

A telecom company sells anonymized location patterns from cell towers to retailers who want to understand foot traffic around their stores. The company generates $50M annually from first-party data monetization that was previously just network overhead, while retailers get actionable insights that drive $200M in better site selection decisions. If you think this is your case, then arrange a call.

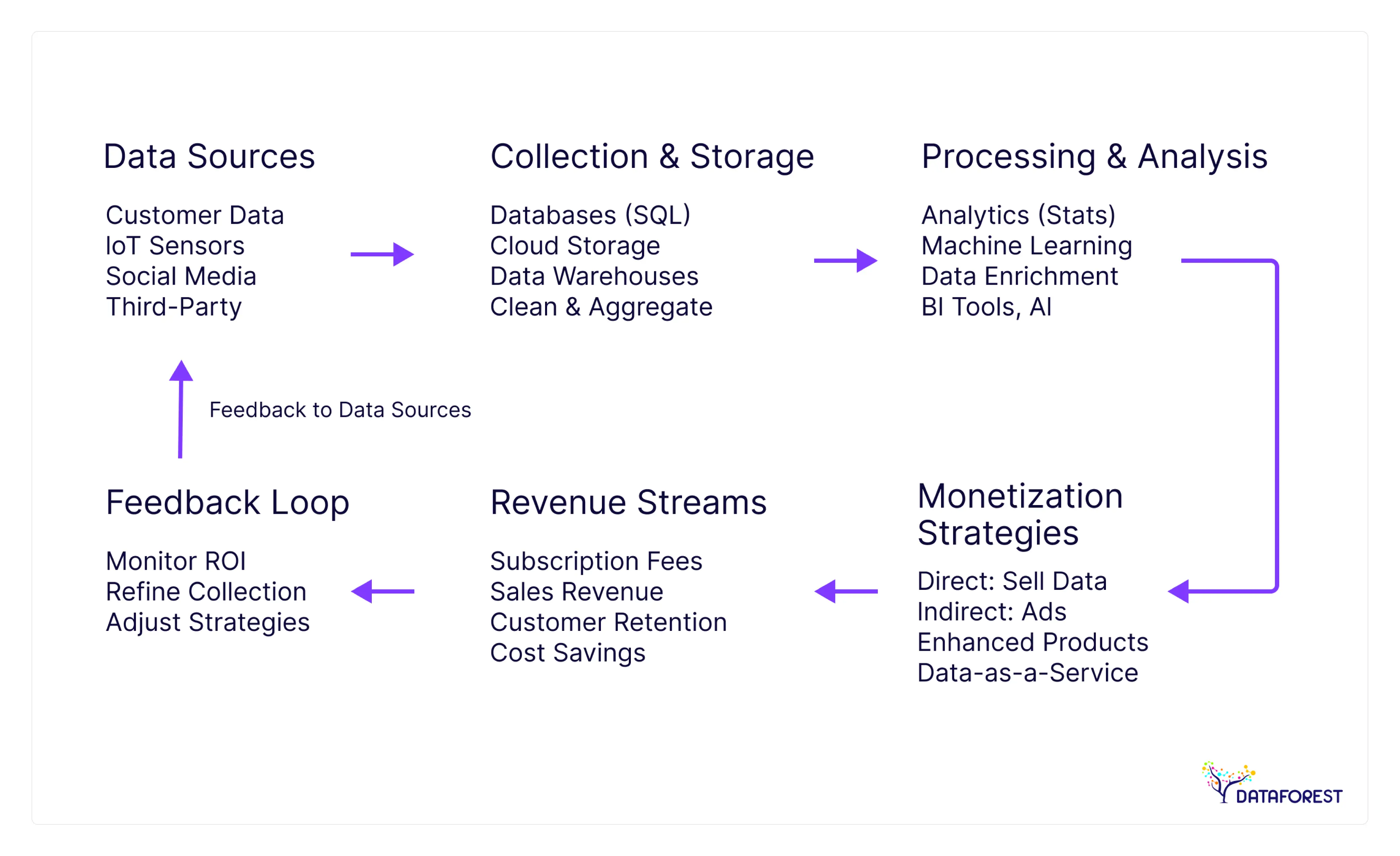
What Is Data Monetization?
Companies sit on massive enterprise data piles while competitors build revenue streams from similar information. The gap between data hoarders and data sellers grows wider each quarter. Three shifts make this transformation unavoidable now.
Data as Working Capital
Enterprises treat internal data like office supplies in a storage room. Raw data sits in warehouses, costing money to maintain and secure. Innovative companies flip this model by turning stored data assets into products customers pay for. The shift requires infrastructure that can process, clean, and package customer data at scale. Engineering teams build pipelines that transform messy data internally into data insights. This work demands upfront investment but creates recurring revenue streams through the execution of a big data monetization strategy.
Missed Revenue Hidden in Plain Sight
Organizations generate valuable behavioral data through normal operations, but rarely capture its economic potential. Transactional data, supply chain flows, and operational metrics contain insights worth millions to other companies. The problem lies in execution.
Most data teams focus on business intelligence for internal data science, while external data monetization opportunities go unexplored. Competitors who identify opportunities in these blind spots gain significant advantages. The window for easy wins shrinks as more players enter the data marketplace.
Engineering teams must balance internal needs with external revenue potential. Building systems that serve both purposes requires careful planning and resource allocation. Companies that delay this transition find themselves playing catch-up in crowded markets.
Data Velocity Creates Sustainable Competitive Moats
Speed determines who wins in monetization strategy battles. Companies that process and deliver actionable insights faster than competitors command premium prices. Real-time sensor data streams generate more value than batch-processed reports delivered days later.
Clever leveraging data means building systems that learn and improve automatically. Manual processes cannot scale to handle enterprise data volumes profitably. Automation becomes essential for maintaining margins while expanding customer experiences based on data product offerings.
The competitive advantage comes from execution speed, not data uniqueness. Similar datasets exist across industries, but few companies can package and deliver them effectively. Engineering excellence separates profitable monetize data operations from expensive data hoarding.

What Valuable Data Are You Already Collecting but Not Selling?
Your systems capture data worth millions while you pay storage costs. Most companies miss obvious revenue streams hiding in routine operations. This is the untapped potential of first-party data monetization, where internal information is transformed into market-ready insights.
User Behavior Logs & Clickstreams
Clickstream data shows exactly how people navigate systems and where they get stuck. Companies pay big money for this information to improve customer engagement. Your user activity reveals patterns that competitors need, making it a prime example in data monetization case studies.
Transaction and Refund Patterns
Transaction patterns and chargeback data reveal fraud trends before they hit mainstream news. Financial institutions buy this intelligence to protect themselves. Refund patterns show which products fail and why, proving the value of monetization of monetization initiatives from payment ecosystems.
Supply Chain Intelligence Others Need
Inventory movements predict demand shifts across entire industries. Retailers pay premium prices for early signals about product popularity. Logistics machine data shows transportation bottlenecks that affect pricing, another real-world example from data monetization case studies.
Customer Profiles & Loyalty Activity
Profile data and loyalty activity patterns reveal what drives purchasing decisions. Marketing agencies spend fortunes trying to understand customer segments. Your data shows actual behavior, not survey responses, making it ideal for data monetization solutions targeted at marketing and ad-tech firms.
Connected Device Performance Metrics
IoT usage data reveals how products perform in real conditions. Manufacturers need this feedback to improve designs and prevent failures. Service patterns show maintenance needs before breakdowns occur, showcasing data monetization services in industrial IoT.
How Do You Turn Raw Data into Real Money Without Getting Burned?
Data monetization solutions fail because teams skip the complex parts. Building revenue from data requires infrastructure, not inspiration. Here's what works when executives stop looking over your shoulder.
Find Data Worth More Than Storage Costs
What: Audit existing data flows and measure external demand signals. Look for information others pay to recreate or approximate. This is the foundation of first-party data monetization.
How: Map data collection points across systems. Survey potential buyers about pain points. Calculate costs of similar data from commercial providers.
Result: A ranked list of sellable assets by market value and data quality. No more guessing about what people want.
Engineer Systems That Scale Beyond Prototypes
What: Build data pipelines for a data-driven strategy that handle real customer loads without breaking. Design for reliability over clever features.
How: Start with proven architectures. Plan for 10x current volume. Test failure scenarios before launch. Document everything that breaks.
Result: Infrastructure that works when customers depend on it—critical for sustainable big data monetization.
Package Information People Will Pay For
What: Transform raw data into answers that solve specific business problems. Focus on decision-making, a best practice in data monetization solutions.
How: Interview potential customers about their workflow. Build dashboards that replace manual processes. Test with real users before scaling.
The result is that customers renew because they save time or make money. Clear value proposition that sells itself—exactly the aim of successful data monetization services.
Deploy Insights Where Work Gets Done
What: Integrate data products into existing business processes. Automate decision-making and track adoption.
How: Connect to the tools teams already use. Automate routine decisions. Train users on new workflows. Measure adoption rates.
Result: Data that changes behavior instead of gathering digital dust—actual data monetization in action.
What Happens When Companies Turn Data into Revenue?
Data monetization case studies sound great until you try them. Equipment breaks, customers complain, and revenue projections miss by huge margins. Here's what works when the PowerPoint presentations end.
Equipment Failure Prediction That Works
Industrial machines generate millions of sensor readings daily. Temperature spikes, vibration changes, hydraulic pressure drops. Most companies throw this information away after basic monitoring. Maintenance teams write down what breaks and when, creating failure histories worth thousands per incident avoided—classic big data monetization in predictive maintenance.
Combine sensor streams with repair records. Oil analysis reports show contamination levels. Usage patterns reveal which operators stress equipment the most. Environmental data tracks how the weather affects performance. This combination predicts failures weeks before they happen.
Kafka handles sensor data streams without losing messages during network outages. Python scripts clean noisy readings and fill data gaps. Machine learning models (e.g., random forest) learn failure signatures from historical breakdowns. Grafana dashboards show risk scores that mechanics understand without training.
Fleet operators cut unplanned downtime by 40% within six months. Service contracts become profitable because fewer emergency calls happen. Engineers fix problems before customers notice performance drops. Parts inventory costs drop 15% through better scheduling. This is a perfect example of big data monetization applied to operational efficiency.
Store Performance Intelligence
Point-of-sale systems capture every customer transaction across hundreds of locations. Purchase histories show seasonal patterns and geographic preferences. Loyalty card data reveals which promotions drive repeat visits. Inventory turnover rates indicate local demand differences—clear potential for first-party data monetization in retail.
Weather data correlates with buying behavior. Demographic information explains store performance variations. Social media mentions predict product popularity before sales data shows trends. Credit card zip codes reveal customer travel patterns between locations.
Snowflake data warehouse consolidates transaction records from multiple store systems. DBT transforms raw sales data into customer segments and product performance metrics. Looker dashboards let store managers compare performance against regional averages. Recommendation engines identify cross-selling opportunities based on local buying patterns. A/B testing framework measures the effectiveness of promotions across different customer segments. Real-time inventory APIs prevent stockouts of high-demand items.
Retail chain increases repeat purchases by 25% through targeted offers that match local preferences. The marketing budget gets focused on customers who spend money instead of window shoppers. Store managers stock products people want instead of guessing from national trends. Regional managers identify underperforming locations and fix operational problems. Buyers negotiate better vendor terms using consolidated demand data. Finance teams forecast revenue more accurately—delivering measurable cost reduction and growth during data monetization.

Chargeback Pattern Detection
Payment processors handle millions of transactions daily, generating dispute and chargeback records. Merchant category codes reveal which business types face higher fraud rates. Geographic data shows fraud hotspots by zip code and time of day. Device fingerprinting tracks suspicious payment patterns.
Card issuer data indicates which banks flag transactions most aggressively. Customer service logs document legitimate disputes versus fraudulent claims. Transaction timing patterns reveal automated attacks. Purchase amounts and frequencies identify unusual spending behavior. It’s perfect for monetizing data in financial risk intelligence.
Apache Kafka streams transaction data to multiple fraud detection models simultaneously. XGBoost algorithms score transaction risk based on hundreds of features. Redis caches recent transaction histories for real-time lookups during payment processing. Graph databases track relationships between suspicious accounts and devices. Elasticsearch indexes transaction patterns for rapid similarity searches. API gateways route high-risk transactions to manual review queues while processing low-risk payments automatically.
Financial losses from fraud drop by 60% without increasing false positives that annoy customers. Legitimate transactions get approved faster because fewer require manual review. Merchants avoid chargebacks before they happen, protecting revenue and data privacy agreements. Customer satisfaction improves because fewer valid purchases get blocked. Processing costs decrease as manual review volume drops. Revenue increases when legitimate high-value transactions clear quickly instead of timing out, making it a textbook data monetization solution in the FinTech sector.
How a 34-State U.S. Dessert Franchise Gained Full Performance Visibility
.webp)

Tifa Chocolate & Gelato is a U.S.-based dessert franchise operating across 34 states.
Why Do Most Data Projects Fail While Others Make Real Money?
Teams build impressive technical solutions that nobody uses. Success comes from solving business problems, not showcasing engineering skills. First-party data monetization works when strategy comes before tech.
If you need a personalized solution, book a call.
How Can DATAFOREST Unlock Your Data’s Monetization Potential?
DATAFOREST empowers mid-market enterprises—especially those lacking in-house AI teams—to convert their operational data into valuable revenue streams through data monetization services and AI implementation. They craft custom microservices, dashboards, internal portals, and ERP integrations tailored to each industry’s unique needs. With deep domain experience in SaaS, retail, marketplaces, FinTech, and utilities, they deliver scalable, turnkey data monetization solutions that turn raw data into strategic assets.
From Data Engineering to AI Model Delivery
DATAFOREST builds scalable and reliable data architecture that seamlessly bridges raw data ingestion to AI-powered insights. The data engineering services—covering ETL pipelines, real-time streaming, cloud optimization, and microservices—set the foundation for robust AI workflows. We design, curate, and govern AI-ready datasets, including labeling, version control, governance, and LLM training pipelines. Engineers ensure the entire model lifecycle—from training data prep to deployment and monitoring—is fully managed. This turnkey approach ensures mid-market businesses can deploy production-ready AI without needing specialized internal expertise.
Ideal for Mid-Market Enterprises with No In-House AI Team
DATAFOREST specializes in serving mid-sized companies that lack dedicated AI or data science departments. These businesses get expert-led solutions—without having to hire data engineers, scientists, or Machine learning staff. With proven delivery models (including PoCs and MVPs), clients enjoy rapid iteration and measurable ROI. The team provides clear communication and client-centric collaboration, positioning itself as an extension of the internal team, not just an external vendor.
Custom Microservices, Dashboards, Portals, Internal ERP Integrations
We deliver bespoke components such as microservices, dashboards, portals, and ERP modules that integrate with clients’ existing ecosystems. Whether it’s analytical dashboards for decision-making, web portals for internal or customer use, or embedding insights into ERP systems, we tailor each solution to fit. Full-stack capabilities span front-end, back-end, DevOps, and AI integration—ensuring that insights are embedded where work happens. Microservices architectures enable modular, maintainable deployments that scale as client needs evolve.
Industry Experience—SaaS, Retail, Marketplaces, FinTech, Utilities
DATAFOREST brings diverse domain expertise across verticals, including SaaS, retail/e-commerce, marketplaces, financial services, and utilities. In retail, we’ve generated personalized insights, forecast demand, and reduced inventory costs for large clients. In FinTech, chargeback management platforms, financial services infrastructure, and AI scoring tools are utilized. For utilities and healthcare, here are intelligent dashboards, compliance tools, and automated reporting systems. The cross-industry exposure means we understand sector-specific data nuances, regulatory concerns, and monetization potential.
Context-Driven AI for Next-Generation Data Monetization
Bain argues that most organizations possess vast quantities of valuable data that go unused, not due to a lack of utility, but because it’s disconnected from actionable context—rendering it challenging to monetize effectively. Traditional monetization methods like flat files, Design APIs, or dashboards frequently fall short—they assume buyers already know what to ask for, understand how to use the data, and remember when to act. To overcome this gap, Bain introduces Model Context Protocols (MCPs)—AI-enabled frameworks that assemble roles, tools, data, and memory into structured, context-aware flows. MCPs transform raw information into answers delivered directly at the moment of decision, embedding best-practice logic and reducing the burden on users. This “just-in-time” access enables monetization through in-the-moment insight activation rather than pre-packaged products. By embedding expertise and decision-context into MCPs, organizations can expand the commercial viability of fragmented or niche datasets and embed data-driven decisions across operational teams, not just centralized analytics groups.
Please complete the form to move closer to first-party data monetization.
FAQ On Monetization of Data
How can my company monetize data without selling it to third parties?
Build products that customers pay for using the data you collect. Internal recommendations engines increase sales conversion rates. Predictive models reduce costs by preventing problems before they happen. API services let partners access insights without sharing raw information—an approach often used in first-party data monetization strategies.
What types of data should we focus on first to generate value quickly?
Start with data that solves expensive problems people already pay to fix. Customer behavior patterns that improve targeting work faster than complex predictions. Operational data that prevents downtime pays back within months. Transaction patterns that reduce fraud show immediate ROI—common examples in data monetization case studies.
How do we know if we're ready to start monetizing our data?
You collect data consistently without major quality problems. Someone on the team understands how to clean and process information reliably. Basic analytics infrastructure exists and handles current data volumes. Executive support exists for projects that take months to show results with big data monetization.
Do we need a whole in-house data team to get started?
Start with one person who understands both business problems and technical solutions. External consultants handle specialized work while internal teams learn the basics. Hybrid approaches work better than pure outsourcing or pure internal development. Build internal knowledge gradually instead of trying to hire an entire team immediately. This is especially true for companies beginning their big data monetization journey.
What role do AI and machine learning play in data monetization?
Machine learning automates decisions that humans currently make slowly and expensively. Predictive models work when you have clear patterns in historical data. AI adds value by processing information faster than manual methods. Skip machine learning if simple rules solve the business problem effectively. This principle applies across all monetization strategies for data.


.webp)







