores helps ground answers in verifiable sources.
- Fine-grained detection. Research shows progress in detecting hallucinations at the token level so that outputs can be flagged in real time.
- Calibration & abstention. Newer approaches teach models to admit when they don’t know, or to mark low-confidence spans instead of inventing.
- Human-in-the-loop systems. Workflows increasingly use RAG-based LLM as drafts or copilots, with humans (or downstream systems) validating the critical pieces.
Hallucinations will shrink, not vanish. Expect fewer “blatant” hallucinations thanks to grounding and detection, but subtle misstatements will linger. In high-stakes fields (finance, medicine, law), complete automation won’t be safe soon. Human oversight and strong guardrails will remain necessary. In low-stakes or creative tasks, hallucinations may even be tolerated—or valuable—since imagination is part of the value.
So, in the near future, the industry will manage hallucinations rather than eliminate them. Think of it less like curing a disease and more like installing brakes, airbags, and warning lights on a car that will always carry some risk. Complete the form for AI reliability improvement and reducing hallucinations in AI in large language models.
FAQ on RAG-Based LLM
How does RAG in LLM enhance the scalability of AI RAG models for large enterprises?
RAG in LLM scales by offloading knowledge storage from the model to external databases. Instead of training bigger models with more parameters, enterprises just add more documents to the retrieval system. The tradeoff is speed—every query now requires a search step before generation can occur.
Can RAG in LLM be integrated with existing AI systems without major overhauls?
Modern LLM APIs support RAG for LLM integration through simple prompt modifications and document preprocessing. The work is in organizing existing data sources and building AI-ready data infrastructure with retrieval pipelines. Expect weeks of data cleanup, not months of system rebuilding.
What industries benefit the most from RAG technology in LLMs?
Legal, healthcare, and financial services see immediate value because they work with massive document libraries that change frequently. Manufacturing and logistics benefit when dealing with complex technical specifications. Any industry where wrong information costs serious money makes RAG in LLM worth the investment.
How does RAG in LLM help companies avoid bias in AI-generated outputs?
RAG in LLM reduces bias by grounding responses in specific documents rather than broad training patterns. Companies control the knowledge sources, so they control the perspective the AI draws from. The downside is that bias in source documents still affects outputs—garbage in, garbage out applies, even with RAG in LLM.
How does RAG in LLM improve the response time of AI systems?
RAG in LLM usually slows down response time because each query requires document retrieval before text generation. The search step adds latency, especially with large knowledge bases. Better indexing and caching help, but pure traditional LLMs responses will always be faster than RAG LLM responses.
How does RAG in LLM impact the customer experience in AI-driven applications?
Customers get from RAG for LLM accurate text generation backed by authentic sources instead of plausible-sounding nonsense. Support agents can cite policy documents when explaining decisions. The tradeoff is slower responses and the occasional "I couldn't find relevant information" when the retrieval system fails.

.svg)
.webp)







