

Factored AI partnered with a global enterprise to overhaul their Databricks environment. The team cut cloud processing costs by 90% and reduced workflow times from 2 hours to 10 minutes. Engineers improved Spark performance and moved non-critical workloads to spot instances. These changes saved money while supporting faster business decisions across the entire organization. DATAFOREST has engineers who can do the same, so schedule a call.
Why Are Your Databricks Costs Spiraling?
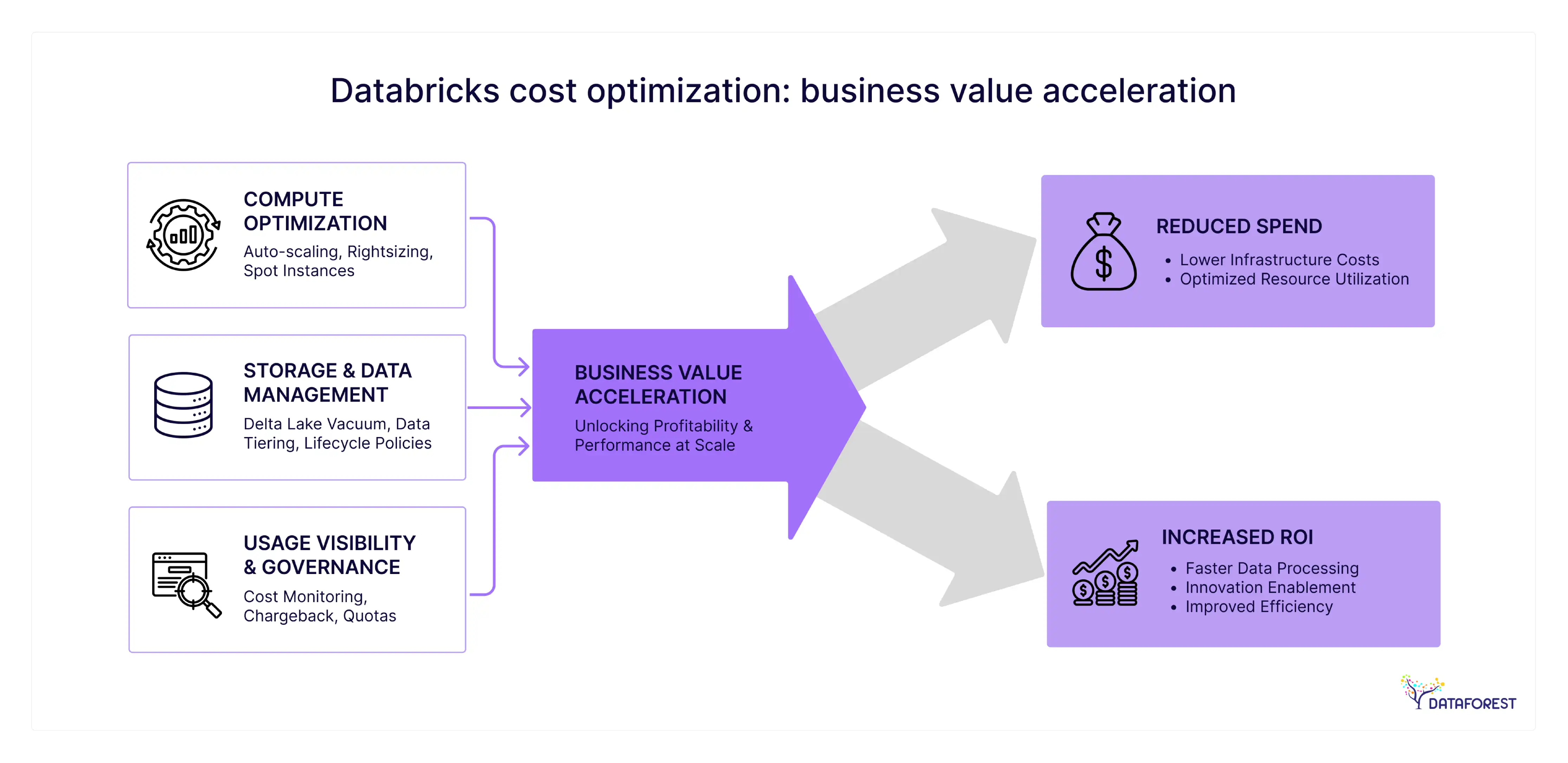
Cloud data platforms hide expenses behind complex tools and idle machines. These unpredictable bills drain budgets and force leaders to cut other vital projects. You can stop this waste by tracking usage and setting hard limits on every cluster—a core element of effective Databricks cost optimization strategies.
Hidden costs in cloud data
Modern data platforms connect many different tools across multiple cloud providers. Engineering teams often start new clusters without checking for existing computing resources. These idle machines stay active and bill the company for many hours. Data volume grows much faster than engineers can tune the underlying code for speed. Does this complexity cause waste? Yes, it creates high bills that arrive at the end of every month. A large firm loses 15% of its annual budget on idle compute power—a problem solved by disciplined Databricks cost optimization techniques.
Tracking data units for budgets
Databricks charges for every minute of data processing through its unit-based pricing model. Finance teams often struggle to predict these costs because usage fluctuates with data volume. A single poorly written query can consume hundreds of units in minutes. Does this make quarterly budgeting difficult for a CIO? It creates unpredictable bills that vary by 20% or more each month. Organizations fail to set hard limits on how many units a specific project can use. Without these controls, a single team might spend the entire department budget before the quarter ends. Teams must monitor these units daily to avoid large financial surprises at the end of the year, and that monitoring is a basic step in any robust Databricks cost optimization program.
Financial risk for leadership
Uncontrolled cloud spending creates a direct risk to the quarterly earnings of a company. A CTO may find that a project consumes its entire yearly budget in just four months. These sudden costs force leaders to pull funds from other critical technology initiatives. Does this lack of control damage the trust between the board and technical leaders? It creates a perception that the data department cannot manage its own operational expenses. Without clear cost limits, an enterprise risks losing its competitive edge to more efficient rivals. Executives must implement automated alerts to catch these spending spikes before they impact the bottom line—one of the practical Databricks cost optimization techniques that FinOps teams recommend.
Medical Lab Achieves 50% Compute Savings via Databricks Migration
.webp)

Medical Lab Achieves 50% Compute Savings via Databricks Migration
How Can You Turn Data Costs into Higher Profits?
Wasteful spending on cloud data drains funds that your team could use for new products. You can turn a cost center into a source of income by linking every dollar to a profit goal. Cleaning up old code makes your platform faster and more stable for every user. These are part of broader Databricks cost optimization strategies that convert waste into opportunity.
Connecting costs to revenue
Architects link every dollar spent on data to a specific profit goal. Leaders often pay for fast computing on tasks with no impact on sales. Does every automated job serve a customer or save the firm money? Many fail this test without clear rules. A large firm found 40% of their cloud tasks produced no profit. These facts allow the CTO to stop those tasks and fund new projects—a direct outcome of disciplined Databricks cost optimization.
Spending less to move faster
Companies that cut waste in their data budgets can reinvest those funds into new products. A lean data platform allows a business to test more ideas than its slower rivals. Does saving money on cloud bills give you a market edge? It lets your team ship features while competitors struggle with high maintenance costs. Efficient firms spend their time on innovation rather than fixing expensive errors in old code. This lower overhead helps the business survive and grow during tough economic times—another reason to adopt established Databricks cost optimization strategies.
Turning waste into better tech
Modernizing your data stack often begins with a goal to lower monthly bills. Engineers find that legacy code runs slowly and consumes too many cloud resources. Fixing these old scripts forces the team to adopt the latest automation tools. Do these updates make the platform more reliable for every user? Yes, cleaner code runs faster and breaks less often during peak hours. This shift turns a simple budget cut into a better foundation for future growth and is frequently achieved through concrete Databricks cost optimization techniques.
Deloitte warns that monthly bills for AI can reach millions if teams do not watch their scale. They suggest a hybrid model where some tasks stay in the cloud, and others move to local servers. This way, companies keep costs low while still having enough power for sudden needs. Finance leaders must treat cost control as a daily habit rather than a yearly chore.
Where Are You Losing Money in Databricks?
Idle machines and poor code drain your cloud budget every single day. The common errors slow down your projects and hurt quarterly profits. You can lower a monthly bill by fixing bad joins and setting strict limits—both are core Databricks cost optimization techniques.
Wasting money on idle machines
Engineering teams often choose large clusters for very small tasks. For example, these oversized machines sit idle for hours between different data runs. Your company pays for this empty time at the full price. Does your staff turn off these resources as soon as the work ends? They often forget to use auto-stop tools and waste thousands of dollars every month. Implementing auto-stop and tagging policies comprises part of any practical Databricks cost optimization strategy.
High costs from weak code
Poorly written Spark jobs process data multiple times and waste expensive computing power. Engineers write code that shuffles data across the network instead of keeping it in memory. For example, this movement of data causes slow runs and creates a high bill from your cloud provider. Does a small change in code save thousands of dollars each year? Yes, fixing a single bad join reduced one firm's monthly costs by 30%—a classic win from targeted Databricks cost optimization techniques.
The price of messy data architecture
For example, maintaining multiple copies of the same dataset across different cloud zones creates massive storage bills. Many firms keep every version of their data forever without a clear plan to delete old files. This clutter forces the system to scan through billions of useless rows during every search. Does a messy lake house slow down your entire business? It creates delays in reporting and increases the cost of every single query. Cleaning the lakehouse and applying lifecycle policies are standard Databricks cost optimization strategies.
No controls on spending
Firms lack clear rules for tracking their monthly cloud spending. Engineers often start expensive projects without any internal review or budget approval. Does your current system show you which specific team spent the most money yesterday? No, most leaders only see the total bill when it is too late to change it. A firm policy sets strict limits and alerts to stop this waste before it hurts your profits. These governance steps form the backbone of successful Databricks cost optimization techniques.
What Are the Steps to Lower Your Databricks Bill?
- Tracking every dollar: Leaders must first identify exactly which teams and projects generate the highest cloud bills. Architects apply tags to every cluster to track spending by department or specific product line. This process turns a single large bill into a clear list of expenses for each business unit. Teams then use these reports to find waste and hold managers accountable for their resource usage. This is the first step in most Databricks cost optimization strategies.
- Tuning your computing power: Architects must match the size of each cluster to the specific requirements of the data task. Teams switch non-critical jobs to spot instances to reduce hourly processing costs by up to 90%. Setting aggressive auto-stop timers ensures that idle machines don’t bill the company for unused time. The changes allow the business to run more workflows without increasing the monthly cloud budget. These are practical Databricks cost optimization techniques.
- Reducing storage waste: Engineering teams must implement a clear plan to delete or archive old data versions from the lakehouse. Removing duplicate files reduces monthly storage fees and speeds up search queries for every user. Architects use automated tools to find and purge datasets that the business no longer needs for daily operations. The company pays only for the information that creates real value—a standard recommendation in any Databricks cost optimization roadmap.
- Optimizing data jobs: Engineers must rewrite inefficient Spark code to prevent unnecessary data shuffles across the network. Modernizing the scripts ensures that processing stays in memory and finishes in a fraction of the time. Architects review execution plans to find and fix bottlenecks that cause high cloud bills. This step transforms slow, expensive workflows into lean processes that support faster business decisions. These job-level fixes are key Databricks cost optimization techniques.
- Automated financial controls: Leadership must integrate cloud spending rules into the daily operations of every engineering team. Automated alerts notify managers immediately when a project nears its monthly budget limit. The system prevents surprise bills by stopping unauthorized or expensive tasks before they finish. Establishing FinOps practices ensures that the data platform remains profitable as the firm grows. These governance measures are core to effective Databricks cost optimization strategies.

How Can You Cut Your AI and Machine Learning Costs
High costs for AI models often come from poor data management and expensive hardware choices. You can save money by using spot instances for training and centralizing your data features. These small changes allow your team to build more models without increasing the monthly bill—an important consideration for any company pursuing Databricks cost optimization.
Streamlining machine learning data
- Does your team re-run the same data every day? Use Delta Live Tables to process only new data instead of re-running entire datasets. This reduces processing time by 70% and keeps features fresh for your production models.
- Centralize features in a feature store to stop teams from building the same data twice. This saves your architects 20 hours of work every week and lowers storage costs. Models access these features faster during training.
- Reserve expensive GPU clusters only for final model training steps. Use standard CPU instances for initial data cleaning and feature creation to save 50% on hardware fees. This strategy stops high-cost resources from sitting idle during simple tasks.
Reducing model training expenses
- Does your staff use oversized machines for simple training tasks? Use small instances for initial tests and reserve large GPU clusters only for the final model runs. This stops your company from paying for idle computing power during the coding phase.
- Implement early stopping rules to end training runs that do not show better accuracy. This saves up to 40% on cluster costs by cutting off jobs that will never produce a useful result. Your team can then spend that budget on more promising experiments.
- Run hyperparameter tuning on spot instances to save 90% on hourly processing fees. These jobs can restart if the cloud provider reclaims the hardware, which makes them perfect for lower costs. This approach allows you to test more model versions within the same budget.
These are proven Databricks cost optimization techniques for AI/ML workloads.
Balancing speed and expense
- Does every model need second-by-second updates to provide value? Reserve real-time streaming only for high-stakes tasks like fraud detection, where a one-minute delay costs the business money. Moving non-urgent scoring to hourly or daily batch jobs can reduce your cloud infrastructure costs by up to 60%.
- Use micro-batching to strike a balance between system responsiveness and computing efficiency. This approach processes data every few minutes rather than instantly, which allows Spark to group tasks and lower the total unit consumption. You get fresh data for your users without the high price of an always-on streaming cluster.
- Measure the "value decay" of your data to decide which processing speed is truly necessary. Calculate how much profit the company loses if a prediction is 10 minutes old versus 10 seconds old. Enterprise analytics and reporting tasks maintain their full value even when processed in cheaper, scheduled batches.
All of the above feed into a company-wide set of Databricks cost optimization strategies.

How Can You Build a Cost-Conscious Data Culture?
Governance for cloud costs: Executives set clear financial goals and hold department heads accountable for their data spending. A central FinOps committee reviews monthly reports to align technology costs with business revenue. These leaders use automated dashboards to make quick decisions on resource allocation across the entire firm.
Tracking cost success: Teams measure success by tracking the cost per data job and the ratio of idle time to active processing. These metrics show leaders where cloud units produce results and where they are wasted. Data architects use these numbers to set benchmarks and reward teams for meeting budget goals—consistent metrics used in many Databricks cost optimization programs.
Changing team habits: Moving to a cost-conscious culture requires training every engineer to treat cloud units like a personal budget. Leaders reward teams for meeting performance goals and spending less on monthly data runs. This shift turns engineers from builders into owners who care about the financial health of the business.
Managing Your Databricks Investment
A formal audit is necessary when your monthly cloud bill increases by more than 20% without a clear increase in business output. Leaders should also review their environment before migrating major new workloads to the platform to prevent old inefficiencies from scaling up. Does your team see frequent alerts about clusters running over their budget limits? These warnings often signal that your underlying code or architecture needs a professional review. Regular audits every quarter ensure that your spending stays aligned with your actual revenue goals. Audits often reveal quick wins that become part of ongoing Databricks cost optimization strategies.
Choose what you need, book a call, continue in the right direction, and ask about our recommended Databricks cost optimization techniques during your consultation.
How Can You Convert Low Costs into Business Growth?
Reducing unnecessary cloud spending will free up the capital needed to fund high-impact machine learning models. These new funds allow your company to build advanced predictive tools that directly increase your market share and customer retention. This strategy turns a simple budget cut into a powerful engine for technological and financial growth.
A thin and optimized database allows your engineers to start new tests without worrying about sudden cost increases. This robust system provides the speed needed to test new ideas and deliver models faster than slower competitors. By eliminating technical debt and wasted resources, you create a "renewable workflow" where the company can focus on creating value—a promise fulfilled by sustained Databricks cost optimization strategies.
Forbes notes that firms waste over 30% of their total cloud budget on idle resources. Modern teams use AI tools to find and shut down machines that nobody uses. Executives now view cloud spending as capital that must produce a measurable return for the firm. They suggest shifting from long-term guesses to daily control of cloud power—a cultural shift central to long-term Databricks cost optimization.

How Does DATAFOREST Maximize Your Databricks Costs?
DATAFOREST provides specialized engineering expertise to remove hidden waste in your database. The team performs in-depth design reviews to identify large organizations and Spark workloads that don't need to increase monthly bills. By implementing automated FinOps management, we ensure that every cloud investment is monitored and aligned with specific business objectives. Engineers significantly reduce execution times by rewriting legacy code to reduce data clutter and maximize memory usage. They also help identify patterns of non-critical workloads, often reducing hourly rates by up to 90%. This integration transforms your Databricks environment from an unpredictable source of debt to a lean, scalable growth engine.
Please complete the form for your Databricks cost optimization.
Questions for Databricks Cost Optimization Techniques
What are the main reasons for increasing the price of Databricks in large companies?
Organizations run complex data pipelines and monitor entire systems. Permanent connections and large equipment often increase the cost of unused capacity. Poor tracking and weak rules can cause small mistakes to grow into huge monthly bills. Without proper cost optimization tools, companies struggle to control resource allocation and spending across multiple teams and environments.
What is the average percentage of savings that businesses can achieve by expanding?
Through integrated data management, companies reduce cloud spending by 20 to 40%. Companies can save up to 60% by using low-cost features, automatic company closings, and Databricks predictive optimization cost management strategies. They recover the cost of these changes within six months. These are realistic targets for effective Databricks cost optimization programs.
How will AI/ML workloads impact Databricks' cost structure?
AI and machine learning workloads require expensive GPU clusters to run for extended periods of time during model training. To effectively manage the lifecycle and costs of these advanced models, especially large language models, a dedicated platform for managing LLM operations becomes critical for controlling expenses and accelerating deployment. Accessing and moving large amounts of data in cloud environments adds high network and storage costs. Poor management of these testing areas can result in duplicated funds without clear business results. Proper Databricks cost optimization techniques mitigate these risks.
What is the role of FinOps in expanding Databricks?
FinOps teams use usage data to identify expensive and underutilized computing resources. They organize budgets and workloads to secure engineering departments for cloud computing. These experts compare technical performance with financial goals, so every data project has a clear bottom line.
Can upgrading Databricks not only improve performance but also reduce costs?
Enhanced data segmentation and indexing reduce scan times and speed up query execution. Small, well-balanced teams avoid resource conflicts and complete tasks faster than large, dysfunctional teams. These technological advances reduce monthly cloud bills and provide faster information for business users.


.webp)







