

In the harsh calculus of modern markets, the most valuable currency isn't just capital—it's data. At the same time, financial institutions are struggling to manage a tsunami of information, and the ability to extract daily insights from this firehose is what separates market leaders from yesterday's news. But this strategic imperative collides with immense cost pressures and a brutal war for talent, undermining cost-efficiency. The old playbook—building a massive in-house data engineering team—is proving to be a capital-intensive, time-consuming gamble that few can afford to lose.
The way forward? A strategic pivot. Think of it less as outsourcing a function and more as importing a strategic capability. It's about achieving superior performance, faster time-to-market, and—as leading institutions are discovering—a potential cost reduction of up to 30% on data operations. This article moves beyond theory to provide a C-suite-level blueprint for leveraging external expertise to build a competitive, cost-efficient data infrastructure.
From Data Overload to Strategic Asset: The New Financial Imperative
The financial sector's operational landscape is being fundamentally reshaped by data. Effective management and exploitation of this toolset has become a business imperative that directly influences market position and profit.
Petabyte-Scale Finance Finds Pressure to Be Compound
The volume, velocity, and variety of data are multiplying every single day. This goes far beyond high-frequency trading algorithms that churn through petabytes or AI fraud detection systems processing millions of transactions per second. The stresses on data infrastructure are extraordinary. A McKinsey report highlights that data-driven organizations not only operate more efficiently but are also significantly more likely to acquire and retain customers. The mandate couldn't be clearer: either you master your data, or you cede the market to those who do.
Breaking Free from Legacy Shackles and Data Silos
So many institutions are still shackled by decades of accumulated technology. These legacy systems, often designed for a bygone era, create rigid data silos that make a unified view of the customer or risk landscape impossible. This fragmentation cripples everything from regulatory reporting to any hope of a personalized product offering. As a result, critical processes like data reconciliation become monumental chores that drain resources and inject lag into a world that demands instant answers.
Forging a Competitive Edge with Fluid Data Ecosystems
In this environment, streamlined data workflows are the very engine of digital transformation. A modern data architecture lets information flow seamlessly, which in turn empowers advanced analytics, sharp forecasting, and ironclad compliance. This is the bedrock you build high-value applications on—like custom agentic AI for financial advisors—turning mountains of raw data into the kind of actionable intelligence that creates a real competitive advantage through advanced real-time data platform engineering capabilities.
The Unseen Engine: Why Elite Data Engineering is Non-Negotiable
I make no bones about it: finance data engineering is about the work of building repeatable, scalable and secure systems for the ingestion, storage, audibility and processing of large volumes historical and real-time financial data. It's the critical plumbing — the central nervous system of the modern financial institution — that allows you to feed your dashboards, ML models and decision-making frameworks. Without it, there is no data science—just abstract theory—and "business intelligence" amounts to reading outdated reports. Effective data engineering is precisely what enables mission-critical applications such as real-time fraud detection, algorithmic trading, and automated compliance. Pulling this off requires infrastructure that isn't just functional but high-performance and secure.
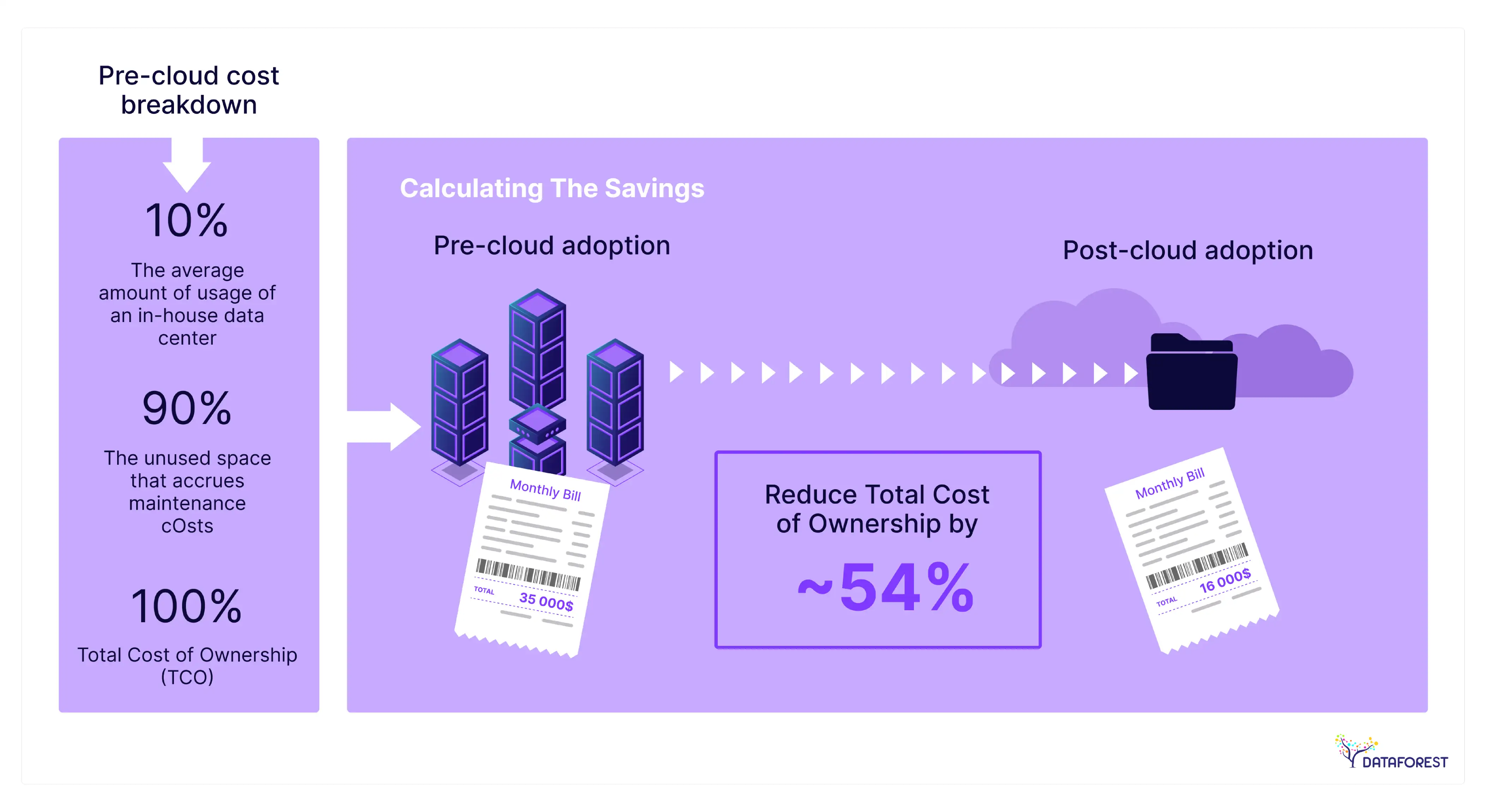
The In-House Paradox: Unpacking the True Cost of an Internal Data Team
And yet, the true cost and sheer complexity of trying to build this in-house are so often underestimated, leading straight into blown budgets, project delays, and strategic dead ends.
The War for Talent: Navigating Extreme Scarcity and Escalating Costs
The fight for elite data engineers is one of the fiercest in today's global market. In any major financial hub, a senior data engineer's salary often exceeds $170,000. But the total cost of employment (TCO) tells a different story. Once you factor in bonuses, benefits, recruiter fees, and training, the annual commitment easily reaches a quarter-million dollars per head.
The Capital Drain: Beyond Salaries to Infrastructure and Licensing Overheads
The capital drain goes far beyond salaries. Whether you're investing in on-premise servers and storage or managing the operational burden of complex data infrastructure, the costs are staggering. Add enterprise-grade licenses for ETL tools, databases, and monitoring software, and the result is a massive fixed overhead you pay on an ongoing basis, regardless of whether you're using it to its full potential.
The Innovation Lag: When Time-to-Market Stretches from Months to Years
For in-house builds, the journey from concept to a fully operational, production-grade data pipeline can take 12 to 18 months or longer. This "time-to-value challenge" represents a massive opportunity cost. While your team is designing a data lake, grappling with data integration challenges, and handling the complexities of financial data pipeline optimization, more agile competitors are already launching new products and capturing market share.

The 30% Cost Reduction Blueprint: A Strategic Shift to External Expertise
Pivoting to cost-effective data engineering solutions is a proven strategy. A Deloitte analysis on outsourcing in financial services pointed out that firms can slash costs by 20-40% by bringing in external vendors for technical functions. Our own experience with clients at DATAFOREST mirrors this; a 30% reduction in costs isn't just possible, it is common. Here's why:
From Fixed Overhead to a Flexible, Pay-for-Value Model
You shift from a fixed cost center to a flexible, pay-for-value model. Instead of carrying the dead weight of salaries and infrastructure, you engage expertise when and where you need it. This allows you to dial resources up for a major data migration and then dial back down, perfectly aligning your investment with your strategic goals.
Accelerating Time-to-Value While Mitigating Execution Risk
Top-tier firms don't show up with a blank whiteboard; they arrive with battle-tested blueprints and best practices for data architecture. This ability to accelerate deployment radically shortens the development lifecycle, shrinking time-to-value from years down to months. They've already navigated the common pitfalls, which means you sidestep the costly failures and redesigns that so often plague internal projects.
Accessing an Elite Talent Bench On-Demand
Your data challenges are not static. One quarter you might need deep expertise in real-time stream processing; the next, you might require a specialist in data governance for compliance. Hiring full-time employees for every possible specialization is unfeasible. An external partner provides a bench of experts you can deploy as needed, ensuring you have the right skills for the task without the long-term commitment. This is a key advantage offered by firms with a deep understanding of the FinTech and Financial industry.
From Blueprint to Reality: Creating a Successful Integration
An external partner comes in collaboratively, deeply. It's about the ability to stitch a dedicated team into your existing tech stack and workflows, so you can meet specific business targets.
Architecting the Core: Pipelines, Lakes, and Governance Frameworks
That generally involves architecting and maintaining the pointier parts of the data lifecycle. We are discussing everything from building upon data pipelines and data lakes to governing frameworks that guarantee data accuracy and compliance.
A Practical Use Case: Augmenting Your Existing Fintech Stack
Picture a mid-sized fintech firm trying to launch a new analytics product. Instead of getting bogged down in a year-long hiring spree, they partner with a data engineering vendor. That external team syncs up with their product managers, plugs into their cloud infrastructure, and starts rapidly prototyping and deploying the necessary data pipelines.
Case in Point: How a Financial Platform Transformed Its Reporting Engine
A financial intermediation platform DATAFOREST worked with is a perfect real-world example. They were struggling with a decentralized, manual reporting system that was slow and unreliable. By bringing our team in, we built a centralized data warehouse that was built on automation from the ground up to streamline the entire process. The results were night and day: a steep drop in operational costs and a massive leap in the speed and quality of insights.
Vetting Your Partner: The Non-Negotiable Attributes of an Elite Vendor
Picking a vendor is a high-stakes game. The right partner becomes a true extension of your team; the wrong one just adds risk and headaches. Zero in on these attributes:
Fortress-Grade Security and Deep Regulatory Fluency
In finance, security is everything. Any potential partner must have deep, demonstrable expertise in regulations like GDPR, CCPA, and SOX, backed by certifications like SOC 2 or ISO 27001. They need to live and breathe data encryption, network security, privacy controls, and access control.
Beyond Generic Tech: The Imperative of Deep Financial Domain Expertise
Data engineering at large won't suffice either. The financial world presents its own challenges. You are looking for someone who understands the complexity of various asset classes and the headaches involved in regulatory reporting — someone with whom you don't have to negotiate every silo. They need to provide fast, efficient integration that is least disruptive to your core business.
The Executive's Due Diligence: A Checklist for Potential Partners
Before you put your name on anything, your due diligence should be surgical. The following questions are what distinguish real partners from subpar ones:
Beyond Promises: Demanding Guaranteed SLAs and Performance KPIs
Ask for concrete metrics. Will they provide guarantees on data pipeline uptime, latency and mean time to resolution? A bold service provider will agree to tangible Service Level Agreements (SLAs) and Key Performance Indicators (KPIs) that ensure system performance.
Ensuring Sovereignty: Protocols for Knowledge Transfer and Documentation
The goal is partnership, not dependency. Make sure they have a rock-solid process for documenting the architecture, code, and workflows. This empowers your own team and guarantees long-term sustainability.
Future-Proofing Your Investment: A Clear Roadmap for Scalability
Your solution has to be built for tomorrow. Probe their approach to cloud-native design and infrastructure-as-code. A partner worth their salt will design a system that can grow with your business, not one that will need to be ripped out and replaced in three years.
Engineering a Sustainable Competitive Advantage: More than Just Cost Savings
The discussion on data in finance is fundamentally different. It's no longer about managing a costly and complex asset but about unleashing its strategic value. It is simply too long, costly, and risky to attempt to create a world-class data engineering team from scratch. A smarter approach to the future If you are bogged down with just a limited staff in planning, management and evaluation of the new corporate strategy then making strategic alliance with technical companies like DATAFOREST is a lot smarter way forward. It offers access to world-class talent and the most cutting-edge technology, with a high degree of flexibility and cost effectiveness. This isn't just about cutting costs - moving from CAPEX to OPEX; you are supercharging – for want of a better word, your entire digital transformation. You're building the resilient, scalable data foundation that will power better decisions, innovative products, and a sustainable competitive advantage for years to come.
Ready to see what this looks like for your organization? Book a consultation to talk specifics with our financial data experts.
Frequently Asked Questions (FAQ)
Is outsourcing data engineering secure enough for sensitive financial data?
It absolutely is, as long as you choose a partner who lives and breathes security and compliance. The best firms operate within your own secure cloud environment and adhere to the strictest protocols like SOC 2 and ISO 27001, using end-to-end encryption and continuous monitoring to keep your data locked down.
What components of a financial data stack can be outsourced?
Virtually the entire data engineering lifecycle can be managed by a specialized external partner, allowing your in-house team to focus on extracting value rather than managing infrastructure. Key components typically include:
- Data Ingestion and Integration: Building and maintaining robust data pipelines that pull information from disparate sources, including core banking systems, third-party APIs, market data feeds, and legacy databases.
- Data Storage and Warehousing: The design, implementation, and management of scalable storage solutions, such as data lakes for raw data and cloud data warehouses (e.g., Snowflake, BigQuery, Redshift) for structured, analytics-ready information.
- Data Transformation and Modeling: The critical "T" in ETL/ELT processes, where raw data is cleaned, structured, aggregated, and modeled to be useful for analytics, reporting, and machine learning applications.
- Infrastructure and Operations (DataOps): Managing the underlying cloud infrastructure, implementing CI/CD for data pipelines, monitoring for performance and reliability, and ensuring the entire stack is cost-optimized and secure.
- Data Governance and Compliance: Implementing frameworks to ensure data quality, security, user access control, and adherence to financial regulations like GDPR, CCPA, and others.
How do outsourced data engineering solutions compare to building an in-house team?
While an in-house team offers direct control, it comes at a premium—high costs, long hiring cycles, and significant overhead. An outsourced team gives you immediate access to top-tier, specialized talent, often delivering a production-ready platform in a fraction of the time and at a significantly lower TCO, as detailed in articles on financial data integration.
What technologies do outsourced data engineering teams typically use?
Expert teams are fluent in modern, cloud-native stacks. You will typically see tools like AWS, Azure, and Google Cloud; data warehousing solutions like Snowflake or BigQuery; data processing frameworks like Apache Spark; and BI platforms like Tableau or Power BI. The right partner will tailor the tech stack specifically to your needs for performance and scale.
Will outsourcing limit our ability to customize and innovate?
Quite the opposite. By taking the complex, foundational data engineering off your plate, a great partner frees up your internal teams to focus on what they do best: data science, product development, and strategy. It's about building a flexible architecture that empowers your innovation, not restricts it, allowing you to develop advanced tools like a decision support system.


.webp)







