

A healthcare company utilized custom LLM training within AI-powered systems to develop a private AI model that processed patient intake forms, leveraging feedback from nurses who flagged errors and approved accurate responses. After six months, the AI reduced form processing time by 40% while maintaining data privacy, ensuring that all patient data remained within its network. The hard part wasn't the deep learning models or neural network architecture—it was getting busy nurses to review enough examples to make the model useful. If you think this is your case, then arrange a call.
Why Should Your Company Keep Training LLM Models In-House?
Public cloud-based AI platforms see everything you send them. That data trains their next version, and you lose control. Private AI models and in-house AI model deployment keep information internal, which is crucial when leaks can result in financial losses, compromised trust, or compliance penalties. AI model privacy compliance ensures control and confidentiality.
Privacy Is About Control
Models trained on your data learn patterns you didn't agree to share. Competitors could gain insights from aggregated training sets. Regulators fine companies when sensitive information is leaked, even if it is done accidentally. Customers stop trusting you when their details end up in someone else's system. Privacy gives you the option to decide what stays internal and what doesn't. This is a critical consideration in any AI model security strategy.
Custom Models Know Things Generic Ones Don't
Off-the-shelf models give average answers to average questions. A custom LLM training pipeline enables the model to learn the specifics that matter in a particular domain. It speaks the internal language, follows the exact workflow, and handles the edge cases that come up daily. Competitors using generic tools will sound generic. The advantage is precision that scales with machine learning optimization and AI model scalability. Training an LLM specifically for your domain builds a data-driven solution that outperforms generic tools.
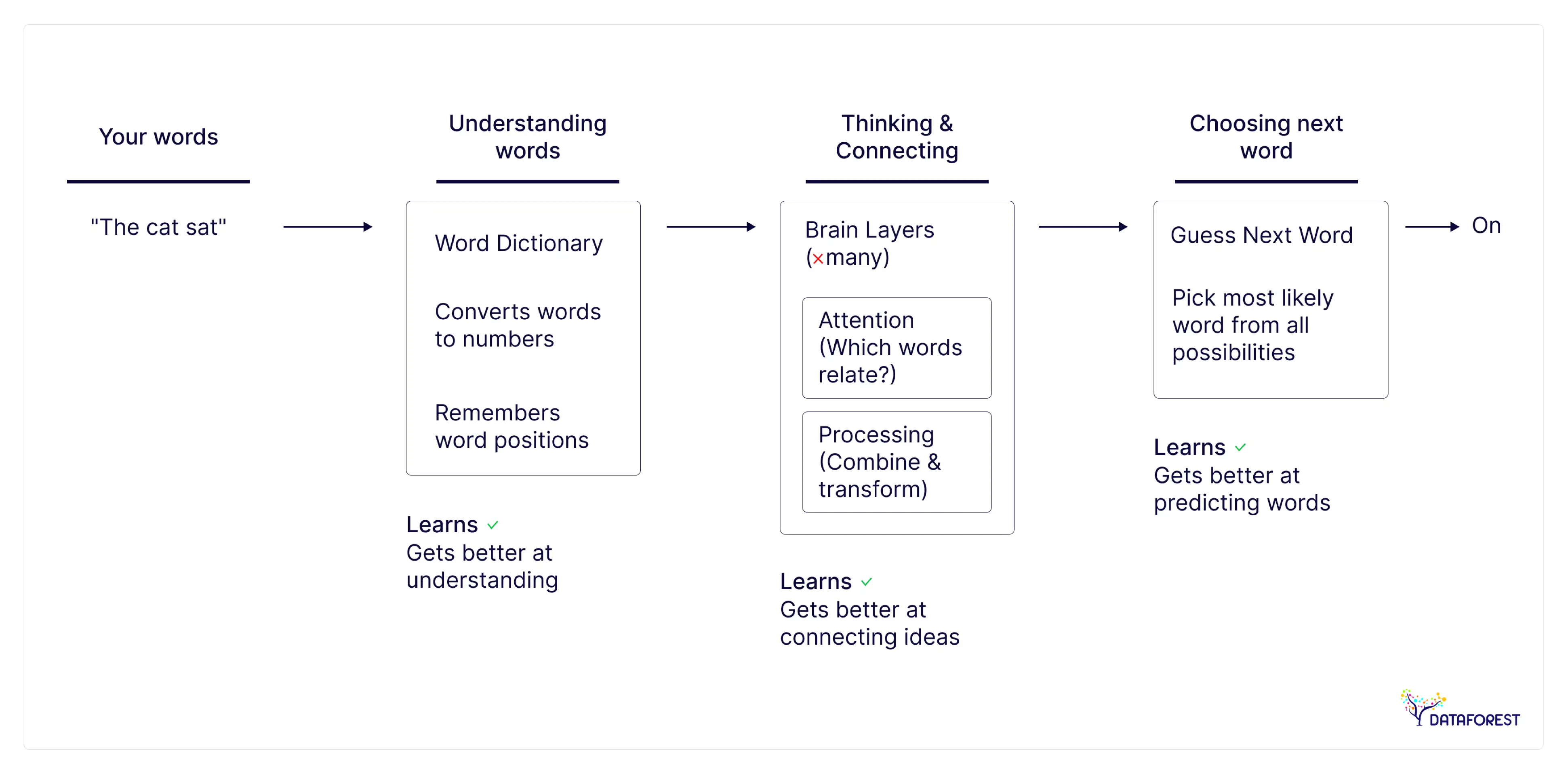
How Does Reinforcement Learning Make Private LLMs Useful?
Reinforcement learning in LLM training shows models what good looks like. The model generates answers. Humans rate them. The model adjusts toward higher-rated responses. Over thousands of examples, it learns preferences it couldn't extract from raw text alone. This is a key step in the supervised vs. reinforcement learning journey for enterprise systems.
Benefits of reinforcement learning for private LLMs:
- Learns company-specific quality standards through targeted LLM training: The model figures out what "good" means in your context, not someone else's.
- Catches mistakes humans care about using RL-based AI systems: It learns which errors actually matter versus which ones are just technically imperfect.
- Adapts to changing priorities through iterative LLM training: When business needs shift, you retrain with new feedback instead of starting over.
- Reduces hallucinations in your domain via AI model monitoring: The model learns when to be confident and when to hedge, based on real consequences.
- Builds institutional knowledge into the system for automated decision-making: Expert judgment is encoded, allowing it to scale beyond the individuals who provided it.
- Stays private during improvement with in-house LLM training: All feedback and refinement occur within your infrastructure, not on someone else's servers.
These benefits appear only when following proper LLM training methods.
LLM-Powered Recommendation System
.webp)

LLM-Powered Recommendation System
How to Train an LLM That Works for Your Business
Companies often get stuck when applying reinforcement learning algorithms, because the model learns something—but not what they need. Careful design of reward structures in RL and training data requirements determines whether months of work yield a valuable tool or an expensive mistake. These design decisions directly impact performance metrics for LLMs and overall AI model deployment success.
What Reward Structure Trains the Model Right?
The reward structure defines success in LLM training. You're encoding judgment calls into numerical scores. If you only reward correctness, the model becomes overly cautious and refuses to answer. If you reward confidence, it becomes more confident. You need to weigh multiple factors—accuracy, tone, format, and safety. You must balance accuracy, tone, format, and safety to ensure proper RL model convergence. Reward design is key to machine learning optimization and shaping predictive analytics outputs in real-world business intelligence applications.
How Do You Build and Tune a Private LLM for Reinforcement Learning?
Select a base model that works with your existing setup. Bigger isn't always smarter if your servers can't handle it. Use model fine-tuning techniques like LoRA or similar techniques in LLM training to update specific parts of the model instead of rebuilding it from scratch—this saves weeks of work. Learning rate is finicky. Set it wrong and the model either forgets everything functional or learns nothing new. You'll need ways to stop it from memorizing your feedback dataset instead of generalizing from it. Save versions as you go because half your experiments will make things worse. Whether this runs in your data center or needs rented GPUs depends mostly on model size and how patient you are. These are the practical considerations in training large language models.
When Does the Model Stick with Safe Bets Versus Try New Moves?
Training forces a choice at every step. Repeat what scored well before, or test something untried. During LLM training, each step requires choosing between repeating past wins or testing new moves. Early rounds need room to experiment. Tighten up once patterns emerge. Temperature controls how much risk the model takes during each run—narrow tasks, such as form parsing, benefit from locking in quickly. Open tasks, such as drafting emails, require looser constraints over a more extended period. These strategies are part of practical training for LLM operations.
Are You Actually Ready for a Private LLM?
Everyone wants AI-powered systems that offer control and privacy, but aligning the security, scalability, and continuous learning of AI models is challenging. Evaluate infrastructure readiness for end-to-end AI integration before deployment. Evaluating readiness is a key step in the LLM training process.
How Do You Keep Training Data from Leaking?
Run all LLM training on infrastructure you control. Cloud providers offer convenience, but it means someone else touches the data—Encrypt datasets at rest and during training runs. Limit access to the smallest group that can do the work—every extra person is a risk point. Audit what the model memorizes by testing whether it can recall training examples verbatim. Track who changed what and when, because breaches are often discovered months later. Compliance isn't optional in regulated industries, and fines exceed what the AI saves you. Security is a prerequisite in any training LLM models workflow.
Deploying Private LLMs the Right Way
Scalability isn’t just about throwing more GPUs at a model — it’s about making sure your fine-tuned, reinforcement-trained LLM performs reliably under real workloads. The deployment strategy must account for model size, inference latency, and concurrency limits, or else the whole "RL-optimized genius" will choke the moment users flood it with requests. Scalability depends on infrastructure aligned with LLM training outputs. Containerized serving stacks (like Triton + Kubernetes) allow horizontal scaling. AI model drift management and continuous testing prevent production failures. Caching frequent responses and batching inference requests massively reduce GPU burn without sacrificing accuracy. For privacy-critical environments, edge or on-prem deployment must be paired with secure update pipelines that allow gradual rollout of newer RL-trained checkpoints without downtime. Continuous evaluation under production traffic is essential because models that perform well in the lab can drift or exploit reward loopholes in the real world. Treat deployment like a living system — scale conservatively, monitor aggressively, and never assume the model will behave just because it passed your sandbox tests. These are the final stages of training large language models.
Don’t Let the Model Run Alone
Reinforcement-based LLM training isn’t a solo project—it demands tight collaboration between infrastructure teams, ML researchers, and domain experts. Without alignment on reward functions, deployment constraints, and failure scenarios, the model will optimize for the wrong outcomes and confidently deliver nonsense. AI/ML specialists should be embedded early to guide policy tuning, design guardrails, and evaluate evaluation loops, rather than being called in as a cleanup crew after deployment. Cross-functional reviews of training logs and user feedback help catch subtle behavioral exploits that neither pure developers nor managers would notice alone. Treat the model as a co-worker with unpredictable impulses—it takes a coordinated human team to keep it productive. This human coordination is a critical component of training LLM models.
Where Do RL-Trained Private LLMs Pay Off?
Not every industry needs an AI therapist or poetry bot—some just need a system that won’t leak data or hallucinate numbers. Reinforcement learning turns private LLMs from “smart autocomplete” into process-bound specialists that behave according to real business constraints. The question isn’t whether to use them, but where the ROI is undeniable. Training LLM with RL amplifies domain-specific value and reduces errors.
Select what you need and schedule a call.
Turning RL-Driven LLMs Into Measurable ROI
Demonstrating ROI with RL-driven LLMs means proving that the model doesn’t just sound intelligent—it moves measurable business metrics, instead of relying on vanity outputs like “response accuracy.” Real deployments track conversion lift, task completion speed, ticket deflection rates, or reduced human review time. Reinforcement learning makes this possible by tying the model’s behavior directly to rewards that reflect business value, not language elegance. When a healthcare assistant learns to escalate risky cases faster or an e-commerce model recommends products that actually get purchased, you can point to complex numbers—fewer errors, more revenue, lower operational drag. Monitoring these metrics is part of the LLM training steps to ensure business impact.
Why Training Private LLMs with RL Is Powerful — and Painful
LLM training with RL offers control but introduces complexity. But private deployments aren’t playgrounds—you're tuning autonomous systems inside strict business, security, and budget constraints. Below are the real blockers—and what it takes to get past them. These challenges illustrate that training large language models is as much about process as technology.
Data Quality and Availability
Treat data infrastructure as a product to strengthen LLM training results. Reinforcement learning is only as good as the behavior you reward—and if your data is noisy, biased, or incomplete, the model will learn the wrong habits with absolute confidence. In private settings, data is often fragmented across departments or trapped in legacy formats, making it difficult to build consistent feedback loops. Some teams mistakenly start training LLM models before defining who or what is allowed to provide reward signals. Reinforcement learning also struggles when positive outcomes are rare or long delayed—fraud prevention or complex medical decision-making. To address this, organizations must establish structured feedback pipelines, even if they are initially simulated or rule-based. Human-in-the-loop review can be layered strategically, not by manually labeling everything, but by targeting edge cases and low-confidence outputs. The solution is treating data infrastructure as a first-class product—not an afterthought.
Computational Resources and Cost Considerations
Private LLM training is expensive—especially when you’re hosting models privately instead of outsourcing the GPU bill to a public API. Iterative fine-tuning means running thousands of trial-and-error loops, and every reward rollout compounds compute usage. Teams often underestimate inference costs as well, assuming that training is the expensive part, when serving RL-enhanced models under heavy concurrency quickly becomes the real budget drain. Cost can spiral further if every experiment forks another checkpoint without lifecycle policies. To manage this, use parameter-efficient tuning techniques like LoRA or QLoRA, which cut GPU memory usage while retaining control. Set automated early stopping and reward plateaus to eliminate bad experiments quickly. Treat compute like a budget line item, not a bottomless buffet—because finance will treat it that way whether you plan for it or not. This is a core consideration in training LLM at scale.
Managing Model Drift and Continuous Learning
LLM training is continuous—over time, they adapt to shortcuts, exploit reward gaps, or slowly drift as real-world usage shifts. A model that excels in week one may start regurgitating outdated policies by week twelve if left unchecked. Private deployments are especially vulnerable, as deployment environments evolve more rapidly than public benchmarks. Too many teams assume “training complete” means “problem solved”—when in reality, reinforcement learning is closer to pet maintenance than model release. To address this, implement continuous evaluation against fresh user interactions and adversarial test cases. Maintain a shadow model for safe policy experiments before replacing production checkpoints. Treat drift not as failure, but as an expected side effect of autonomy—something to monitor, correct, and iterate on like any other living system. Continuous monitoring is part of the LLM training process.

Why Choose DATAFOREST for Your Private LLM and RL Needs?
You want more than model demos and buzzwords. You need a partner who delivers real value, with risks under control. DATAFOREST offers depth, accountability, and results—not promises. Their approach integrates LLM training with infrastructure, human feedback, and business metrics.
Expertise in AI/ML and Data Engineering
We’ve built production-grade LLM training systems with real-world data pipelines. Our engineers know how to clean, align, and integrate data from messy, real-world sources. We understand feature engineering, embeddings, fine-tuning, and system scaling. We don’t just throw models at problems—but also build pipelines, monitoring, and feedback loops. You get a team that sees both the math and the plumbing. This makes training large language models feasible in practice, not just theory.
End-to-End Solutions for Digital Transformation
From ingestion to deployment, our LLM training covers every phase. You won’t need to stitch dozens of vendors together. DATAFOREST handles everything from data ingestion and model training to inference, deployment, and governance. We build APIs, apps, and UIs that you can plug into your operations. We also integrate with your existing architecture; you’re not forced into a black box. When you request upgrades or changes, you speak with the people who built your stack. This covers every phase in the LLM training process.
Proven Track Record with C-Level Executives
We’ve worked directly with CEOs, CTOs, COOs—and survived the stress. We align LLM training with ROI, risk, and board-level expectations.. The team knows how to translate technical complexity into clear business metrics. DATAFOREST has delivered under pressure and accepted harsh scrutiny. You won’t get hand-wavy reports—you’ll get confidence from people who’ve faced decision deadlines and still executed. This experience ensures that training LLM models produces actionable business results.

Where RL Expands LLMs and Where It Breaks
Medium reports that reinforcement learning still thrives in robotics, optimization, and games. In 2025, interest grows in combining RL + LLMs (e.g., AI decision agents). But real-world constraints (safety, sample efficiency) limit adoption. Training through trial and error demands clear rewards, stable environments, and lots of data—three things most business use cases don’t offer. RL can improve reasoning, tool use, and multi-step decisions; however, scaling it often creates brittleness, cost spikes, or unusual model behaviors. The technology works best when paired with guardrails, human feedback, or tightly scoped domains, rather than open-ended tasks. The sweet spot is using RL to refine and steer models—not to reinvent how they learn from scratch. Please complete the form to make successful LLM training steps.
FAQ About Training LLM Features
What technique is used to train LLM?
Most start with supervised learning, then use RLHF as a second LLM training step. After that, reinforcement learning—usually with human feedback—is used to align behavior with goals or policies. In enterprise settings, RL can refine how the model responds, reasons, or follows constraints. These steps define the LLM training process.
How do private LLMs differ from open-source or public LLMs in terms of business value?
Private LLM training uses internal data, ensuring control, compliance, and relevance. They avoid IP leaks, vendor lock-in, and compliance risks tied to external APIs. The value comes from relevance, control, and security—not just model size. This is why training LLM models privately matters.
What types of enterprise data are most suitable for training a private LLM with reinforcement learning?
Structured logs, domain docs, and labeled outcomes—clean inputs yield better LLM training. Data with clear feedback signals—success, failure, escalation—helps define rewards. Messy or unlabelled text is usable only if you can extract intent and consequences. Proper LLM training methods require selecting the correct data.
How long does it typically take to train a private LLM with reinforcement learning?
Two to eight weeks, depending on feedback frequency and LLM training complexity. Full RL pipelines, including evaluation, iteration, and deployment, can span a quarter or more. Time depends on data quality, infrastructure, and the frequency of feedback loops. Scheduling is a key part of the LLM training steps.
Are there industries where private LLMs with RL are not recommended?
Sectors with strict auditability requirements—such as defense or high-risk healthcare—may limit RL because behavior shifts are more difficult to certify. Low-data industries with weak feedback signals gain little from complex RL pipelines. In some regulated environments, rule-based systems remain safer. Choosing where to apply training for an LLM is as vital as the technical setup. Where auditability is critical, LLM training may need guardrails or rule-based alternatives.
Is reinforcement learning suitable for fine-tuning smaller LLMs, or only large-scale models?
RL can work on smaller models if the task is narrow and the feedback is clean. Smaller models may even adapt faster because the weight space is limited. The trade-off is capacity—if the model can’t reason well to start with, RL won’t fix that. These considerations apply to all large language model training. Focused LLM training with clean feedback can yield strong niche models.

.svg)
.webp)







