

The Strategic Imperative: Why Engineering Must Precede Analytics
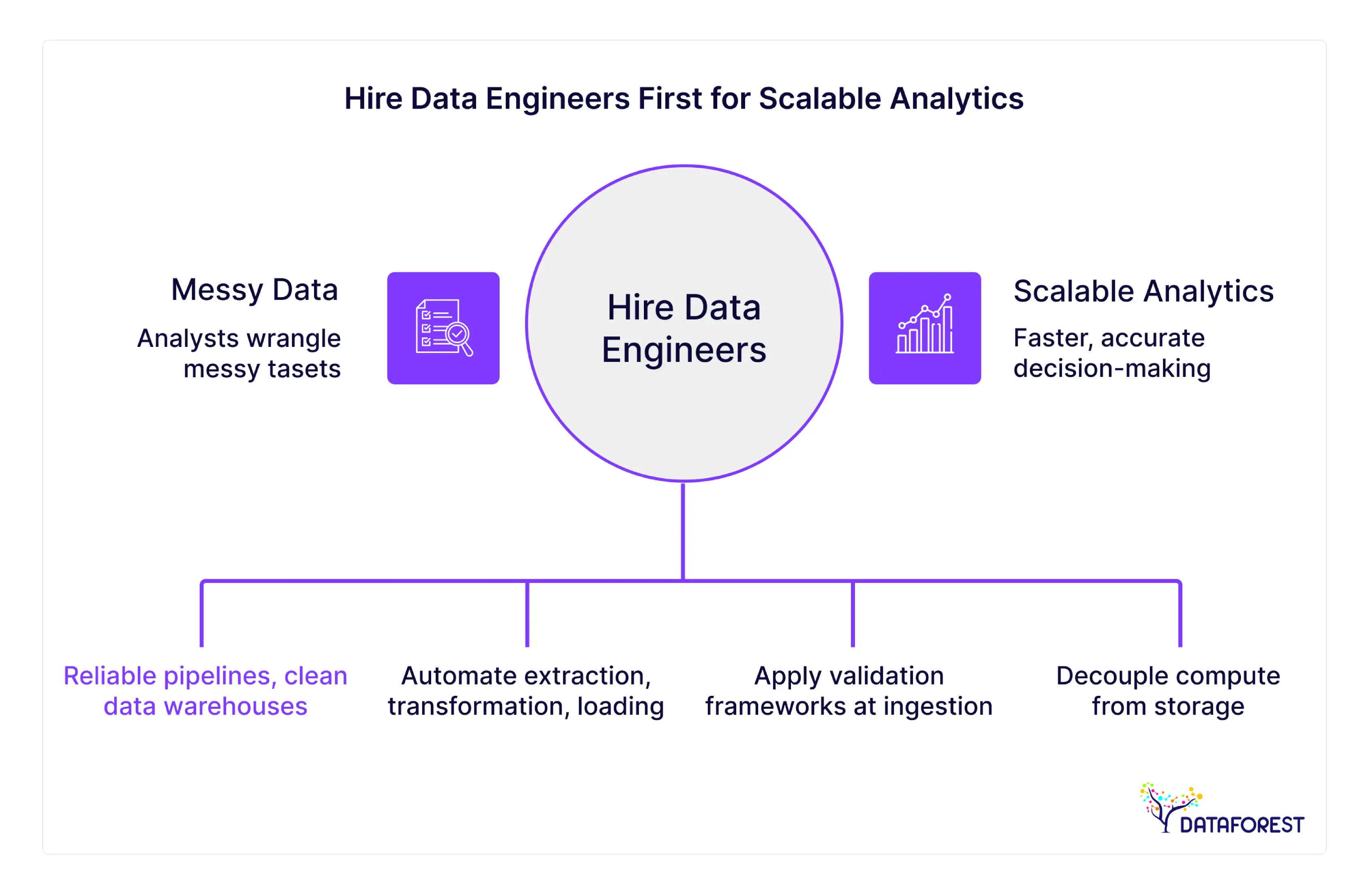
In the rush to become "data-driven," organizations often make a critical sequencing error. They view data science as the destination and analytics as the vehicle, often bypassing the road data must travel on: the infrastructure. Executives, eager for actionable insights, frequently prioritize hiring data scientists or business analysts. However, without a robust foundation, these high-value professionals spend the vast majority of their time wrangling messy datasets rather than generating value.
This is the paradox of modern business intelligence: to get better answers, you don’t initially need better analysts; you need better architecture. DATAFOREST has observed this pattern repeatedly across industries ranging from FinTech to Retail. The companies that win are the companies hiring data engineers before they ever look for a data scientist. They understand that to build data infrastructure correctly—with reliable pipelines, clean data warehouses, and automated governance—is not an IT concern, but a business continuity asset.
This article explores why the "engineering-first" approach is the hallmark of mature digital organizations and how companies that hire data engineers early secure a scalable analytics setup and a competitive advantage that lasts.
Why Hiring Data Engineers Early Is a Strategic Business Advantage
The decision to hire data engineers is often misconstrued as a purely technical hire. In reality, it is a strategic operational decision. When you bring in engineering talent early, you are investing in the integrity of your company’s decision-making capabilities.
They Get to the Root of Why Analytics Fail
That old chestnut “garbage in, garbage out” is a cliché because it is true, yet it is still the biggest reason analytics projects fail. According to Gartner, organizations lose an average of $12.9 million each year due to flawed data coverage and quality. This isn’t just about typos in a spreadsheet; it’s structural incoherence—mismatched schemas, redundant records spread across silos–and the null values that throw off forecasting models.
When you engage data engineers, backend developers and architects early on you are hiring the guardians of data quality. They apply validation frameworks at the ingestion point, so bad data will be flagged or corrected before it reaches any dashboard.
For example:
- A retailer, for example, could have point-of-sale data that suggests one revenue number and a CRM that shows another. A data engineer develops the logic for automatically reconciling these sources.
- In a healthcare setting, incorrect patient IDs can result in life threatening mistakes. Identity resolution pipelines are created by engineers to deduplicate patient records.
For a deeper dive into how foundational quality impacts outcomes, read about Data Readiness: Stop Building on Broken Foundations.
They Build a Scalable Infrastructure That Won’t Need Rebuilding Later
Startups and SMEs often rely on ad-hoc solutions—SQL scripts run locally, CSV files shared via email, or direct connections from a BI tool to a production database. This works for a team of five but collapses at a team of fifty.
Cloud data engineers design architectures (using platforms like Snowflake, Databricks, or BigQuery) that decouple compute from storage, allowing the system to handle petabytes of data just as easily as gigabytes. They anticipate future needs, setting up modern data architecture that accommodates new data sources without requiring a full system rewrite. This proactive approach to data platform development ensures the business can scale analytics, AI initiatives, and operational reporting without rebuilding infrastructure every few years.
A prime example of this foresight is utilizing a robust setup like the Databricks Architecture, which unifies data warehousing and data science capabilities.
They Free Analysts and Data Scientists from Manual Work
There is a widely cited statistic in the industry: Data Scientists spend 80% of their time cleaning data and only 20% analyzing it. This is a massive misallocation of resources. If you are paying a Data Scientist $150,000 a year, you are effectively spending $120,000 of that salary on janitorial data work.
By choosing to hire data engineers first, you flip this ratio. These professionals, acting as specialized ETL engineers and data engineering developers, automate the Extraction, Transformation, and Loading processes. They deliver clean, modeled tables to the analysts. This allows your high-level thinkers to focus on what they were hired to do: finding patterns, predicting churn, and optimizing revenue.
Direct Business Outcomes of Hiring Data Engineers Early
The ROI of data engineering is often harder to visualize than a flashy dashboard, but it is far more substantial. It manifests in operational efficiency and risk reduction.
Faster, More Accurate Decision-Making at the Executive Level
In volatile markets, latency is the enemy. If an executive has to wait until the end of the month for a manual report to be compiled, the window of opportunity to react to a market trend may have closed.
Data engineers build ELT pipelines that enable near real-time reporting. By integrating disparate systems—such as ERP, CRM, and marketing platforms—into a Decision Support System, engineers provide the C-suite with a "single source of truth." This eliminates the boardroom arguments over whose spreadsheet is correct and shifts the focus to strategy.
Lower Costs Through Automation and Reduced Manual Labor
Manual data reporting is a hidden tax on productivity. Consider a finance team that spends the first week of every month aggregating data from three different systems to close the books.
For example:
- Before Engineering: 4 employees x 40 hours/month = 160 hours of manual labor.
- After Engineering: Automated scripts run in 15 minutes.
DATAFOREST demonstrated this in a recent Reporting solution for the financial company case, where automation drastically reduced the time-to-report, saving the client thousands of man-hours annually.
Stronger Foundation for AI/ML, Forecasting, and Automation
Every modern company wants to leverage Artificial Intelligence. However, AI is not plug-and-play; it requires vast amounts of structured, historical data to train models. If you plan to hire a team of big data engineers later, you will find that you lack the training data necessary to build effective models.
Data engineers create "data lakes" or "lakehouses" that store raw history, ensuring that when you are ready for AI, your data is ready for you. Read more about the different layers of AI utility in our article: Three Types Of AI: Where Leverage Lives in the AI Stack.
Avoiding Technical Debt That Costs 2–3X More Later
Technical debt in data infrastructure behaves like high-interest financial debt. Building a "quick and dirty" solution today might cost $1. Fixing it two years later, when thousands of dependencies are built on top of it, will cost $10 or $100.
Companies that hire remote data engineers or on-site staff early avoid the "spaghetti code" of unmanaged SQL queries and undocumented dependencies. They build modular systems where components can be swapped out without bringing down the entire reporting infrastructure.

Why Starting With Analysts or BI Teams First Is a Common but Costly Mistake
The allure of immediate visualization leads many leaders to skip the engineering phase. This "dashboard-first" mentality invariably hits a wall.
Analysts End Up Doing Engineering Work They Aren’t Trained For
When you hire an analyst into an environment without engineers, they are forced to build their own pipelines. Often, they lack the software engineering best practices (version control, CI/CD, testing) required for robust systems. The result is fragile pipelines that break whenever a source system updates its API. This leads to burnout and high turnover among analysts who feel their skills are being underutilized.
BI Tools Become Useless Without a Proper Data Layer
Tools like Tableau, PowerBI, or Looker are powerful visualization engines, but they are poor data transformation engines. Connecting a BI tool directly to a raw production database slows down the application for customers and leads to slow, laggy dashboards.
Without a modern data stack setup managed by engineers, the BI tool becomes a bottleneck. In our Performance optimization (FinTech firm) case study, we corrected exactly this issue, optimizing query performance to make insights accessible in seconds rather than minutes.
Growth Exposes Weak Architecture
A manual process that works for 1,000 daily transactions will crash under the weight of 100,000. Scalable data systems are not accidental; they are engineered. If you wait until you are scaling to hire data engineers, you will likely have to pause product development to firefight infrastructure collapse—a scenario no CTO wants to face.
The Role of a Data Engineer — What They Actually Do for the Business
To the non-technical stakeholder, the data engineer is an invisible architect. Here is what they actually deliver to the business ecosystem.
Build Data Pipelines and Automate the Entire Flow
Data engineers are responsible for the movement of data. They build the ELT pipelines (Extract, Load, Transform) that move data from sources (like Salesforce, Shopify, or AWS S3) into a central destination. They ensure this movement is secure, compliant (GDPR/CCPA), and automated.
Ensure Reliability of Every Metric Used by Executives
Reliability Engineering is a core component of the role. Engineers set up monitoring and alerting systems (using tools like Airflow or dbt tests). If a data feed fails at 3:00 AM, the engineer knows about it and fixes it before the CEO checks the dashboard at 8:00 AM. This reliability builds trust.
Integrate All Business Systems Into One Unified Data Layer
Silos kill agility. Marketing data sits in HubSpot, financial data in NetSuite, and product data in Postgres. A data engineer creates the schema that links these entities.
For example:
- Linking a "Lead" in marketing to a "Transaction" in finance allows for accurate Customer Acquisition Cost (CAC) calculation.
- See how this integration supports complex sectors in our Finance Industry overview.
Enable Real-Time Visibility and Predictive Intelligence
Advanced engineering allows for streaming data architectures (using Kafka or Kinesis). This capability is essential for fraud detection, inventory management, and personalized user experiences. In our Stock relocation solution case, real-time data movement was critical for optimizing inventory across physical locations.
Medical Lab Achieves 50% Compute Savings via Databricks Migration
.webp)

Medical Lab Achieves 50% Compute Savings via Databricks Migration
When Exactly Should a Company Hire Its First Data Engineer?
Timing is everything. While "as soon as possible" is the ideal answer, there are specific triggers that indicate an immediate need to hire data engineers.
When Data Volume > Team Capacity
If your spreadsheets are crashing because they have exceeded the row limit, or if your daily SQL queries take more than an hour to run, you have a volume problem that only engineering can solve.
When Analysts Get Blocked by Data Prep
If your analytics team reports that they cannot deliver a Q3 forecast because the data is "too messy" or they are waiting on IT to export a file, it is time to bring in data engineering support.
When the Company Plans to Use AI, ML, or Automation
As discussed in our LLM Training article, AI models require specific data formatting and strict quality controls. If your roadmap includes AI, you need engineers to prepare the terrain 6-12 months in advance.
When Building Modern Data Stack or Going Through Digital Transformation
Transitioning from legacy on-premise servers to the cloud is a complex migration. This is the primary use case for data engineering consulting. It ensures the new architecture is cost-optimized and secure from Day 1.
In-House vs. Outsourcing: How Smart Companies Build Their Data Engineering Capability
Once the need is established, the question becomes: how to source this talent? The market for big data engineers is fiercely competitive, with demand far outstripping supply.
Pros and Cons of In-House Hiring
Hiring in-house offers total control and cultural alignment. However, it is expensive and slow. Recruiting a senior data engineer can take 4-6 months, and retaining them is difficult given the high turnover in the tech sector. Additionally, a single engineer may not possess the breadth of knowledge required across the entire stack (databases, cloud security, Python, Scala, etc.).
Benefits of Outsourcing to a Specialized Partner
Data engineering outsourcing allows companies to tap into pre-vetted talent pools immediately. Partners like DATAFOREST provide a full data engineering team that has already worked together and solved similar problems for other clients.
- Speed: Start building in weeks, not months.
- Expertise: Access to niche data engineering developers (e.g., Spark optimization or Redshift tuning) without hiring full-time specialists.
- Cost: Significantly lower TCO (Total Cost of Ownership) compared to building an internal department from scratch.
- Talent Availability: Finding data engineers for hire or to hire data engineers developers who are truly qualified is difficult; outsourcing bridges this gap instantly.
- Learn more about our approach at About Us.
Hybrid Models — Best of Both Worlds
Many mature organizations adopt a hybrid model. They hire a lead architect in-house to hold the vision and outsource data engineering execution to a dedicated remote data engineering team. This allows for scalability—you can ramp up the team during the initial build phase and ramp down during maintenance. Looking for a data engineering team for hire under a managed model is often the most efficient path to maturity.
The Strategic Pivot: Investing in Data Maturity
Ultimately, the decision to hire data engineers is a decision to treat data as an asset rather than a byproduct. Companies that ignore this layer of the stack eventually hit a "complexity ceiling" where they can no longer scale their operations efficiently.
By prioritizing engineering, you are not just buying code; you are buying the ability to move faster, decide with confidence, and deploy advanced technologies like AI before your competitors do. Whether you choose to build an internal team or partner with a data engineering team for hire, the critical step is to acknowledge that the foundation must come first.
The architecture you build today will dictate the speed at which you can run tomorrow.
Is your data infrastructure ready to scale, or is it holding you back?
Don't let technical debt stifle your growth. At DATAFOREST, we build the data engines that power industry leaders.
Book a consultation to discuss your data strategy today.
FAQ
How does a company know when it’s the right time to bring on its first data engineer?
The right time is often sooner than you think. Key indicators include analysts dedicating 50% of their time to data cleanup, having multiple “truths” across departments (e.g., Marketing and Sales have different numbers for revenue), and a reporting request that should be simple taking an absurd number of days because you need to manually collect data. A data engineer is necessary when planning to move to a cloud data warehouse.
What risks do companies face by delaying hiring a data engineer?
Pushing back on this hire results in “technical debt.” You run the risk of building analytics on brittle infrastructure that breaks once your data grows beyond a certain volume. The business risk is you make the wrong strategic decisions (bad data,) and it’s hard to build AI/ML initiatives because all your historical data was unstructured or incomplete.
Just how costly is bad data and manual processes for businesses?
Estimates vary, but according to research from Gartner Inc., poor data quality costs organizations an average of $12.9 million per year. Besides the direct cost, there’s the “opportunity cost” of manpower. If a team of five analysts take just 20 hours a week manually updating reports, that is 100 hours of lost productivity every week — approximately $250,000 to $500,000 per year in wasted salary.
How can a data engineer help a company scale its analytics without having to rebuild everything later?
Data engineers build modular architectures (based on modern paradigms, such as Data Mesh or Data Fabric) that decouple storage, compute and transformations. That means that when you need to switch visualization tools or add a new massive data source you don’t have to rewrite the whole system. They construct “idempotent” pipelines with ability to scale out in the presence of increased load, growing the system (and company) as a consequence.
When is it time for a startup to get a data engineer rather than continue with outsourced analytics?
If the product offering (recommendation), or regulations (HIPAA/GDPR) require data to be very strictly governed for internal use, they may consider making a full-time hire, or forming a dedicated remote team. But for most startups, it’s still more flexible to work with a data engineering outsourcing partner until the Series B or C stage.


.webp)







