

Walmart discovered theft patterns in 2018. Store managers suspected employee theft but couldn't pinpoint when or where it occurred. They had transaction data, but no clear target to predict. Unsupervised machine learning found clusters of suspicious behavior during shift changes. The algorithm revealed theft happened during manager handoffs. This wasn't obvious from reports. Managers adjusted schedules and cut losses by 23%. Supervised learning would have failed here. You can't predict theft patterns when you don't know what normal looks like first. Book a call, get advice from DATAFOREST, and move in the right direction.
Supervised Machine Learning vs Unsupervised—When Data Has No Destination
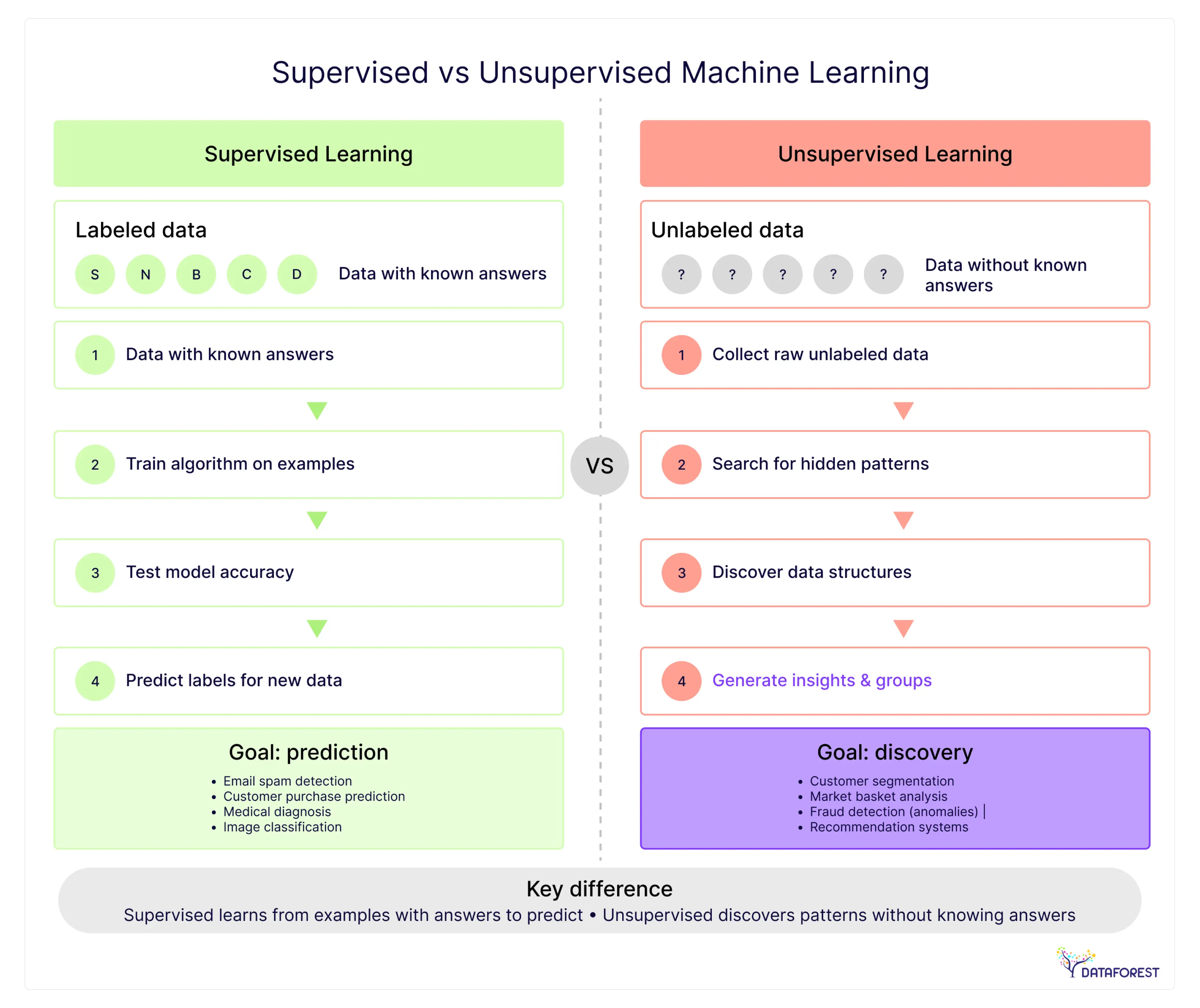
Medium underlines that supervised vs unsupervised machine learning has differences in training structure, complexity, interpretability, and labeling effort. Companies sit on mountains of data but struggle to extract business value from it. The choice between supervised machine learning vs unsupervised approaches determines whether you'll build solutions that solve real problems or waste resources chasing irrelevant patterns.
The Corporate Data Cemetery
You've got customer service tickets from three years ago, website clicks nobody's looked at since they were recorded, and sales data that could solve half your revenue problems if anyone bothered to dig into it. The real kicker isn't that companies lack the technical chops to analyze this stuff—it's that they haven't made the basic decision about what they're trying to figure out. Are you trying to predict something specific, like which customers might defect next month, or are you seeking patterns you didn't even know existed—why some product combinations are always returned together? While most teams are still arguing about which analytics platform to buy, their competitors are already using the same messy, imperfect data to make smarter business moves because they figured out whether machine learning supervised vs unsupervised matches the business problem.
The Great Platform Wake-Up Call
Digital platforms are playing business roulette right now, and most don't realize they're at the table. Companies like Airbnb, Uber, and smaller SaaS platforms live or die based on understanding user behavior patterns. Many are flying blind because they can't consider what their data is telling them. The winners are those who know whether they need to predict specific outcomes—like which users will churn next month—or discover hidden behavioral clusters that reveal entirely new market opportunities. Meanwhile, the losers keep building features based on gut feelings while competitors use the same type of user data to steal market share, because they figured out which supervised vs unsupervised machine learning approach matches their business problems.
Examples of Supervised Machine Learning Vs Unsupervised
- Regional credit union used unsupervised machine learning to find fraud patterns in transaction data, discovering that most suspicious activity happened during lunch hours when fewer staff were monitoring accounts (reduced fraud losses by 34%).
- A mid-size manufacturer applied supervised machine learning to predict equipment failures based on sensor readings, preventing costly downtime by scheduling maintenance before breakdowns occurred (saved $2.1M in emergency repairs).
- Online subscription service deployed unsupervised machine learning on user behavior data, uncovering distinct customer segments they didn't know existed, including "binge watchers" who consumed content differently than expected (boosted retention by 28%).
- Local delivery company used supervised machine learning to predict delivery delays based on traffic patterns and weather data, allowing them to proactively communicate with customers (improved satisfaction scores by 41%).
- Retail pharmacy chain applied unsupervised machine learning to prescription refill data, finding geographic clusters of medication adherence problems they could address with targeted outreach programs (increased patient compliance by 19%).
Insurance Profitability Analysis Tool


Great work! The team provided an excellent solution for consolidating our data from multiple sources and creating valuable insights for our business.
When Should Tech Companies Use Supervised Machine Learning?
Think of supervised vs unsupervised machine learning as teaching a computer either to recognize patterns from labeled examples or to explore without instructions. Supervised learning is similar to training a new employee by walking them through case after case until they can handle similar situations independently.
Pattern Recognition for Profit
Supervised machine learning is showing a computer thousands of examples where you already know the answer, then asking it to spot similar patterns in new situations. It's like training someone to identify good job candidates by walking them through hundreds of resumes where you know who got hired and who worked out well. The "supervised" part means you're acting as the teacher, providing the correct answers during training so the system learns what success looks like before making predictions on its own.
Best Supervised Machine Learning Use Cases
Large tech companies use supervised ML to predict what customers might buy next. The models learn from millions of past purchases—nothing magical, just pattern matching. Payment companies feed transaction data into ML models to catch fraud faster than humans can scan it, though false flags still waste time. Voice commands and facial recognition work because tech giants poured years of labeled data into training—but they still stumble on accents and lighting.
Real Business Impact of Supervised Machine Learning
Companies can cut costs when ML handles repetitive tasks, such as sorting customer service tickets or scanning documents. Marketing teams boost sales by using ML to spot which leads are worth chasing, instead of wasting time on dead ends. Machine learning models process customer data to predict who might leave—giving sales teams a chance to step in before accounts go cold. These systems need massive amounts of clean, labeled data to work well, and that data prep eats up time and money.
Fraud Detection at PayPal
PayPal processes millions of transactions daily and needed faster fraud detection than human analysts could handle. They built an ML system trained on ten years of labeled transaction data, marking which payments were fraudulent or legitimate. The model now flags suspicious patterns in real-time, cutting fraud losses by 40%—though it sometimes blocks valid transactions from unusual locations. The system keeps learning from new fraud patterns, but needs constant updates as scammers adapt their tactics.

What Makes Unsupervised Learning Worth the Hassle?
Unsupervised machine learning helps spot hidden patterns without needing humans to label everything first. The catch is that these insights often lead to more questions than answers—but that's precisely where breakthroughs hide.
What Unsupervised Learning Really Does
Think of unsupervised learning as releasing an algorithm to search for patterns in raw data without specifying what to look for. Unlike systems that need training examples, these models group similar items together based on whatever stands out in the data. The catch lies in what these machine-discovered patterns mean for the business. Sometimes patterns reveal genuine insights, while other times they are statistical noise. The work begins after the algorithm finishes, when humans interpret the groupings and determine if they are meaningful.
Hidden Uses of Pattern-Finding AI
- A gaming company found odd spikes in player dropouts by machine learning algorithms running on their server data.
- Banks spot money laundering rings by finding weird transaction clusters that their rules missed completely.
- Media companies dump user behavior into pattern finders to see why some content catches fire while similar stuff flops.
- Security firms turn these tools on network traffic to catch hackers using tricks that slip past normal defenses.
- Small online shops use basic clustering to group products based on how real people browse—not how marketers think they should.
Real Value from Pattern Discovery
Leaders uncover fresh opportunities by finding hidden connections their teams would never spot through standard analysis. Raw data transforms into clear signals about where money gets wasted and which changes actually move the needle. Smart pattern-finding shrinks the time between spotting a market shift and adapting the business to match it. Teams spend less time manually sorting through data noise and more time acting on genuine insights. Rather than force-fitting customers into rigid categories, companies now see how people naturally group themselves and adjust their approach to match reality.
Finding Hidden Groups of Stars with Unsupervised Learning
Astronomers studying the Milky Way had data on thousands of star clusters, but no clear labels that explained their chemical differences. They used unsupervised machine learning to let the data group itself, revealing previously unseen categories of clusters. The method showed that stars that looked similar on the surface often had very different origins. This approach gave researchers a new way to trace how the galaxy formed, without needing labeled training examples.
Comparison Matrix Between Supervised and Unsupervised Learning
When you’ve got clean, labeled data and want straight predictions, supervised machine learning vs unsupervised is the key distinction. Supervised vs unsupervised machine learning defines whether your system predicts outcomes or discovers new clusters.
Schedule a call to complement reality with a profitable tech solution.
How Should Enterprises Decide Between Supervised and Unsupervised ML?
Choosing the wrong approach in machine learning, supervised vs unsupervised, wastes resources, while the proper one ties directly to solving revenue or efficiency challenges. The process isn’t about abstract AI promises—it’s about practical steps that fit into your existing systems without disruption, ensuring smooth enterprise AI adoption and measurable data-driven decision making.
- Audit Your Data Pipelines
Before picking a machine learning method, you need to know if your data is ready. That means checking how clean it is, how consistent the formats are, and whether it flows into a single accessible system. Without this groundwork, any machine learning workflow—supervised or unsupervised—will collapse under bad inputs.
- Define the Business Problem
Machine learning only works when tied to a clear business challenge. Are you trying to predict customer churn, detect fraud in payments, or optimize supply chain efficiency? A sharp definition prevents teams from chasing data patterns that look interesting but solve nothing. This step is crucial for aligning the applications of machine learning with genuine business value.
- Match ML Type to the Problem
Once the challenge is set, decide if it’s about prediction (supervised) or discovery (unsupervised). For example:
- Supervised = predicting which invoices won’t get paid or using predictive analytics for spam detection.
- Unsupervised = grouping customers into natural segments using clustering techniques.
This is where the key differences in machine learning become practical, and where ROI either becomes obvious or vanishes.
- Build Microservice AI Modules
Instead of forcing AI into the core of your systems, wrap it as a microservice. This lets existing developer teams keep their workflows, while ML adds intelligence without breaking things. The modular approach lowers risk, speeds rollout, and avoids massive refactoring projects.
- Track ROI in Real Terms
Machine learning isn’t finished when the model is deployed—it’s proven when it pays off. Track clear metrics like cost reductions, revenue lifts, or time saved in operations. This keeps the project accountable and lets you decide whether to scale, adjust, or shut it down.
When Data Gets Overwhelming
CxOs have a choice when their data piles up faster than their insights, wondering whether they need supervised machine learning vs unsupervised discovery. DATAFOREST analyzes your specific business context—whether you're trying to predict customer churn (where supervised learning shines) or segment customers into unknown groups (where unsupervised methods excel). Our consultants dig into your data maturity, available labeled examples, and business objectives, then map out which approach actually fits your reality rather than just following the latest tech trends. The real value comes from the ability to spot when businesses think they need complex unsupervised clustering but actually just need straightforward supervised classification—or vice versa—saving companies from expensive detours down the wrong analytical path.
Please complete the form to get consulting about machine learning, supervised vs unsupervised.
FAQ On Supervised Machine Learning Vs Unsupervised
How can small businesses leverage supervised learning without massive datasets?
Start with focused problems where even 100-500 examples can be practical—such as predicting which customers will return or identifying high-value leads from your existing customer base. The deal is being strategic about what you're trying to predict rather than casting a wide net. Algorithms like logistic regression or decision trees can extract meaningful patterns from smaller, well-curated datasets. You can augment your limited data through a synthetic data generation technique or by partnering with similar businesses to pool anonymized datasets, turning your size constraint into an advantage through creative collaboration.
Can unsupervised learning help identify new revenue streams?
It often reveals opportunities hiding in plain sight within your existing customer data. Clustering algorithms can uncover distinct customer segments you never knew existed—maybe you'll discover that 30% of your customers have buying patterns that suggest they'd love a premium service tier you haven't offered yet. Market basket analysis (another unsupervised technique) can reveal unexpected product combinations that customers buy together, opening doors to new bundling strategies or cross-selling opportunities that feel natural rather than pushy.
How does data quality affect the success of supervised ML models?
Data quality is the foundation of a house—no matter how sophisticated your ML model is, garbage data will produce garbage predictions that can actually hurt your business decisions. Poor data quality manifests in subtle ways: missing values create blind spots, inconsistent formatting confuses algorithms, and outdated information teaches models patterns that no longer exist. The frustrating part is that insufficient data often produces models that look successful during testing but fail spectacularly in the real world, which is why many companies spend 60-80% of their ML project time just cleaning and preparing their data.
What are common pitfalls when implementing ML in enterprise workflows?
The biggest trap is treating ML as a magic solution rather than a tool that needs to fit into existing human processes—many enterprises build impressive models that sit unused because they didn't consider how busy employees would actually interact with the predictions. Another pitfall is jumping to complex algorithms when simpler approaches would work better and be easier to maintain. It leads to "black box" systems that nobody trusts when they inevitably need debugging. Companies also frequently underestimate the ongoing maintenance required, expecting ML models to work forever without retraining, only to watch performance gradually degrade as business conditions change.
How can businesses combine supervised and unsupervised learning for better insights?
The most powerful approach is to use unsupervised learning as a detective to find patterns, and then use supervised learning as a predictor to act on those patterns—such as using clustering to discover customer segments, and then building separate prediction models for each segment's behavior. You can start with supervised models to solve specific problems, then use unsupervised techniques to understand why certain predictions work or fail, revealing deeper business insights along the way. This combination creates a feedback loop where each approach strengthens the other, transforming your ML system into something that not only solves immediate problems but also generates new strategic questions worth exploring.
Which ML algorithms are easiest for non-technical teams to adopt?
Decision trees win hands-down for interpretability since they literally show you the "if-then" logic the model uses, making it easy for marketing managers or sales teams to understand and trust the recommendations. Linear regression and logistic regression are also surprisingly accessible because they work similarly to the statistical thinking most business professionals already use—they just formalize the relationships between factors you probably already discuss in meetings. Automated ML platforms or no-code solutions have made these algorithms more approachable, letting teams focus on asking the right business questions.


%20(1).webp)







