

Your data team just spent three months building a pipeline that breaks every Monday morning. Your CEO is asking about AI. Your CFO wants to know why cloud costs tripled. And somewhere in the middle of those conversations, someone used the phrase "modern data architecture"—but nobody in the room could agree on what that actually means, let alone what to do about it.
This is the moment most enterprises realize their data infrastructure isn't just outdated. It's actively working against them.
This guide is written for technical decision-makers—CTOs, CDOs, VPs of Engineering—who need to make real enterprise data architecture decisions, not read another vendor pitch.You'll find a structured comparison of architecture patterns (data fabric, data mesh, data lakehouse), a scored platform selection framework covering AWS, Azure, GCP, Snowflake, and Databricks, a realistic total cost of ownership analysis, industry-specific architecture playbooks for healthcare, financial services, retail, and manufacturing, and an honest assessment of when modernization is premature.
One thing runs through all of it: the biggest risk in data architecture modernization isn't moving too slowly. It's moving without a framework. Book a call to stay ahead in technology.
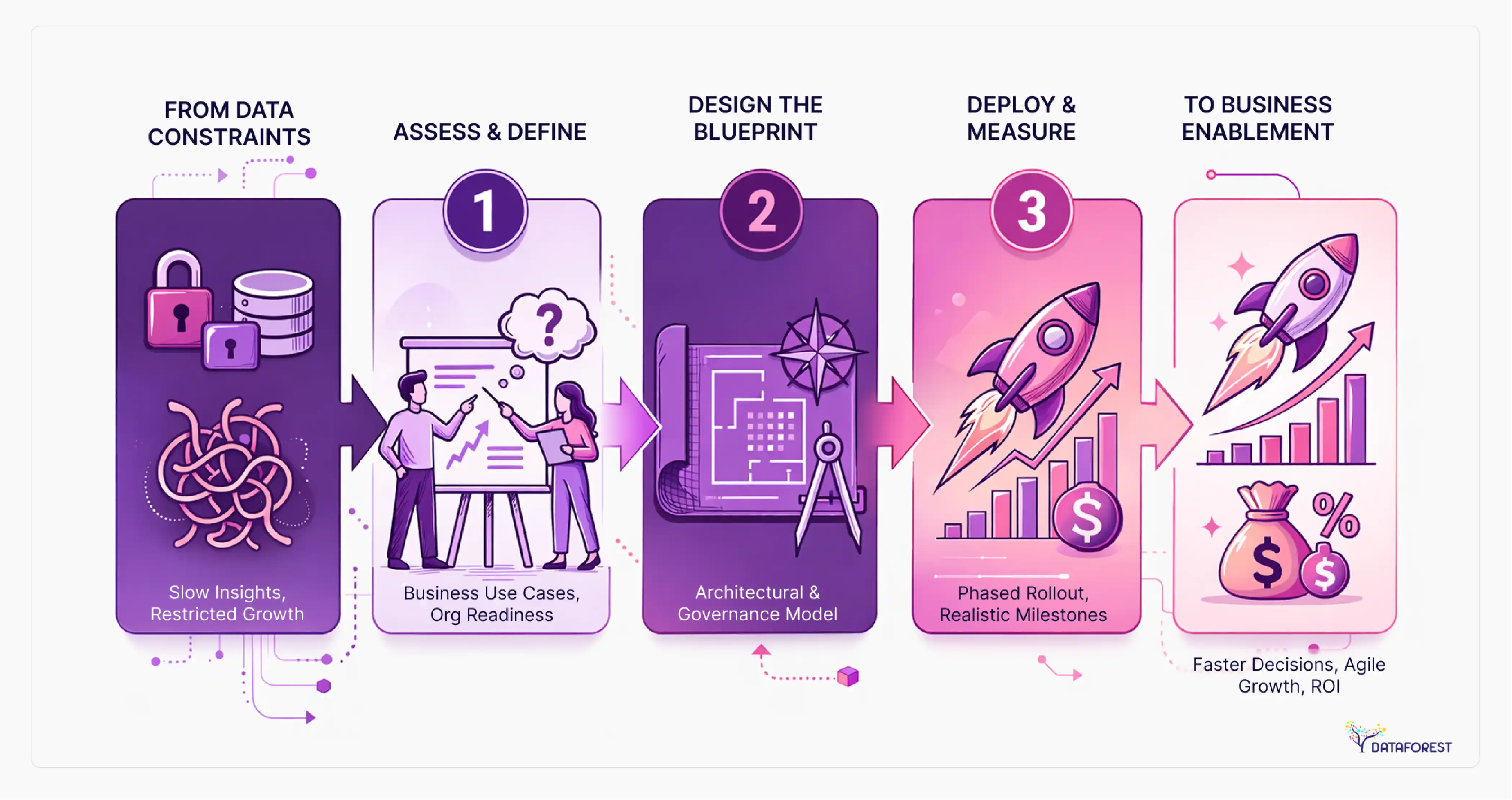
Key takeaways
- Architecture pattern selection (data fabric vs. data mesh vs. data lakehouse) should be driven by org complexity, data maturity, and team size - not by what's trending. For most enterprises, the right answer combines approaches.
- A well-optimized data warehouse is genuinely the right answer for some organizations. Premature migration to a lakehouse or mesh architecture creates technical debt that can outlast the original problem.
- McKinsey reports that organizations that adopt the right data architecture archetype can cut implementation time in half and reduce costs by about 20% when scaling new systems.
- Deloitte writes that data architecture must integrate ingestion, transformation, monitoring, and governance into a single platform. It calls this model 24/7 data architecture, supporting streaming analytics and operational AI.
- Forbes notes that the enterprise data platform market is projected to grow from $111.3B in 2025 to $243.5B by 2032. Open-source and cloud architectures are redefining enterprise data platforms. AI workloads increasingly determine architecture design.
Why your data architecture is costing you more than you think
DX market projected to expand from $911B in 2024 to $3.28T by 2030. Growth rate estimated at ~23.9% CAGR in some digital sectors. Digital transformation represents one of the fastest-growing segments of global enterprise spending.
A significant portion of that is companies trying to fix data infrastructure they should have addressed years ago. The math isn't complicated: legacy architecture wasn't designed for the volume, variety, or velocity of data that modern enterprises generate. It wasn't designed for AI workloads. And it definitely wasn't designed for the compliance requirements that have proliferated since 2018.
The cost of inaction compounds in two ways that most CFOs don't see clearly on a single line item. The first is direct: maintenance on legacy infrastructure, manual ETL processes that require constant babysitting, and the engineering hours spent keeping broken pipelines running. The second is opportunity cost—the analytics use cases you can't run, the AI features you can't ship, the operational decisions being made on stale data.
But here's the part that gets lost in vendor conversations: the cost of wrong action can be just as damaging. Organizations that rush into data mesh adoption without the organizational maturity to support it, or that build lakehouse infrastructure for analytics workloads that a well-tuned warehouse would handle fine, end up with expensive new problems layered on top of old ones.
The biggest risk in data architecture modernization isn't moving too slowly. It's moving without a framework.
BCG’s research identifies that future-built firms generate 1.7x more revenue growth than stagnating peers. They achieve 1.6x higher EBIT margins. A large multiformat retailer added 10% to its total EBITDA by applying AI across sales, pricing, and supply chain functions.
Reporting Solution for the Financial Company


Enra Group is the UK's leading provider and distributor of specialist property finance.
What modern data architecture actually means
"Modern data architecture" gets used to describe everything from a Snowflake migration to a full data mesh transformation. That's a problem, because the term has real meaning—and the differences between approaches have real consequences for cost, team structure, and technical complexity.
At its core, a modern data architecture has five functional layers that need to work together.
- Ingestion and integration handle how data enters the system—batch pipelines, real-time streaming (Kafka, Kinesis), and CDC (change data capture) from operational databases.
- Storage covers where data lives: object storage, data warehouses, data lakes, lakehouses.
- Processing and computing are where transformation happens—Spark, dbt, Flink for real-time workloads.
- Orchestration and governance manage scheduling, lineage, access control, and data quality validation.
- Analytics and serving deliver data to end consumers: BI tools, ML models, APIs, embedded analytics.
The evolution from legacy to modern architecture happened across roughly four eras.
- Monolithic data warehouses dominated throughout the late 2000s.
- Big data platforms and Hadoop-based lakes followed through roughly 2016.
- Cloud data lakes and early warehouse-as-a-service offerings took over through 2020.
- The current era involves lakehouses, data mesh, and data fabric convergence.
Understanding where you currently sit in that progression matters for scoping what modernization actually requires.
Data modeling fundamentals remain relevant across all of this. Conceptual models define what data entities exist and how they relate—they're business-language artifacts, not technical ones. Logical models translate those entities into structures (tables, schemas) independent of any specific technology. Physical models are the actual implementation in a specific database or storage system. Modernization projects that skip conceptual and logical modeling and jump straight to physical implementation almost always create governance problems later.
Data fabric vs. data mesh vs. data lakehouse: a decision framework
This is the question that generates the most confusion in architecture conversations, partly because the three terms describe things at different levels of abstraction. A lakehouse is a storage and processing architecture. A data mesh is an organizational and ownership model. A data fabric is a metadata-driven integration layer. They're not mutually exclusive - and for most enterprises, the answer involves combining them.
Comparing the three approaches
Choose what is important to you and order a call.
When to combine approaches
Most enterprises in the 1,000–10,000 employee range end up with a lakehouse as their foundational storage architecture, a data fabric layer for metadata, lineage, and access control, and mesh principles applied selectively to domains that have the team maturity to support product ownership. Attempting full data mesh adoption without a mature enterprise data architecture strategy almost always fails because it requires capabilities that take time to build.
The simplified decision logic: if your primary problem is storage cost and ML/BI fragmentation, start with a lakehouse. If your primary problem is data access across dozens of siloed domains in a large enterprise, evaluate a data fabric. If your primary problem is data ownership and quality at scale, and you have the org maturity to support it, consider mesh principles—but build incrementally.
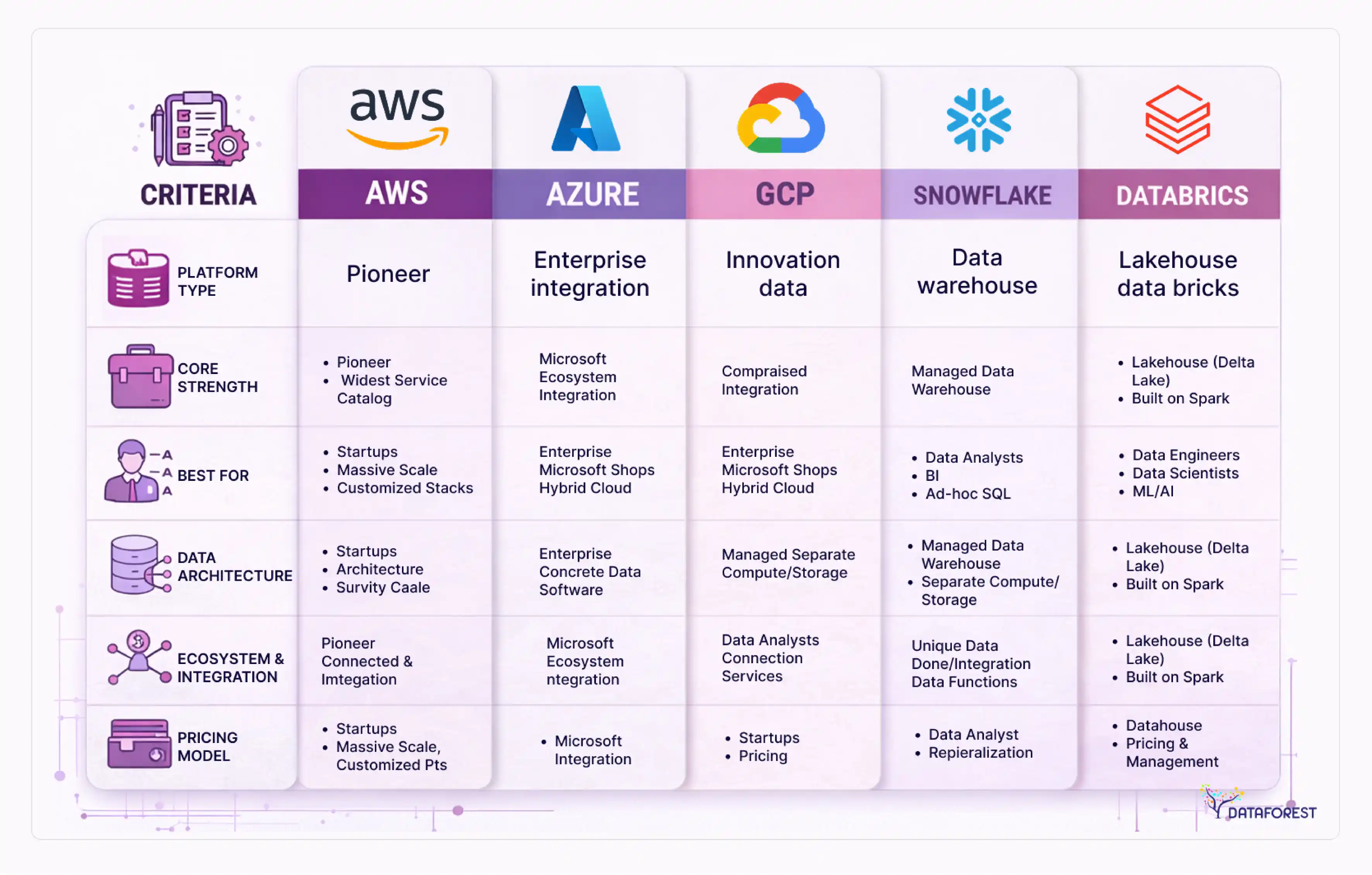
Cloud platform selection: AWS, Azure, GCP, Snowflake, and Databricks compared
Platform selection is often the specific decision that brings organizations to architecture consulting in the first place—and yet no competitor in this space provides a structured comparison. Here's a scoring framework across eight criteria.
Platform comparison scorecard
Best-fit scenarios
AWS suits organizations already deeply invested in the AWS ecosystem, particularly those running significant operational workloads on RDS, DynamoDB, or EMR. The integration between services is tight, but making sound architectural decisions to avoid runaway costs requires real expertise.
Azure Synapse and Microsoft Fabric are the natural choice for organizations standardized on the Microsoft stack: Office 365, Azure Active Directory, and Power BI. The Microsoft Fabric rollout consolidated many of these capabilities, though the platform is still maturing in certain areas.
GCP BigQuery remains the strongest option for organizations with primarily SQL-based analytics workloads and cost sensitivity on query volume. Its serverless model eliminates cluster management overhead, and Vertex AI integration is genuinely strong for ML use cases.
Snowflake's cloud-agnostic architecture makes it attractive for organizations operating across multiple cloud providers or those wanting to avoid full commitment to a single hyperscaler. It's consistently rated highly for ease of use by data analysts, though cost management at scale requires discipline.
Databricks is the strongest choice for organizations where data engineering and ML are primary concerns, particularly those running complex Spark workloads or building lakehouse architectures on Delta Lake. It's less suited for organizations whose primary use case is business intelligence.
For hybrid and multi-cloud environments, Snowflake and Databricks offer the most flexibility. AWS, Azure, and GCP all have hybrid extensions (Outposts, Arc, Anthos), but managing these correctly is substantially more complex than vendor materials suggest.
The real cost of modernization: a TCO framework
The most common mistake in building the business case for data architecture modernization is comparing the cost of modernization against zero. The real comparison is modernization cost versus the ongoing cost of your current architecture, including the costs that don't show up on a single line item.
Where savings actually come from
Compute savings are the most visible. Decoupling storage from compute—the foundational principle of cloud-native architectures—eliminates the need to provision compute capacity for peak load at all times. Organizations that make this transition typically see compute cost reductions of 30–50%. The range is wide because it depends heavily on current utilization patterns and workload spikes.
Storage savings are often larger but take longer to realize. Tiered lakehouse architectures, where hot, warm, and cold data sit on different storage tiers with different cost profiles, typically yield 60–80% storage cost reductions compared to keeping everything on high-performance storage. According to Forrester, cloud-native solutions reduce infrastructure spend by up to 40% overall—the storage piece is a major driver of that figure.
Labor savings are real but frequently overstated in vendor materials. Automated pipeline monitoring, self-healing architectures, and metadata-driven governance reduce manual intervention. Realistic labor savings run 20–35% for data engineering and operations work, with the caveat that this assumes the team's time is redirected to higher-value work rather than simply absorbed by new complexity.
The costs that are underestimated
Migration is consistently the most underestimated line item. Moving schemas, transforming historical data, validating pipeline outputs, and rewriting queries takes real time. A mid-sized enterprise data warehouse migration typically requires 3–6 months of focused engineering effort, not the 4-week estimates that appear in early project planning documents.
Training is underestimated differently—it's frequently budgeted for technical staff and not budgeted at all for the broader data consumer community (analysts, product managers, finance teams) who need to relearn how to access and use data after a migration. This gap creates adoption problems that delay ROI realization considerably.
Ongoing operations in a modern architecture require a different skill set than legacy operations—platform engineering, data product ownership, and observability tooling. If current staff don't have those skills, either training investment or new hiring is required, and neither is fast.
Three-year cost comparison framework
The data architecture modernization market was approximately $1.45 billion in 2026 (MarketReportsWorld), projected to reach $2.07 billion by 2035 at a 4.1% CAGR. That growth reflects enterprise recognition that the cost of staying on legacy architecture outpaces the cost of changing - but only when the change is executed with a credible framework.
Industry-specific architecture patterns
Generic architecture advice doesn't account for the compliance requirements, data volumes, latency needs, and team structures that differ significantly across industries. Architecture decisions that are correct for a retail company may be wrong for a healthcare system—and wrong in ways that create regulatory exposure, not just technical debt.
Healthcare
Healthcare data architecture operates under HIPAA's Security Rule requirements, which mandate specific controls around PHI (protected health information) at rest and in transit. HL7/FHIR standards govern interoperability between clinical systems. The practical consequence is that healthcare organizations need a governance layer with field-level encryption, comprehensive audit logging, and role-based access that satisfies both HIPAA compliance and clinical workflow requirements.
A lakehouse with a strong data fabric governance layer is typically the right pattern here. Real-time streaming is increasingly relevant for clinical decision support—patient deterioration alerts, sepsis detection. AWS (with HIPAA-eligible services) and Azure (with HIPAA BAA coverage) are the most common platforms. Common pitfall: underestimating the complexity of de-identification pipelines. HIPAA's Safe Harbor method requires removing 18 specific identifiers, and automated pipelines for this require careful validation and ongoing monitoring.
Financial services
SOX compliance requires audit trails on financial data transformations—every change, who made it, and when. Real-time fraud detection requires a streaming architecture with sub-second latency. Regulatory reporting (Basel III, FINRA) requires reproducible, point-in-time snapshots of data states.
A hybrid approach works best here: a real-time streaming layer (Kafka, Flink) feeding both operational fraud systems and a lakehouse for historical analysis. Strong lineage tooling—Atlan or Collibra—is non-negotiable for SOX compliance. Snowflake's Time Travel feature handles point-in-time regulatory queries well. Common pitfall: building separate architectures for real-time fraud and historical analytics, which recreates the exact data silo problem modernization is supposed to solve.
Retail and e-commerce
A mid-sized retail organization that implemented a unified lakehouse architecture for demand forecasting saw a 25% reduction in stockouts, 18% less excess inventory, and 40% improved forecast accuracy after migrating from a fragmented analytical environment (GeakMinds case study, anonymized). The enabling architectural requirement was unifying point-of-sale data, inventory data, and external demand signals—weather, events, competitor pricing—into a single platform with a consistent feature store.
Real-time personalization and demand forecasting have different latency requirements but share the same underlying data. A lakehouse with separate hot and cold serving layers handles both without duplicating the data estate.
Manufacturing and IoT
Edge computing is the distinguishing architectural factor here. Manufacturing IoT generates data at the machine level—CNC machines, PLCs, sensors—where full cloud round-trips create unacceptable latency for closed-loop control. The architecture requires edge processing (AWS Greengrass, Azure IoT Edge) for real-time control, with aggregated data flowing to a central lakehouse for predictive maintenance modeling and operational analytics. Common pitfall: treating manufacturing IoT as a simple data ingestion problem. Sensor drift, intermittent connectivity, and schema variation across machine types require significant data engineering investment before analytics are viable.

Architecture for the AI era
Every competitor in this space mentions AI readiness as a bullet point. None of them explains what it actually requires architecturally. "AI-ready data" isn't a vague property your architecture either has or lacks—it's a set of specific capabilities, and most current architectures are missing at least two of them.
Feature stores
Machine learning models train on features derived from raw data—aggregations, transformations, and embeddings. Without a feature store, data science teams rebuild the same feature computation pipelines repeatedly, inconsistently, and with training/serving skew, where the features used to train a model differ from what's available at inference time. Feature stores like Feast (open source) and Tecton (managed) solve this by providing a centralized registry of features with consistent computation across training and serving environments.
Vector databases
Retrieval-Augmented Generation (RAG) architectures—the most common pattern for deploying large language models on enterprise data—require a vector database for semantic search over embedded documents. Pinecone, Weaviate, and pgvector (for organizations already on PostgreSQL) are the primary options. The architectural decision that matters is where embeddings are generated and how they're kept in sync with source data. A lakehouse architecture that doesn't include a vector index layer is not AI-ready for RAG use cases.
MLOps pipelines
ML pipeline infrastructure—experiment tracking, model versioning, deployment, and monitoring—is often treated as separate from data architecture. It isn't. MLflow for experiment tracking and model registry, Kubeflow or Metaflow for pipeline orchestration, and data quality monitoring tools (Great Expectations, Monte Carlo) need to be considered as part of architectural design, not added later.
Agentic AI requirements
AI agents that take actions—not just generate text—require data architectures with strong access controls, comprehensive audit logging, and real-time data APIs. An agent that can query customer data, trigger fulfillment actions, and update records creates data governance challenges that batch-oriented architectures aren't designed to handle. Organizations building toward agentic AI applications need to think about data architecture in terms of APIs and real-time access patterns, not just analytics queries.
The modernization roadmap: 5 phases with deliverables and timelines
The most common criticism of modernization roadmaps is that they describe what to do but not what it produces or how long it takes. According to Dresner Advisory, organizations that engage specialized consulting partners achieve modernization timelines that are 2x faster than those attempting the same work internally. That gap mostly comes from phases 1 and 2—the discovery and strategy work, where experienced practitioners can move quickly because they've already seen the patterns.
Phase 1: Discovery and assessment (2–4 weeks)
Deliverables: current-state architecture inventory, data maturity assessment, prioritized problem statement, catalog of existing data sources and systems, assessment of current pipeline reliability and data quality, identification of the 3–5 highest-value use cases for modernization, readiness assessment of data team capabilities.
Decision gate: Do the identified use cases justify the investment? What's the minimum viable architecture that addresses the top-priority use cases?
Phase 2: Strategy and architecture design (4–6 weeks)
Deliverables: architecture decision records (ADRs) documenting technology choices and rationale, reference architecture diagram, platform selection recommendation with TCO analysis, governance framework design, and phased implementation plan.
Decision gate: Has the architecture design been reviewed by the engineers who will implement it? Are governance requirements mapped to specific tooling?
Phase 3: Foundation build (2–3 months)
Core infrastructure is established: storage layer, compute configuration, ingestion pipelines for priority data sources, initial governance tooling, CI/CD for data pipelines. This phase should not attempt to migrate existing use cases. Its purpose is to build the platform that migrations will run on.
KPIs at end of phase: core infrastructure running, at least one end-to-end pipeline in production, governance tooling active, data team trained on new stack.
Phase 4: Migration and integration (3–6 months)
Existing workloads migrate to the new platform—starting with lower-risk, lower-complexity use cases. Each migration should include validation against the source system before decommissioning. This is also where legacy infrastructure decommissioning begins, which is when cost savings actually materialize.
Common failure mode: treating migration as a pure technical exercise and underinvesting in stakeholder communication. Data consumers—analysts, product managers, finance teams—need to know what's changing, when, and how it affects their workflows.
Phase 5: Optimization and scale (ongoing)
Query optimization, cost governance, automated observability, and architectural improvements based on production experience.
This is the phase where that investment becomes practical and measurable.
The Global Data Observability Market Report shows the rapid growth reflects increasing demand for automated monitoring of complex data pipelines.
Modernization readiness checklist
Before committing to a full modernization program, verify each of these:
- Executive sponsorship is confirmed—not just a data team initiative
- Current architecture pain points are documented with business impact, not just technical complaints
- At least 2–3 specific, high-value use cases are identified to anchor the program
- The data team has (or can acquire) skills in the target technology stack
- A governance framework design is part of the architecture plan, not an afterthought
- Migration validation methodology is defined before migration begins
- The stakeholder communication plan covers data consumers, not just the data team
- Phase 3 (foundation) and Phase 4 (migration) are funded separately
- Legacy decommissioning timeline is realistic: plan for 12–18 months of parallel operation
- Success metrics are defined and measurable before the program starts
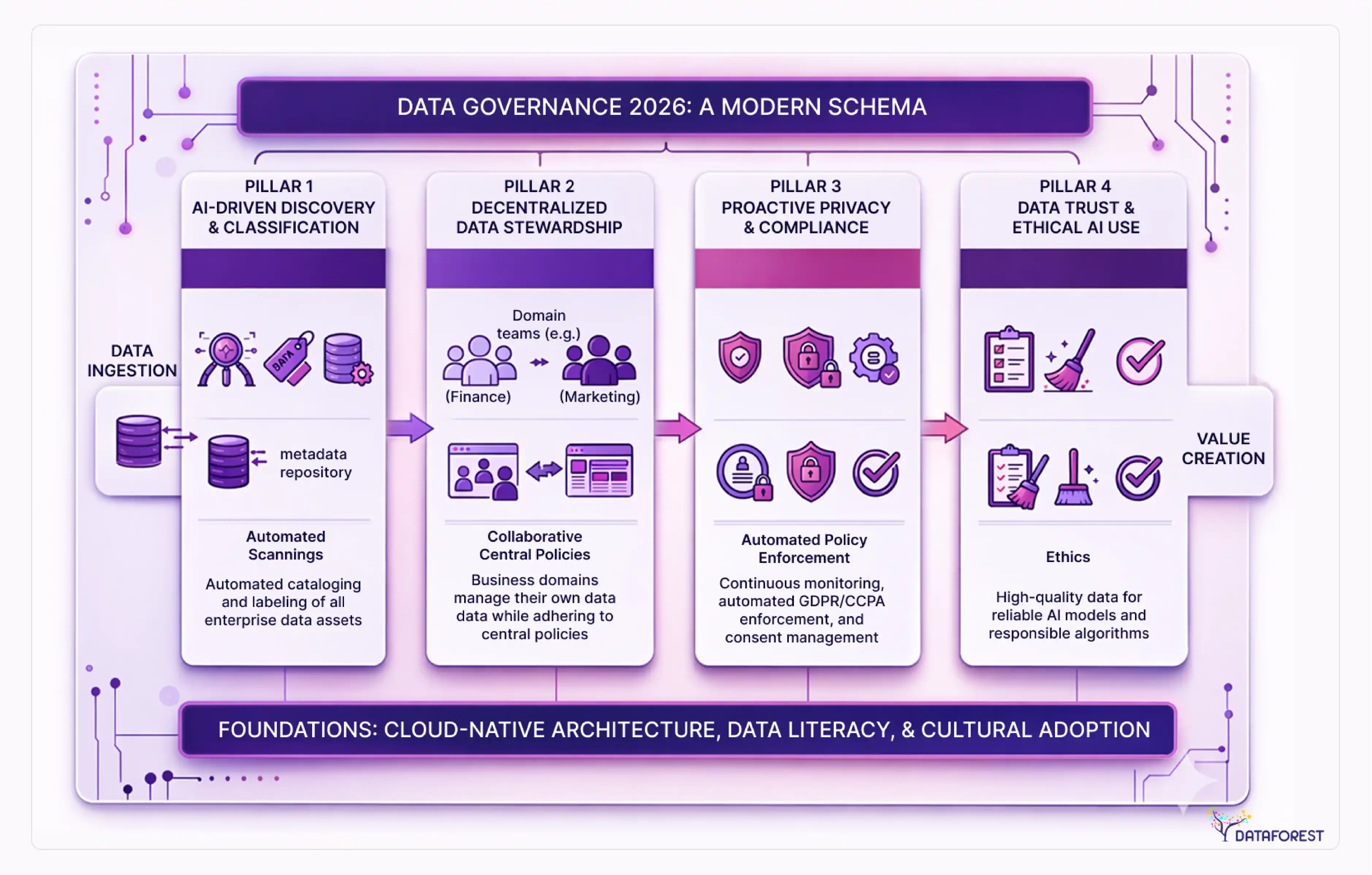
Data governance in 2026: from compliance checkbox to competitive moat
Gartner predicts that 80% of data governance initiatives will fail by 2027 without active management. The reason most of them fail isn't a lack of tooling—it's that governance gets designed as a gate that slows things down rather than infrastructure that makes things faster.
Modern automated governance inverts that relationship. Data contracts—formal agreements between data producers and consumers about schema, quality, and SLA—catch breaking changes before they hit downstream consumers rather than after. Policy-as-code frameworks translate compliance requirements into automated checks that run in CI/CD pipelines, so compliance validation happens at the same time as code review rather than in a quarterly audit. Automated lineage tools like Atlan, Alation, and Collibra track data from source to consumption, making impact analysis—"what breaks if I change this table?"—a query rather than a two-week investigation.
The regulatory environment makes this non-optional. GDPR's right to erasure requires knowing exactly where a data subject's information exists across your entire data estate—which is impossible without lineage. The EU AI Act's requirements around training data documentation for high-risk AI systems create governance requirements that most current architectures can't satisfy. CCPA's evolving scope continues to expand the categories of information that require consent and deletion capabilities.
The competitive advantage is this: organizations with mature automated governance ship new data products faster because they can trust their data infrastructure. The teams that spend the least time on data quality firefighting are, almost uniformly, the ones with the strongest governance foundations.
The data integration market was $17.58 billion in 2026 (MarketsandMarkets) and is projected to reach $33.24 billion by 2030 at a 13.6% CAGR—driven in large part by the demand for governed, interoperable data infrastructure at scale.
What a consulting engagement actually looks like
Nobody in this space explains what engaging a data architecture consulting firm actually involves. That opacity creates anxiety in buying decisions and causes organizations to either underbuy (expecting too much from an advisory-only engagement) or overbuy (paying for implementation work they could handle internally with better tooling).
The biggest risk in data architecture modernization isn't moving too slowly. It's moving without a framework—and the framework for evaluating consulting engagements matters just as much as the framework for selecting architecture patterns.
Three engagement models
- Advisory engagements (typically 4–12 weeks) deliver architecture assessments, technology recommendations, and roadmaps. The client's team does all the implementation. This works well for organizations with strong internal engineering capability that need an outside perspective and pattern-matching from practitioners who've seen similar problems.
- Implementation engagements (typically 3–12 months) involve the consulting firm doing or co-leading the technical work. This is appropriate when internal teams lack specific technical skills—Spark optimization, dbt modeling at scale, Kafka cluster management—or when speed matters enough to justify external resourcing.
- Managed services (ongoing retainer) cover ongoing platform operations, optimization, and evolution. This works for organizations that want to maintain a lean internal data team while keeping a modern platform running.
How to evaluate a data architecture consulting partner
Ten criteria that distinguish capable partners from generalists:
- Can they show reference architectures for your industry's specific compliance requirements?
- Have they delivered migrations of comparable scope? Ask for specific timelines and outcomes - not ranges.
- Do they have hands-on experience with the specific platforms in your shortlist, or a generic "cloud experience"?
- What does their governance and handoff process look like? Does the engagement create dependency or build internal capability?
- Can they articulate the risks and failure modes of the approach they're recommending?
- Do they discuss scenarios where modernization isn't the right answer, or is everything a nail?
- What are their quality gates and validation methodology for migrations?
- How do they structure knowledge transfer to your internal team?
- Do they have a data engineering practice separate from their architecture/strategy practice?
- Can they provide references from clients who have been in production for 12+ months post-implementation?
Red flags: vague answers to questions 2, 4, 6, and 7. References only from implementations in the last 6 months. Architecture recommendations that don't vary based on your specific constraints.

5 signs you're not ready to modernize
Every vendor in this space is selling modernization. Nobody discusses when it's premature—which is, ironically, exactly the kind of candor that should inform your trust in architecture advice.
The biggest risk in data architecture modernization isn't moving too slowly. It's moving without a framework—and no framework can substitute for honest organizational readiness. Here are five signals that a modernization program will struggle.
1. You don't have a data team; you have a data person. Data mesh adoption requires domain teams that can own data as a product. A lakehouse migration requires data engineers who can manage distributed storage, compute, and pipeline infrastructure. If your current data capability is one analyst and a shared BI license, modernization will outpace your organization's ability to operate what gets built.
2. You can't name three specific use cases that modernization enables. "We need better data" is not a use case. "We need to run propensity models on customer transaction history without a 3-day pipeline lag. If the modernization program can't be anchored to specific, measurable outcomes, it will get deprioritized when competing priorities emerge—which always happens.
3. Your data quality problems are unsolved upstream. A modern data architecture with poor source data quality is just a more expensive way to produce the wrong answers faster. If your operational systems generate duplicate records, inconsistent categorizations, or missing values at scale, that problem needs to be addressed before architectural modernization amplifies it.
4. You don't have executive sponsorship above the data team. Architecture modernization programs that live entirely within the data team fail at the organizational change management phase—when migrated systems affect workflows that business stakeholders rely on. CDO-level or above sponsorship isn't bureaucratic overhead; it's what makes change management possible.
5. Your current warehouse is fine. A well-tuned Snowflake or Redshift warehouse with good dbt modeling and a solid governance layer is the right answer for many organizations. If your primary workloads are structured SQL analytics, your data volumes are manageable, and you don't have near-term ML requirements that exceed what warehouse ML integrations can handle, full lakehouse migration is a solution looking for a problem.
Common over-engineering mistakes
Adopting data mesh for a 15-person data team (it requires organizational scale to justify its overhead). Building a real-time streaming infrastructure for use cases where an hourly batch would suffice. Migrating to a lakehouse while keeping a separate warehouse—ending up with higher costs and more complexity than either architecture alone.
Data Architecture—From Constraints to Growth
Modern data architecture consulting is a specific, bounded problem: help an organization move from a data infrastructure that constrains its business decisions to an infrastructure that enables them. The decisions involved—which architectural pattern, which platform, which engagement model, which governance approach - are all answerable with a systematic framework. They're not answerable with generic advice.
The organizations that get this right tend to share a few characteristics. They start with use cases, not technology. They invest in governance as infrastructure rather than process. They're honest about organizational readiness before committing to architectural complexity. And they treat the modernization program as a business transformation, not a technology project.
If you're evaluating modern data architecture consulting engagements, the questions that reveal the most about a firm's capability are the uncomfortable ones: when would you advise against this? What are the conditions under which this approach fails? What does a realistic 18-month outcome look like, not a best-case one?
Please complete the form—we’ll tell you more than any reference architecture slide.
References
- IDC. (2026). Global digital transformation spending forecast. IDC Research.
- McKinsey Global Institute. The age of analytics: competing in a data-driven world. McKinsey & Company.
- Forrester Research. Cloud-native architecture cost reduction analysis. Forrester.
- Gartner. Predicts 2025: data management governance initiative failure rates. Gartner Research.
- MarketReportsWorld. (2026). Data architecture modernization market: size, share, and forecast. MarketReportsWorld.
- MarketsandMarkets. (2026). Data integration market - global forecast to 2030. MarketsandMarkets.
- Ventana Research / ISG. (2025). Data observability investment trends 2026. ISG Research.
- BCG. Advanced analytics and revenue growth benchmarks. Boston Consulting Group.
- Dresner Advisory Services. Data modernization timelines: internal vs. external delivery. Dresner Advisory.
- Forbes / IDC. The datasphere: 175 zettabytes and the utilization gap. Forbes Technology Council.


.webp)
















