

According to BCG's analysis of more than 850 companies, only 35% of digital transformation projects succeed. In data architecture specifically, the numbers are worse. According to NewVantage Partners, 98.8% of Fortune 1000 companies are investing in data initiatives—yet only 37.8% have built genuinely data-driven organizations. The gap between investment and outcomes isn't technology. It's the approach.
Most data architecture guides tell you what options exist. This one tells you how to choose between them, how to implement them in phases, what breaks them, and what they actually cost. Whether you're modernizing a legacy warehouse, evaluating a move to a lakehouse, or considering a data mesh, the decisions you make in the design phase will determine your outcomes more than any tool you select.
You'll come away with a concrete maturity assessment to diagnose your current state, a framework for choosing the right architecture pattern for your organization's specific constraints, a 90-day implementation roadmap, and a catalog of the anti-patterns that kill these projects before they deliver value.
Key takeaways
- Most architecture projects fail because organizations adopt patterns—data mesh in particular—before their governance foundations are ready to support them.
- Poor data quality costs organizations $9.7–15M per year, according to Gartner, making the cost of architectural inaction measurable and significant.
- The right architecture pattern depends primarily on your data volume, team maturity, and compliance requirements—not on what the largest tech companies use.
- A phased 90-day approach to implementation consistently outperforms big-bang migrations, particularly for mid-market organizations with limited data engineering capacity.
- AI-readiness isn't a separate architectural concern—it depends directly on decisions you make today about storage formats, metadata richness, and lineage tracking.
What data architecture is—and why most implementations fail
Data architecture is the set of rules, policies, standards, and models that govern how data is collected, stored, processed, and used across an organization. It covers everything from how raw events land in your ingestion layer to how analysts query a semantic layer to how ML engineers access training data.
The definition is simple. The execution isn't. According to Statista, global data volume reached 181 zettabytes in 2025, up from 33 zettabytes in 2018. Organizations average 897 applications, and according to MuleSoft (2025), only 29% of those are integrated. The practical result: fragmented data, duplicated pipelines, inconsistent definitions of the same business metrics across teams, and engineers spending 30–50% of their time on maintenance rather than building.
Here's what's actually happening in most organizations. Teams identify a problem—slow queries, siloed reporting, poor data quality—and jump to selecting a pattern or tool. They evaluate data mesh, read the Airbyte blog, buy a catalog license, and start migrating workloads. Eighteen months later, the mesh has produced three domain teams with incompatible schemas, the catalog is 40% complete and already out of date, and the original query performance problem is unresolved.
The pattern selection wasn't wrong. The sequence was. Effective data architecture follows an Assess → Design → Build → Optimize journey. Every section of this guide follows that order.
Assessing your data architecture maturity before you design anything
The single most common mistake in architecture projects is designing for where you want to be rather than building from where you are. A maturity model fixes this by giving you an honest baseline.
The framework below adapts the DAMA-DMBOK maturity dimensions across five levels. Score your organization honestly across governance, technology, people, and processes.
The 5-level data architecture maturity model
Using this scorecard: Rate each dimension 1–5. Average your scores. A score of 1–2 means your immediate priority is governance and pipeline stability—not pattern selection. A score of 3 means you're ready to design target architecture. A score of 4–5 means you're optimizing an already-functioning system and can evaluate advanced patterns like data mesh or data fabric.
This step matters because it changes which advice applies to you. An organization at Level 2 implementing data mesh is almost guaranteed to fail. The same organization implementing a well-governed data warehouse with clear ownership and quality checks will likely succeed.
Modern data architecture patterns—selection criteria and a decision framework
There is no universally correct architecture pattern. The right choice depends on your data volume, velocity, team size, compliance requirements, and maturity level. Here's an honest comparison of the major patterns.
Core patterns at a glance
A data warehouse stores structured, processed data optimized for analytical queries. Appropriate for organizations with well-understood, stable schemas and primarily SQL-skilled teams. Tools: Snowflake, BigQuery, Redshift.
Data lake stores raw data in native format, enabling flexible processing. Lower cost per GB, but requires significant engineering discipline to prevent "data swamp" deterioration. Tools: S3 + Delta Lake, Azure Data Lake Storage.
Data lakehouse combines warehouse query performance with lake storage flexibility. Apache Iceberg and Delta Lake provide ACID transactions on object storage. According to research cited by Dataversity, the lakehouse market is growing at 22.9% CAGR toward $66B+ by 2033.
Lambda architecture separates batch and real-time processing into distinct layers. Operationally complex but powerful for use cases requiring both historical reprocessing and low-latency reads.
Kappa architecture simplifies Lambda by treating everything as a stream. Better operational simplicity; higher streaming infrastructure cost.
Data mesh distributes data ownership to domain teams, who publish data as products. Powerful at scale, but requires mature governance, platform engineering, and domain ownership culture to work.
Data fabric uses active metadata and AI-assisted integration to create a unified logical layer over distributed physical storage. Gartner positions it as complementary to—not a replacement for—mesh. The data mesh market reached $3.4B in 2025, projected at $14.7B by 2033 at 35.5% CAGR (HTF Market Insights).
Architecture pattern comparison
Which pattern fits your organization: a decision framework
Use these criteria as gates, not suggestions.
Start with a data warehouse if: your data is primarily structured, your team is SQL-first, you're below maturity Level 3, and your compliance requirements favor strong schema governance.
Move to a lakehouse if: you have diverse data types (structured + semi-structured + unstructured), you need cost-effective historical storage with analytical performance, and your team includes data engineers comfortable with Spark or similar processing frameworks.
Adopt Lambda or Kappa if: you have a real-time use case with sub-second latency requirements (fraud detection, dynamic pricing, live recommendations) and a dedicated platform engineering team.
Consider data mesh only if: you are at maturity Level 4 or above, your organization has 50+ data producers across distinct business domains, you have platform engineering capacity to build and maintain a data platform, and you have executive sponsorship for the cultural change ownership transfer requires.
Evaluate data fabric if: you have heterogeneous, distributed data estates that cannot be consolidated (common in post-merger enterprises or regulated industries with data residency requirements), and you want AI-assisted integration rather than manual pipeline engineering.
Data mesh and data fabric: honest limitations
Data mesh is frequently adopted for the wrong reasons. Organizations see Netflix and Uber case studies and assume the pattern is the cause of their success. It isn't. Netflix and Uber built domain-oriented ownership after years of platform investment, not as a way to bootstrap data capability.
Data fabric's promise of AI-automated integration is real but early-stage. The active metadata engines required to power it are maturing, and implementations without strong underlying metadata quality produce unreliable results.
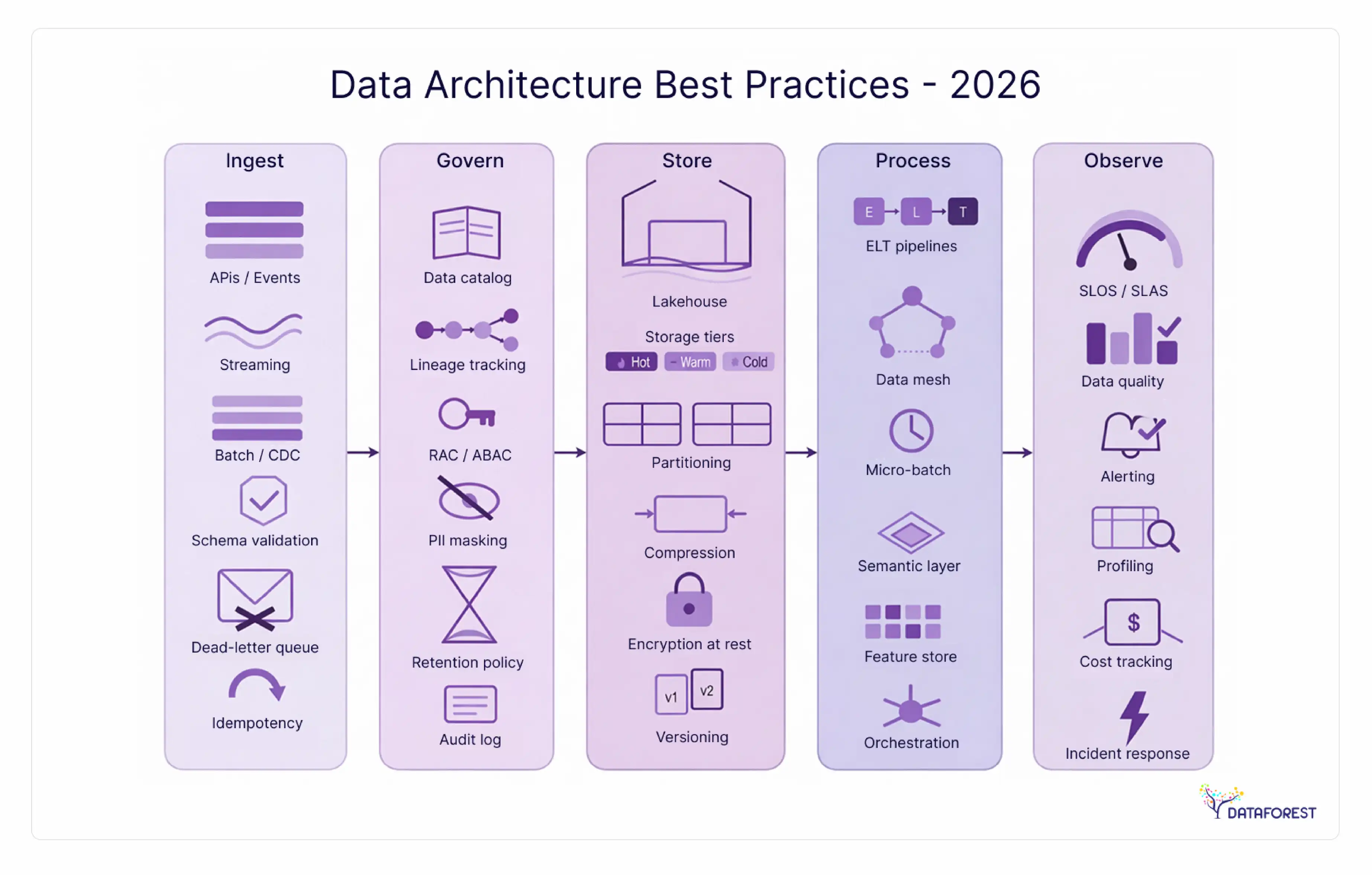
Data architecture design best practices
Design-phase decisions have long tails. A schema choice made in week one can require months of migration work two years later. These practices apply regardless of which pattern you select.
Domain-driven design and bounded contexts
Eric Evans' domain-driven design (DDD) concept of bounded contexts maps cleanly onto data architecture. Each business domain—orders, customers, products, fulfillment—should own its data contracts, schemas, and quality standards. This isn't just a data mesh concept. Even in a centralized warehouse, defining bounded contexts prevents schema conflicts and clarifies ownership when data quality issues surface.
In practice: before modeling any schema, map your business domains. Assign a domain data owner for each. Document which systems are authoritative sources for which entities. This single exercise eliminates the most common source of inter-team data conflicts.
Data governance—from policy to implementation
Governance is where architecture projects most consistently underdeliver. All three major patterns in this space present governance as a set of abstract principles—assign stewards, create policies, ensure compliance. None of them gives you a step-by-step setup sequence.
Here's a concrete governance implementation sequence:
- Define data domains (align with bounded contexts above)
- Assign domain owners (not just stewards—owners with accountability for quality SLAs)
- Create a policy catalog covering classification, access, retention, and quality thresholds
- Implement automated quality rules at ingestion (schema validation, null rate checks, referential integrity)
- Establish a governance council with a formal charter and recurring review cadence
- Define and measure compliance KPIs (data quality scores, SLA adherence, policy exception rates)
According to Precisely (2025), 64% of organizations cite data quality as their top data integrity challenge. Governance that stops at policy documents doesn't move that number.
Data contracts—from concept to specification
Data contracts are formal agreements between data producers and consumers that specify schema, quality guarantees, freshness SLAs, and access controls. They're the enforcement mechanism that makes governance real.
A basic YAML-based data contract defines: the dataset identifier, schema version, field-level definitions and types, quality rules (completeness thresholds, allowed value ranges), freshness SLA (maximum allowable staleness), and the owning team's contact and escalation path.
Contracts belong in version control. Schema changes require a pull request and review by downstream consumers. This single practice - treating data interfaces like code interfaces - eliminates the category of incidents caused by undocumented upstream changes.
Security and privacy by design—architecture-level controls
Security gets bolted on. That's the core problem. Encryption and access controls added after the architecture is established are harder to maintain, more likely to be misconfigured, and more likely to have gaps.
Security by design means mapping controls to architectural layers:
- Ingestion layer: Encrypt data in transit (TLS 1.3+), validate source authentication
- Storage layer: Encryption at rest, column-level encryption for PII in lakehouses, storage-level access policies
- Processing layer: Row-level security in transformation jobs, audit logging for all data access
- Access layer: Role-based access control (RBAC), attribute-based access control (ABAC) for fine-grained policies, zero-trust network policies for cross-domain data access
For GDPR compliance: data residency architecture is a first-class concern, not an afterthought. Where data physically resides must be documented in the architecture, not discovered during an audit.
For HIPAA: field-level de-identification and audit trails for PHI access must be built into the architecture, not layered on top of application logic.
For SOC 2: access control logs, change management records, and data classification documentation are all architectural artifacts.
Observability, monitoring, and data lineage
You cannot trust what you cannot observe. Data observability covers five dimensions: freshness (is the data current?), distribution (are values within expected ranges?), volume (are row counts as expected?), schema (have structure or types changed?), and lineage (where did this data come from, and what depends on it?).
Tools: OpenLineage provides an open standard for lineage metadata. OpenTelemetry handles pipeline performance telemetry. Jaeger supports distributed tracing across microservice data flows. Monte Carlo, Bigeye, and Soda focus specifically on data quality monitoring.
Column-level lineage is the highest-value investment here. When a dashboard shows wrong numbers, column-level lineage cuts root cause analysis from hours to minutes.

Data architecture anti-patterns—what breaks implementations
Here's what doesn't get said often enough: most data architecture failures aren't caused by choosing the wrong pattern. They're caused by predictable, repeatable mistakes that show up across organizations regardless of the technology stack. According to BCG, 65% of digital transformation projects fail. Technology rarely causes it.
The gap between investment and outcomes isn't technology. It's the approach. These eight anti-patterns are where the approach breaks down.
1. The premature mesh trap. A $200M B2B SaaS company—a composite scenario drawn from industry patterns—decided to adopt data mesh after reading about Shopify's implementation. They hired a data platform team, stood up a data portal, and assigned domain ownership to six business units. Eighteen months later: three domains had published one dataset each, four had published nothing, and the central platform team was overwhelmed supporting domain teams that lacked the engineering capacity to own their data. The root cause: they were at maturity Level 2, not Level 4. Mesh requires platform engineering maturity that most organizations underestimate.
Remediation: Run the maturity assessment above before selecting a pattern. Mesh requires Level 4 across governance and technology dimensions.
2. Governance as an afterthought. Architecture is designed, pipelines are built, and governance is planned "later." Later never comes until a compliance audit forces it, at which point retrofitting governance onto an established system costs 3–5x what it would have cost to build it in.
Remediation: Define data domains and assign owners in week one of any architecture project, before any technical design work begins.
3. The data lake swamp. Raw data lands in object storage with no schema enforcement, no documentation, no quality checks, and no retention policy. Within 18 months, no one knows what's there, no one trusts what's there, and the lake is effectively unusable.
Remediation: Implement a metadata catalog, schema enforcement at ingestion, and quality rules from day one. A lake without governance is a liability.
4. Ignoring the total cost of ownership. The cloud pricing calculator shows low per-GB storage costs. Nobody models the compute costs for scanning large tables, the data transfer fees for cross-region reads, the engineering hours for pipeline maintenance, or the cost of migrating when the chosen pattern stops serving the organization's needs.
Remediation: Build a TCO model before architecture selection. See the cost analysis section below.
5. Single-platform vendor lock-in. An all-in commitment to a single cloud provider's native data stack—Redshift + Glue + Athena, or Synapse + ADF + Fabric—can deliver efficiency initially and create serious constraints later. Cross-cloud data residency requirements, multi-cloud acquisition scenarios, and pricing negotiations all become harder.
Remediation: Prefer open formats (Apache Iceberg, Delta Lake, Parquet) at the storage layer. Open formats give you portability without sacrificing performance.
6. Replicating everything. Pipelines that copy data between systems "just in case" accumulate fast. Every copy is a governance problem, a cost problem, and a consistency problem. Organizations end up with five copies of customer data, each slightly different, each owned by a different team.
Remediation: Adopt a "data products first" design: define the authoritative source for each entity and build access patterns to the source, rather than creating derivative copies.
7. Treating the semantic layer as optional. Without a semantic layer—a consistent, governed definition of business metrics—different teams produce different numbers for the same question. "Monthly revenue" means different things to Finance, Sales, and Product. Executive dashboards contradict each other. Trust in data collapses.
Remediation: Define your semantic layer (tools: dbt metrics, Looker LookML, Cube.dev) as part of the architecture, not as a BI afterthought.
8. No architecture decision records (ADRs). Architecture decisions—why you chose lakehouse over warehouse, why you adopted Kafka over Kinesis, why you normalized or denormalized a particular schema—have context that evaporates when the people who made them leave. Six months later, teams undo decisions without understanding the constraints that produced them.
Remediation: Maintain an Architecture Decision Log (ADL). Each entry: decision made, options considered, rationale, consequences, and date. Keep it in version control.
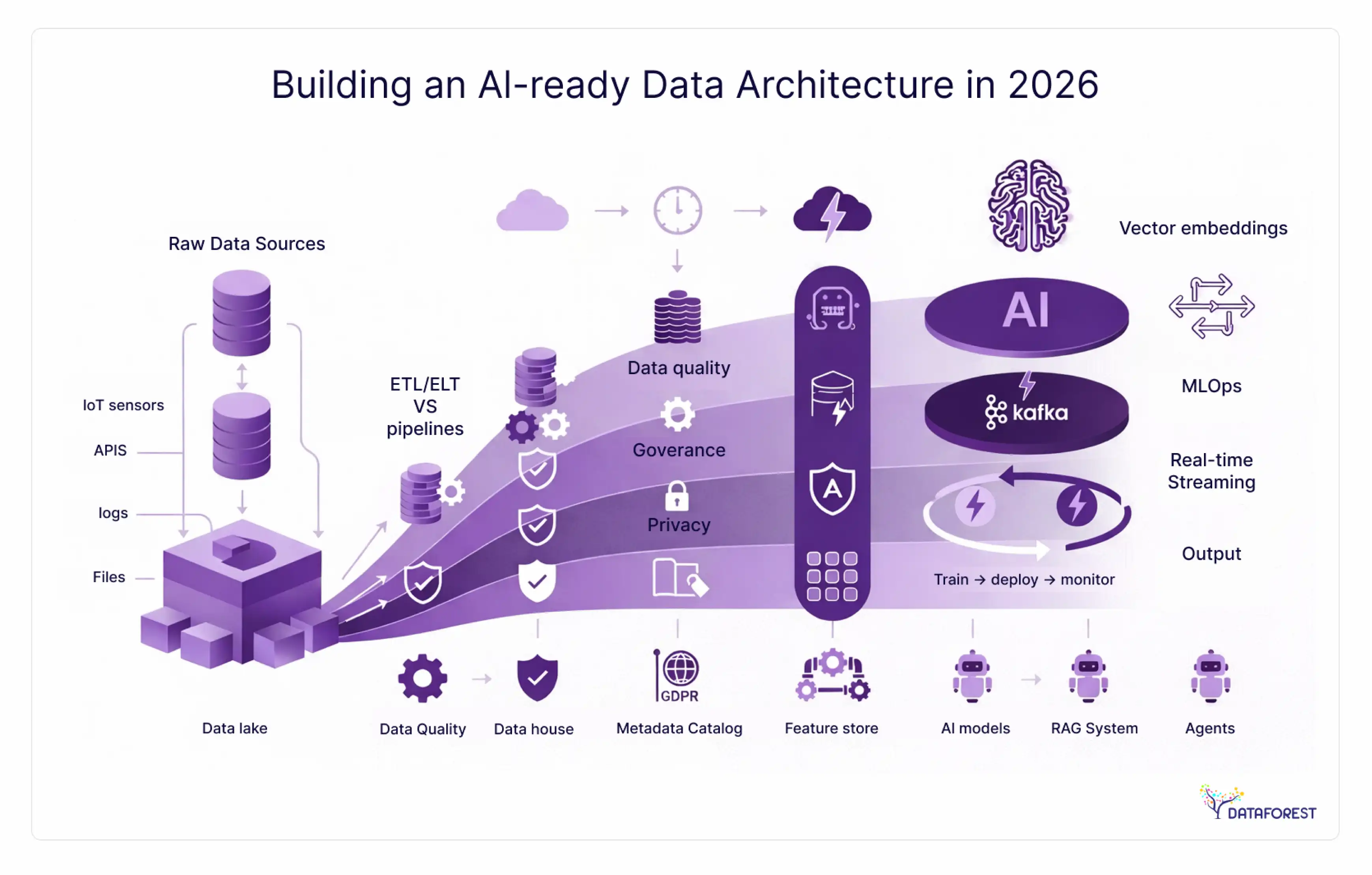
Building an AI-ready data architecture
AI capability is not something you add to a data architecture. It's something you either designed for or didn't. The architectural choices you make today directly determine whether your ML models train on good data, whether your RAG pipelines retrieve accurate context, and whether your feature engineering is reproducible.
Architecture choices that determine AI outcomes
Storage format matters. Columnar formats (Parquet, ORC) are efficient for feature extraction at scale. Apache Iceberg's time-travel capability enables reproducible training datasets—you can reconstruct the exact state of your data at any historical point, which is critical for model debugging and regulatory auditability.
Metadata richness determines discovery. ML engineers need to find datasets quickly. A catalog with column-level descriptions, lineage, quality scores, and sample statistics cuts feature store onboarding time significantly. Without it, feature engineering becomes a manual archaeology exercise.
Lineage enables debugging. When a model's performance degrades, the first question is usually "Did the data change?" Column-level lineage lets you answer that in minutes rather than days.
Freshness SLAs affect model quality. A fraud detection model trained on data with a 24-hour lag performs differently from one with a 5-minute lag. Freshness requirements should be documented in data contracts and monitored.
AI-ready architecture checklist
- Storage uses open columnar formats (Parquet, Iceberg, Delta Lake) with time-travel support
- All datasets have column-level descriptions in the metadata catalog
- Column-level lineage is tracked and queryable
- Freshness SLAs are defined and monitored for all datasets that feed ML pipelines
- The feature store is integrated, and features are versioned
- Embedding storage is defined (vector database or lakehouse with vector index support)
- RAG pipeline data sources have documented chunking, indexing, and retrieval strategies
- Training dataset snapshots are reproducible via time-travel or snapshot versioning
- Data quality scores are available as metadata (not just at ingestion—continuously monitored)
- Model serving data access patterns are documented and optimized for latency requirements
- PII and sensitive data are identified and masked or excluded from training pipelines by default
- Governance policy covers AI training data classification and consent tracking
Data architecture implementation roadmap—a 90-day phased approach
The most consistent predictor of architecture project success isn't the pattern selected—it's whether the implementation was phased. Big-bang migrations fail because they require everything to be right before anything works. Phased approaches deliver incremental value and allow course correction.
This roadmap is calibrated for mid-market organizations (100–500 employees). Enterprise organizations should extend each phase by 50–100%.
Phase 1: Assessment and governance foundations (weeks 1–4)
Goal: Understand your current state and establish the organizational foundations that architecture depends on.
- Complete the maturity assessment (score all five dimensions)
- Map data domains and identify authoritative sources for core business entities
- Assign domain owners for each data domain
- Document current pain points with specific, quantified impact (slow queries measured in seconds, duplicate records measured in count, data incidents measured in count/month)
- Select your target architecture pattern based on the decision framework above
- Define your data classification policy (public, internal, confidential, restricted)
- Establish a governance council with a meeting cadence
Deliverable: Architecture Assessment Report covering current state, target state, and gap analysis.
Phase 2: Architecture design and tool selection (weeks 5–8)
Goal: Design the target architecture in detail and select the tools that will build it.
- Produce a logical architecture diagram covering ingestion, storage, processing, access, and governance layers
- Define data contracts for the 5–10 most critical datasets
- Evaluate and select tools across all categories (see vendor evaluation section)
- Design the semantic layer for your 10–20 highest-value business metrics
- Define quality rules and SLAs for Tier 1 datasets
- Plan your migration sequence (prioritize highest-impact, lowest-risk workloads first)
Deliverable: Architecture Design Document and Tool Selection Matrix.
Phase 3: Build and migrate (weeks 9–12)
Goal: Implement the core infrastructure and migrate the first wave of workloads.
- Stand up ingestion infrastructure
- Implement a storage layer with the chosen format and partitioning strategy
- Migrate Tier 1 datasets (highest usage, best-understood schemas)
- Implement column-level lineage for migrated datasets
- Deploy quality monitoring for migrated datasets
- Run parallel validation: compare outputs from old and new systems for 2–4 weeks before cutover
Deliverable: Tier 1 workloads running on new architecture, validated against baseline.
Phase 4: Optimize and scale (ongoing, starting week 13)
Goal: Expand coverage, reduce costs, and improve performance continuously.
- Migrate Tier 2 and Tier 3 workloads on a rolling basis
- Implement cost monitoring and optimization (query caching, partition pruning, storage tiering)
- Expand governance coverage to all domains
- Begin AI-readiness improvements (feature store, embedding layer)
- Conduct quarterly architecture reviews
90-day implementation checklist
- Maturity assessment completed and scored
- Data domains mapped and owners assigned
- Current state pain points quantified
- Target architecture pattern selected using decision criteria
- The governance council was established with a charter
- Data classification policy defined
- Logical architecture diagram produced
- Data contracts defined for Tier 1 datasets
- Tool selection completed across all architectural layers
Semantic layer designed for core business metrics
- Migration sequence prioritized (Tier 1 → Tier 2 → Tier 3)
- Parallel validation plan documented before cutover
Cost analysis and TCO—what data architecture actually costs
No other area of data architecture receives less honest treatment than cost. Vendors show you the storage cost per TB. They don't show you the compute costs, the engineering hours, the migration costs, or the ongoing maintenance burden.
According to Gartner, poor data quality costs organizations $9.7–15M per year. According to Flexera (2024), approximately 27% of cloud spend is wasted. These aren't abstract numbers - they represent the cost of architectural decisions made without TCO analysis.
TCO comparison by architecture pattern
Hidden cost factors
Migration costs are consistently underestimated. A typical mid-market data warehouse migration to a lakehouse takes 6–12 months of engineering effort. At $150–200K fully-loaded cost per senior data engineer, a 3-person migration team represents $270–720K in labor before a single business user sees a benefit.
Technical debt from rushed implementations costs more than the original migration. Undocumented schemas, untested pipelines, and missing quality rules accumulate into maintenance burdens that consume 30–50% of engineering capacity on an ongoing basis.
Cloud waste is predictable. Queries scanning full tables instead of partitions, data retained longer than required, compute clusters running idle, and duplicate storage all add up. Model your query patterns before selecting a storage partitioning strategy.
The cost of inaction is real and measurable. If your organization loses $10M per year to poor data quality (Gartner's midpoint estimate) and an architecture modernization project costs $2–3M all-in, the ROI calculation is straightforward—provided the modernization is implemented correctly.
Team structure and roles for data architecture
Architecture decisions aren't made in a vacuum, and they don't implement themselves. The roles you have—and the reporting structure they sit within—directly affect which patterns are viable.
Role definitions
Data architect: Owns the logical and physical architecture design. Defines standards, reviews implementation against design, and maintains the Architecture Decision Log. Typically 1 per organization at mid-market; 1 per domain or platform area at enterprise.
Data engineer: Builds and maintains pipelines, implements storage schemas, and manages processing infrastructure. The primary builder of architecture.
Analytics engineer: Owns the transformation layer and semantic definitions. Works at the intersection of raw data and business metrics. Typically uses dbt or similar.
Data governance lead/data steward: Owns policy definition, quality monitoring, and compliance reporting. At smaller organizations, this role often overlaps with the analytics engineer or a senior data engineer.
Platform data engineer: At mesh-adopting organizations, builds and maintains the self-service data platform that domain teams use. Distinct from product data engineers who build domain pipelines.
ML engineer/data scientist: Consumes the data platform for model training and serving. Their requirements (freshness, reproducibility, feature discoverability) should inform architecture design decisions.
Team models by organization size
Startup / small (fewer than 50 employees): One data engineer who covers pipeline building, basic governance, and analytics. No dedicated architect. Adopt the simplest pattern that works—typically a managed warehouse. Focus on quality over sophistication.
Mid-market (50–500 employees): A data team of 3–6, with a senior data engineer or data architect as the technical lead, 1–2 data engineers, and an analytics engineer. A centralized data warehouse or lakehouse is appropriate. Avoid mesh until the team reaches 8+ people.
Enterprise (500+ employees): A platform data team of 8–15 plus distributed domain data engineers. A dedicated data architect or architecture function, a governance lead, and ML engineers. Mesh or fabric becomes viable at this scale if governance maturity is at Level 4.
Centralized vs. embedded data teams
Centralized data teams have high resource efficiency and consistent standards, but create bottlenecks and distance data work from the business domain context. Embedded teams (data engineers sitting within product or domain teams) produce faster delivery and stronger domain alignment, but risk inconsistent standards and duplicated effort.
The hybrid model—a small central platform team that owns standards, tooling, and governance, with domain data engineers embedded in business teams—outperforms either extreme at organizations above 200 employees.

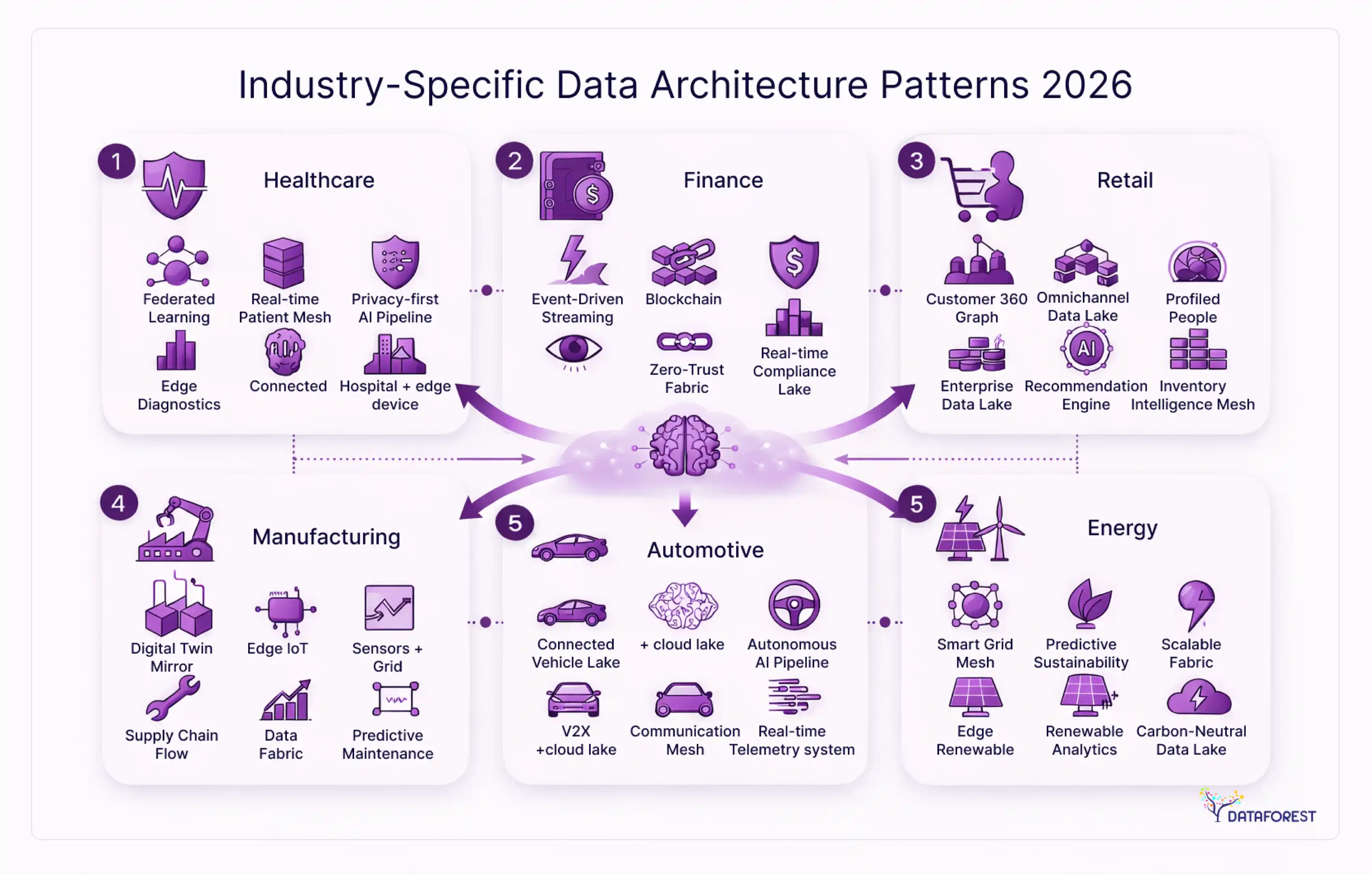
Industry-specific data architecture patterns
A healthcare system and a fintech startup have radically different data architecture requirements. Compliance obligations, data volumes, latency requirements, and organizational maturity vary enough across industries that a single recommended pattern doesn't hold.
Financial services
Requirements: Sub-second latency for fraud detection and risk scoring, strict data lineage for regulatory reporting (Basel III, DORA), data residency constraints, and high availability.
Recommended pattern: Lambda architecture for real-time risk and fraud use cases combined with a governed data lakehouse for historical analytics and regulatory reporting. Data contracts are mandatory—not optional—for any cross-system data sharing.
Key compliance considerations: GDPR, PCI DSS, SOX audit trail requirements. Column-level lineage for all financial transaction data. Immutable audit logs.
Healthcare
Requirements: HIPAA compliance for PHI, interoperability with HL7/FHIR standards, consent management, and strict access auditing.
Recommended pattern: Centralized lakehouse with column-level security and PHI masking. Data fabric is increasingly attractive here for integrating disparate EHR systems. Data mesh is generally inappropriate given the compliance complexity of distributed ownership.
Key compliance considerations: HIPAA requires field-level de-identification for secondary use, documented data access audit trails, and Business Associate Agreements for any third-party data processors.
E-commerce and retail
Requirements: Real-time inventory sync, personalization at scale, supply chain visibility, seasonal volume spikes.
Recommended pattern: Lakehouse with streaming ingestion (Kafka + Flink) for real-time inventory and recommendation signals, batch processing for historical analysis. CDC streaming from operational databases is common for inventory and order state management.
Key compliance considerations: PCI DSS for payment data. GDPR/CCPA for customer behavior data. Data retention policies for purchase history.
SaaS
Requirements: Multi-tenant data isolation, product analytics at scale, feature adoption tracking, and customer health scoring for CS teams.
Recommended pattern: Lakehouse with strong tenant isolation at the storage layer. dbt or equivalent for the semantic layer. Feature flags and A/B test metadata are tracked as first-class data.
Key considerations: Tenant data isolation is an architectural requirement—not an access control problem. Schema design must account for multi-tenancy from the start.
Manufacturing
Requirements: Sensor and IoT data at high volume and velocity, predictive maintenance, supply chain integration, OT/IT convergence.
Recommended pattern: Streaming architecture (Kappa or Lambda) for real-time sensor data, lakehouse for historical analysis, and ML training data. Edge processing is often required before data reaches the central platform. Time-series databases (InfluxDB, TimescaleDB) for sensor telemetry.
Key considerations: OT network security is a separate domain from IT data architecture. Data from industrial control systems requires careful isolation before integration with enterprise data platforms.
Vendor and tool selection—an evaluation framework
Tools are means, not ends. The right evaluation sequence is: define your requirements, then select tools that meet them—not the reverse. The most common evaluation mistake is starting with a vendor shortlist rather than a requirements document.
Tool category map
Evaluation scorecard criteria
Rate each candidate tool across these dimensions:
- Functional fit—Does it solve your specific requirements? (Not the vendor's demo requirements.)
- Operational complexity—What does it cost to run and maintain? Does your team have the skills?
- Total cost—Licensing, compute, egress fees, support costs, and migration costs if you later change.
- Vendor lock-in risk—Does it use open formats and standards? Can you migrate off it?
- Ecosystem integration—Does it integrate with your existing stack without custom connectors?
- Scalability path—Will it handle 10x your current volume without architectural changes?
- Support and community—For open source: Is the project actively maintained? For commercials: what's the support for SLA?
Open-source vs. managed: the honest tradeoff
Open-source tools give you lower licensing costs, full portability, and access to community innovation. They require engineering capacity to deploy, maintain, upgrade, and troubleshoot. For a team of 2–3 data engineers already stretched thin, "free" software can be the most expensive choice when you account for operational labor.
Managed tools shift operational burden to the vendor at a higher direct cost. This tradeoff makes sense when engineering capacity is the binding constraint. It makes less sense when your scale requires custom optimization that managed tools can't provide.
Migration and modernization—from legacy to modern architecture
The majority of organizations implementing modern data architecture aren't starting from scratch. According to the research data underlying this guide, over 78% of enterprises manage data across 10 or more heterogeneous platforms. They're migrating from something. The migration itself is often where projects fail.
Modernization decision tree
Before selecting a migration pattern, answer these questions:
- What is the business priority? Cost reduction → prioritize storage optimization. Speed to insight → prioritize query performance. AI capability → prioritize metadata richness and freshness. Compliance → prioritize lineage and access controls.
- What is your current state's biggest liability? Maintenance cost → re-architect. Performance → re-platform. Vendor lock-in → re-platform with open formats. Governance → can be addressed without infrastructure migration.
- What is your team's capacity for disruption? High → re-architect on a compressed timeline. Medium → phased re-platform. Low → lift-and-shift first, modernize later.
Migration patterns
Lift-and-shift moves existing workloads to new infrastructure without redesigning them. Lowest risk, fastest timeline, but preserves existing technical debt. Appropriate as a first step when the primary goal is cost reduction or vendor migration.
Re-platform migrates workloads to a new infrastructure pattern while preserving business logic. Moderate risk. Appropriate when you need performance improvements or want to adopt open formats without a full redesign.
Re-architect redesigns workloads from the ground up for the target pattern. Highest risk, longest timeline, highest potential upside. Appropriate when the existing architecture fundamentally can't serve the organization's requirements.
Phased migration execution
Regardless of which migration pattern you select, sequence your workloads:
- Tier 1: High business value, well-understood schemas, active ownership. Migrate first. These workloads generate confidence and early wins.
- Tier 2: High business value, complex schemas, or limited documentation. Migrate second, after Tier 1 validates your migration approach.
- Tier 3: Low usage, legacy, or uncertain business value. Evaluate whether to migrate or retire.
Run parallel validation for at least two weeks before cutting over any Tier 1 workload. Compare output row counts, aggregate values, and key metric calculations between old and new systems. Only cut over when validation passes consistently.
Conclusion
Your Data Architecture Needs a Foundation, Not a Hype Cycle
The organizations that build effective data architectures share a pattern: they assess their current state honestly, they choose patterns based on their constraints rather than industry trends, they implement governance before infrastructure, and they phase their execution to deliver incremental value rather than betting everything on a big-bang migration.
The gap between investment and outcomes isn't technology. Organizations investing in data capabilities at a 98.8% rate, with only 37.8% achieving data-driven outcomes, aren't failing because they chose the wrong tool. They're failing because they skipped the foundations—maturity assessment, domain ownership, governance, and honest cost modeling—in favor of jumping to the pattern selection conversation.
Start with the maturity assessment in this guide. Score your organization across governance, technology, people, and processes. Let that score determine your starting point, not the architecture pattern you find most conceptually appealing.
If you're planning an architecture initiative, combining the Architecture Decision Log template and 90-day implementation checklist from this guide with expert modern data architecture services can dramatically reduce implementation risk and help your team move from fragmented systems to a scalable, governance-ready foundation faster.
References
- BCG. Flipping the Odds of Digital Transformation Success. Boston Consulting Group, 2020. (850+ company analysis; 35% success rate cited.)
- NewVantage Partners. Data and AI Leadership Executive Survey. NewVantage Partners, 2023. (37.8% data-driven organizations; 98.8% investment rate.)
- Gartner. How to Stop the 5 Most Costly Forms of Bad Data. Gartner Research. (Poor data quality costs $9.7–15M per organization per year.)
- Flexera. 2024 State of the Cloud Report. Flexera, 2024
- Precisely. 2025 Data Integrity Trends and Insights Report. Precisely, 2025. (64% cite data quality as the top data integrity challenge.)
- MuleSoft. 2025 Connectivity Benchmark Report. Salesforce MuleSoft, 2025. (Organizations average 897 applications; 29% integration rate.)
- HTF Market Insights. Data Mesh Market Size and Forecast. HTF Market Intelligence, 2025. (Data mesh market $3.4B in 2025, projected $14.7B by 2033.)
- Statista / IDC. Global Data Volume 2018–2025. As cited in MarketsandMarkets and Alation research, 2025. (181 ZB by 2025.)
- DataVersity / MarketResearch. Data Lakehouse Market Forecast. Cited via Dataversity, 2024. (22.9% CAGR; $66B+ by 2033.)
- Business Research Insights. Data Architecture Modernization Market Report. Business Research Insights, 2024. (~$8.8B market, ~12% CAGR.)


.webp)







