

The global enterprise data management market surpassed $111 billion in 2025—yet fewer than 25% of organizations have a documented enterprise data architecture to govern how all that investment actually flows. Billions are spent on data tools, platforms, and engineers. Then the data still can't talk to itself.
That's the core problem enterprise data architecture (EDA) is designed to solve. It's the structural blueprint that determines how data moves, gets stored, gets governed, and ultimately gets used to make decisions. But here's what most guides won't tell you: enterprise data architecture is a business strategy decision, not a technology project—and organizations with a clearly defined enterprise data strategy consistently outperform those that treat architecture as a purely technical initiative.
This guide gives you the complete picture. You'll learn how to evaluate the three dominant architecture frameworks and choose the right one for your organization, how to select the architecture pattern that fits your data volume, team size, and regulatory environment, and how to build a phased 18-month implementation roadmap with real resource requirements and decision gates. You'll also find the maturity model, the anti-patterns, and the industry-specific guidance that most articles skip entirely.
Key takeaways
- Organizations with mature data architecture practices achieve 42% higher digital transformation success rates and 35% lower data management costs than those without, according to IRJMETS research (2025).
- Treat enterprise data architecture as a technology project, and you'll probably fail—the defining factor in successful implementations is executive sponsorship and organizational change management, not tool selection.
- TOGAF, DAMA-DMBOK, and Zachman serve fundamentally different purposes; using the wrong framework for your organization type is one of the most common and least-discussed failure modes.
- The data mesh pattern is genuinely powerful for large, domain-rich organizations, but it requires significant organizational maturity—most companies that attempt it prematurely create decentralized chaos instead of distributed ownership.
- According to Mordor Intelligence (2025), 93% of enterprise data remains unstructured, which means your architecture has to account for far more than the data warehouse you can see.
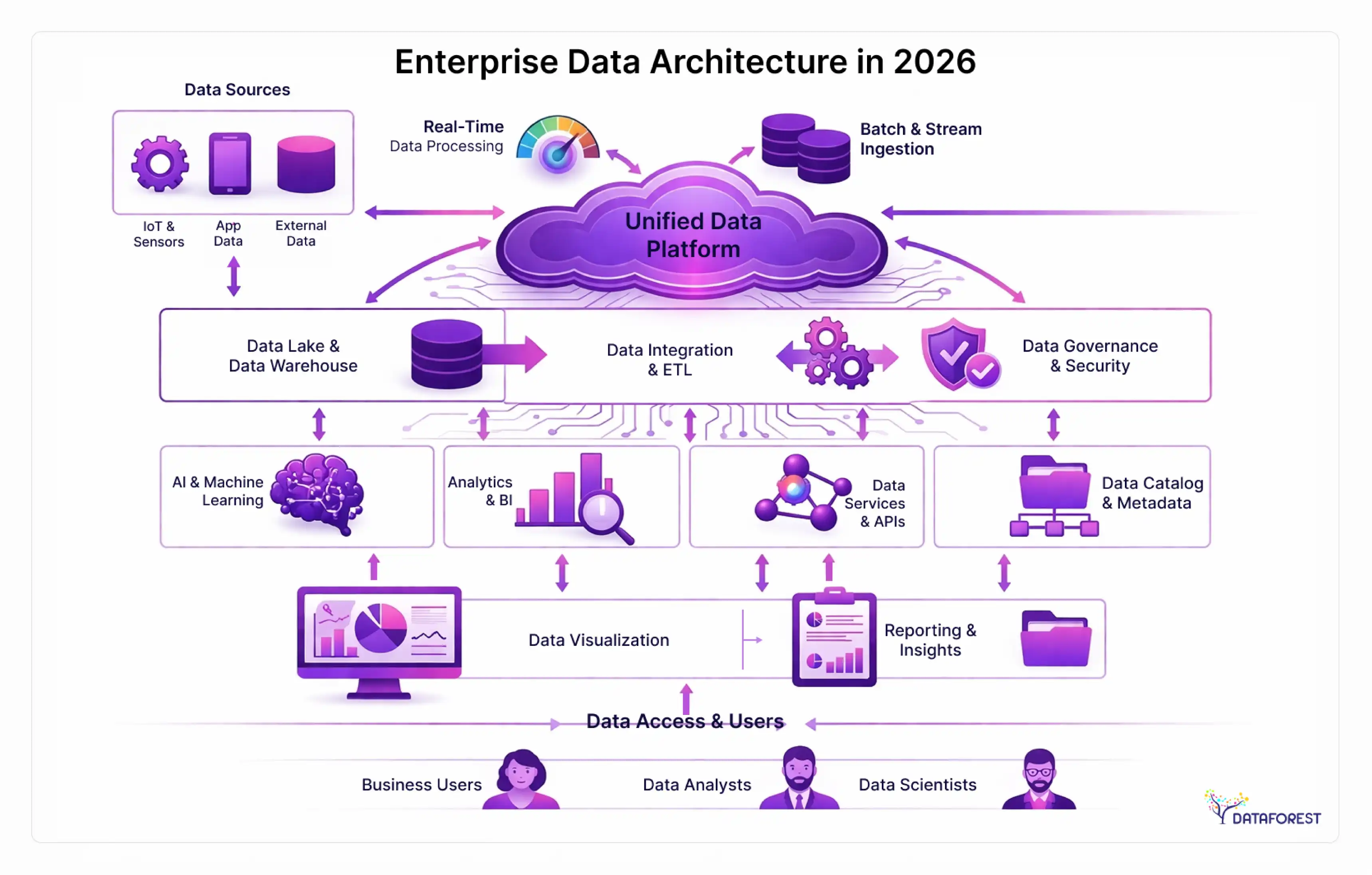
What enterprise data architecture actually is (and what it isn't)
Enterprise data architecture is the set of rules, models, policies, and standards that govern how data is collected, stored, integrated, and used across an entire organization. It's not a single system or platform—it's the blueprint that all systems must conform to.
The distinction matters. Many organizations have data architectures for specific domains: a warehouse for finance, a lake for marketing, a streaming pipeline for operations. What they lack is an enterprise data architecture that connects those domains under shared governance, common data definitions, and consistent quality standards. The result is what data practitioners call a "silo sprawl"—isolated data assets that technically exist but can't be combined to answer cross-functional questions.Specialized data architecture services help organizations bridge these gaps by designing the shared governance and common data definitions required to unify disparate systems into a single, functional blueprint.
EDA vs. general data architecture: the organizational scope difference
General data architecture describes how a specific system or application manages its data. Enterprise data architecture operates at the organizational level—it defines standards and structures that apply across every system, every department, and every data consumer in the business.
The practical difference shows up when someone asks: "What's our total customer acquisition cost, broken down by channel and product line, for Q3?" General data architecture can answer that within a single system. Enterprise data architecture is what makes it answerable when the revenue data lives in Salesforce, the marketing spend in a separate analytics platform, and the product attribution in an internal data warehouse.
The 5 components every enterprise data architecture must address
A functional enterprise data architecture requires five interlocking layers working together:
Data ingestion and integration. How data enters your ecosystem—batch ETL, real-time streaming, API calls, event-driven pipelines. This layer includes the connectors, transformation logic, and latency requirements for each data source.
Storage architecture. Where data lives: data warehouses for structured analytics, data lakes for raw/unstructured storage, lakehouses that combine both, or specialized stores (vector databases, time-series databases) for specific workloads. According to Mordor Intelligence (2025), 93% of enterprise data is unstructured—storage decisions have to account for that reality.
Data transformation and processing. The logic layer: how raw data becomes analysis-ready. This includes ELT/ETL pipelines, business rule engines, and semantic layers that translate technical data models into business-friendly concepts.
Governance and catalog layer. Metadata management, data lineage, access control, data quality rules, and the policies that determine who can see what. This layer is where most implementations are weakest.
Consumption and delivery. How data reaches its consumers—dashboards, APIs, embedded analytics, ML model training pipelines, and self-service query tools.
The business case—ROI benchmarks and market context
Enterprise data architecture is one of the few technology investments where the financial case is genuinely strong. The challenge is that most organizations struggle to build it because the numbers live in research reports rather than in internal financial models.
According to Fortune Business Insights and Grand View Research, the enterprise data management market is growing at 11–14% CAGR and is projected to reach $222–295 billion by 2030–2034. North America holds approximately 30–34% of that market. Large enterprises currently account for roughly 61% of total spending (Fortune Business Insights, 2026 projection). The investment is already happening. The question is whether it's organized.
What mature EDA practices deliver: the 42% and 35% benchmarks
Research published in IRJMETS (2025) found that organizations with mature data architecture practices achieve 42% higher digital transformation success rates and 35% lower data management costs compared to those operating without a documented architecture. A separate ResearchGate study found that mature enterprise architecture organizations implement digital initiatives 43% faster than their less-mature counterparts.
These aren't soft benefits. A 35% reduction in data management costs at a mid-size enterprise spending $10 million annually on data infrastructure represents $3.5 million per year in recoverable costs. That figure alone typically justifies an architecture program.
The cost of inaction: what a "data swamp" really costs
Here's a scenario that plays out more often than most organizations admit. A large financial services firm approved a $2.3 million data lake implementation to modernize analytics across four business units. Eighteen months in, the lake had become what engineers call a "data swamp"—terabytes of ingested data with no documented lineage, no quality standards, no access governance, and no consistent naming conventions. Analysts couldn't determine which datasets were authoritative. Compliance couldn't produce audit trails. The remediation effort took another 18 months and cost $1.8 million.
The root cause was never the technology. It was the absence of architecture governance before the first byte was ingested.
Enterprise data architecture is a business strategy decision, not a technology project—and the organizations that treat it as the former consistently outperform those that treat it as the latter. That's not an abstract principle. It's the $1.8 million lesson from the case above.

Data architecture frameworks compared—TOGAF, DAMA-DMBOK, and Zachman
Three frameworks dominate the enterprise data architecture conversation: TOGAF's ADM, DAMA-DMBOK, and the Zachman Framework. The problem is that most guides describe them in isolation without helping you choose. They're not interchangeable—they address different problems, suit different organization types, and require different levels of commitment.
Framework comparison matrix
Which framework fits your organization?
Your selection should depend on three factors: your organization's primary goal, your existing maturity, and your available capacity for framework adoption.
If your goal is comprehensive enterprise architecture governance across all domains (business, data, application, technology), start with TOGAF. It's the most widely adopted EA framework globally and provides a structured methodology from current-state assessment through target-state design. It's most effective when sponsored at the CIO or CTO level.
If your goal is data management excellence—improving data quality, establishing governance disciplines, managing master data—DAMA-DMBOK is the right choice. It organizes data management into 11 disciplines (including data governance, data architecture, data quality, metadata management, and data security) and lets you start with the disciplines most urgent to your business.
If your goal is documenting and communicating your existing architecture to diverse stakeholders, the Zachman Framework's 6×6 matrix (What, How, Where, Who, When, Why × Contextual, Conceptual, Logical, Physical, Detailed, Functional) is a useful classification tool. Be clear on what it is: a taxonomy, not a process.
Most mature organizations use a hybrid: TOGAF as the governing methodology, DAMA-DMBOK for data-specific disciplines, and Zachman as a communication and documentation framework.
Case study—pharmaceutical, large enterprise: Gilead Sciences adopted a data mesh approach supported by Informatica's data governance platform, treating clinical, commercial, and operational data as domain-specific products with clear ownership. The initiative began with DAMA-DMBOK's data governance discipline, establishing data stewardship roles and quality standards before introducing the mesh architecture pattern. This sequencing—governance framework first, architecture pattern second—is the approach that most failed mesh implementations skip.
Architecture patterns: selecting the right model for your context
Architecture patterns are the structural blueprints for how data is organized and accessed across the enterprise. The right pattern depends on your data volume, team structure, regulatory complexity, and analytical workloads. Choosing wrong doesn't just slow you down—it creates technical debt that compounds over the years.
Architecture pattern selection matrix
Decision criteria for pattern selection
Choose Data Mesh if you have 5 or more identifiable business domains with dedicated data teams, strong organizational maturity, and a federated operating model. Avoid it if your organization doesn't have domain teams ready to own their data products—you'll get decentralization without accountability.
Choose Data Fabric if your data is distributed across multiple cloud environments, on-premises systems, and legacy platforms, and your team lacks the capacity to manually orchestrate connections between them. Data Fabric uses active metadata and AI-driven automation to create a virtual data integration layer. It's infrastructure-intensive to set up but operational cost-efficient once running.
Choose Lakehouse if your primary workloads are analytics and machine learning, you want to eliminate the cost and complexity of maintaining separate data lake and data warehouse systems, and your data mix includes both structured and unstructured sources. It's the most common choice for organizations building an AI-ready data infrastructure and prioritizing AI readiness in 2025–2026.
Choose Lambda or Kappa based on your streaming requirements. Lambda is appropriate when you need both historical batch analytics and real-time operational data, and can manage dual processing paths. Kappa is simpler—treat everything as a stream—but only practical when your historical reprocessing requirements can be served by replaying the event log.
Case study—consumer electronics, large enterprise: ASUS consolidated marketing and operational data across 12 regional markets using Improvado as the data integration layer over a centralized lakehouse architecture. The migration from siloed regional reporting systems reduced time-to-insight for global campaign performance from 72 hours to under 4 hours, with a 40% reduction in manual data preparation work across regional analytics teams.
Enterprise data governance and security architecture
Governance is mentioned in almost every data architecture discussion and implemented deeply in almost none. That gap is where most architecture investments quietly fail. You can build the most sophisticated lakehouse in your industry, but if no one owns the data quality rules, the trust erodes within six months.
Governance operating model and RACI framework
A functioning data governance operating model requires four roles working across two levels: strategic and operational.
Data Governance Council (strategic level): Executive sponsors—typically CDO, CIO, and business unit heads—who set policy, resolve cross-domain conflicts, and own the business case for data quality.
Data Architecture Function (operational level): The team that translates governance policy into technical standards, manages the enterprise data catalog, and owns the data architecture blueprint.
The RACI for day-to-day governance decisions maps as follows:
Security controls mapped to compliance requirements
Security architecture in modern enterprise data environments isn't a single layer—it's a set of controls that must map explicitly to your regulatory obligations. The following table maps the primary compliance frameworks to the security controls they require:
Zero-trust architecture is the recommended security model for enterprise data environments in 2026. The core principle: no user, system, or service is trusted by default, regardless of whether they are inside or outside the network perimeter. For data architecture specifically, this means per-query access validation, attribute-based access control rather than role-based-only, and continuous data access monitoring with anomaly detection.
Industry-specific architecture considerations
Enterprise data architecture looks different depending on your industry—not because the fundamental principles change, but because the regulatory environment, data volumes, latency requirements, and organizational structures vary enough to make generic advice genuinely unhelpful. The table below maps the most common architecture decisions to the constraints of four major verticals.
Case study—healthcare system, large enterprise: A regional health system with 14 hospitals and 8,000 clinical staff implemented a lakehouse architecture to consolidate EHR data, imaging metadata, and population health analytics under a single governance model. The primary driver was HIPAA compliance—the prior architecture had six separate data environments with inconsistent access logging. Post-implementation, the system reduced audit preparation time by 65% and enabled an AI-assisted readmission prediction model that reduced 30-day readmissions by 11% in the first year. The governance-first approach—establishing RACI, data quality standards, and access policies before migrating data—was cited as the single most important success factor.
Enterprise data architecture maturity model: score your current state
Before you can plan a data architecture program, you need an honest assessment of where you actually are. The 5-level EDA Maturity Model below gives you observable criteria at each stage—not vague descriptors, but specific signs you can check against your current environment.
The 5-level EDA maturity model
What each level looks like in practice
Most mid-size enterprises reading this are at Level 2 or Level 3. Level 2 is where you know the problems exist, but fix them reactively. Level 3 is where you've built the governance infrastructure but haven't operationalized it consistently. The jump from Level 3 to Level 4 is where the ROI benchmarks in the business case section start materializing—the 35% cost reduction and 42% transformation success improvement are predominantly Level 4 outcomes.
Level 5 is genuinely rare. If your organization has self-healing data pipelines, AI-assisted metadata curation, and real-time architecture adaptation, you're in rarefied company. Most organizations should be targeting Level 4 as the 3–5 year ambition, not Level 5.
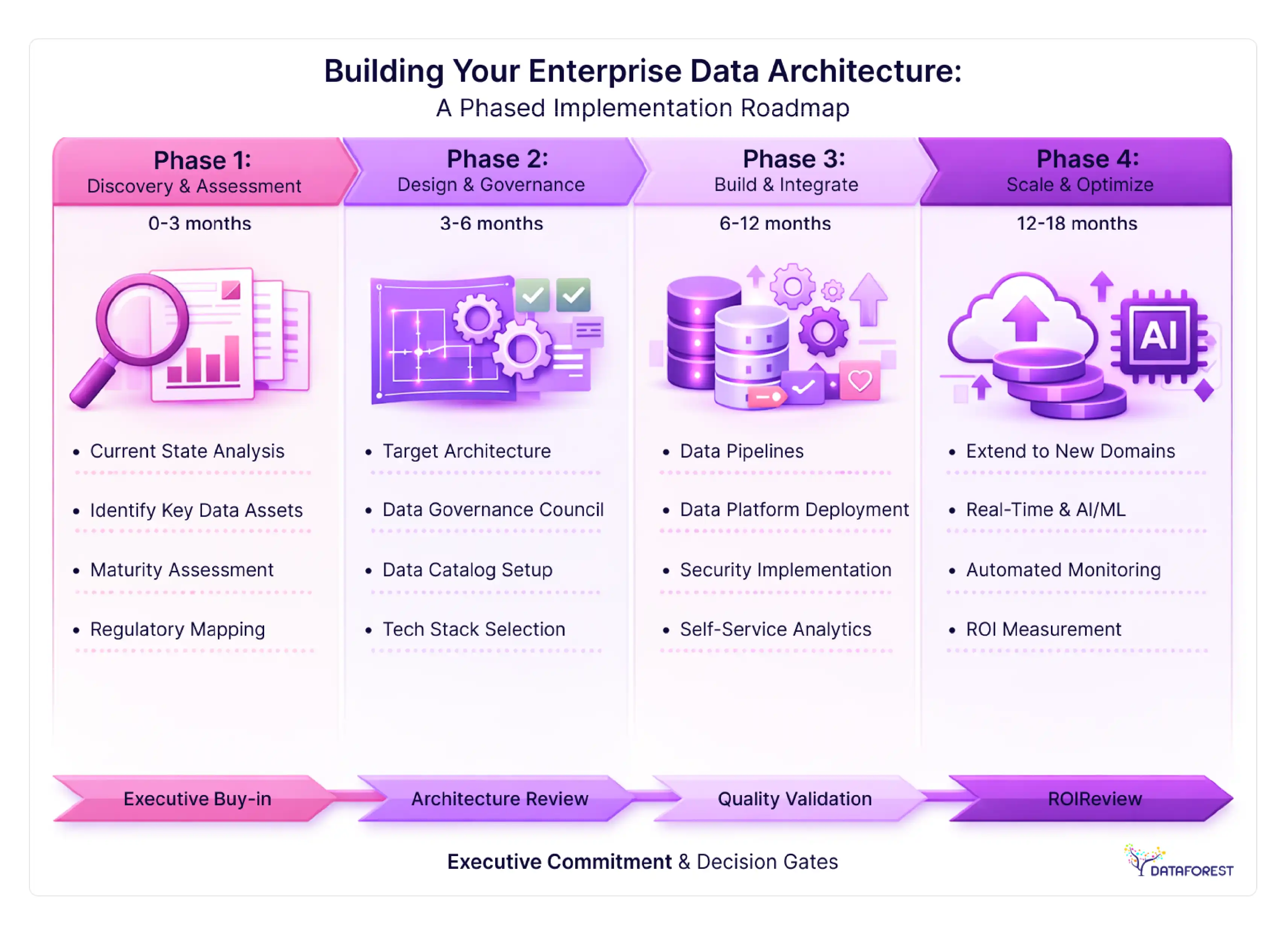
Building your enterprise data architecture: a phased implementation roadmap
The most common implementation mistake is starting with tool selection. The second most common is attempting too much at once. The following roadmap is deliberately sequenced to build organizational capability before scaling technical complexity.
Phase 1: discovery and assessment (months 0–3)
Goal: Establish the current-state baseline and build the business case.
Activities:
- Inventory all existing data systems, owners, and consumers (aim for 80% coverage, not perfection)
- Document current data flows and identify the 10 most critical data assets by business impact
- Assess your organization against the 5-level maturity model above
- Identify your primary regulatory obligations and map them to data assets
- Draft architecture principles document (6–10 guiding principles, not a full design)
- Present current-state findings and investment case to executive sponsors
Resources required: 1 Enterprise/Data Architect (lead), 1 Data Governance Analyst, 4–6 business stakeholder interviews, existing tooling only.
Decision gate: Executive commitment to governance model and budget before Phase 2.
Risk: Scope creeps into solution design during discovery. Contain it.
Phase 2: design and governance foundation (months 3–6)
Goal: Establish the governance model and target architecture design before building anything.
Activities:
- Select and adopt your primary framework (TOGAF, DAMA-DMBOK, or hybrid)
- Design target-state architecture pattern based on the selection matrix
- Establish the Data Governance Council and assign data stewards to priority domains
- Build an enterprise data catalog for priority data assets (not the entire estate)
- Define data quality rules and ownership RACI for the top 10 critical data assets
- Design security architecture and map controls to compliance requirements
- Select core technology stack components (storage, integration, orchestration)
Resources required: 1–2 Data Architects, 1 Governance Lead, business domain representatives, and a technology vendor evaluation.
Decision gate: Architecture design review with stakeholders before any production builds.
Risk: Governance theater—governance structures exist on paper but have no enforcement mechanism. Build automated data quality monitoring into Phase 3 from day one.
Phase 3: build and integrate (months 6–12)
Goal: Implement core architecture components for priority data domains.
Activities:
- Build data ingestion pipelines for priority data sources
- Implement target storage architecture (warehouse, lake, or lakehouse based on Phase 2 design)
- Deploy an enterprise data catalog with automated lineage tracking
- Implement security controls and access management
- Migrate priority data assets with validated quality rules
- Launch self-service analytics for the first business domain
- Measure Phase 1 KPIs (data quality score, time-to-insight, pipeline reliability)
Resources required: 2–3 Data Engineers, 1 Data Architect, 1 Data Steward per priority domain, security/compliance review.
Decision gate: Quality and reliability thresholds met before expanding to additional domains.
Risk: "Big bang" migration. If you can't get one domain right in Phase 3, you won't get five right in Phase 4.
Phase 4: scale and optimize (months 12–18)
Goal: Extend architecture to remaining domains and begin optimization.
Activities:
- Expand architecture to secondary data domains using Phase 3 patterns
- Implement real-time streaming for time-sensitive workloads
- Build ML feature store and AI/ML serving infrastructure (if required)
- Automate data quality monitoring and alerting across all domains
- Establish ongoing architecture review cadence (quarterly)
- Measure ROI: time-to-insight, data quality %, infrastructure cost per terabyte, analyst productivity
Resources required: Full data architecture team, domain data stewards, ML engineering (if applicable).
Decision gate: Phase 4 ROI review determines whether to scale further or consolidate.
Implementation readiness checklist
Before beginning Phase 1, verify you can check each of the following:
- Executive sponsor identified at the CDO or CIO level with budget authority
- Current data system inventory exists (even if incomplete)
- The primary business use case for architecture investment is documented
- Regulatory obligations are mapped to data asset categories
- At least one data governance lead role is assigned or budgeted
- Architecture principles are drafted, or existing documentation is reviewed
- Technology stack evaluation criteria are defined before vendor conversations
- Data quality baseline metrics are established for priority data assets
- Change management plan addresses impacted business stakeholders
- Success metrics and measurement timeline are agreed upon with executive sponsors
- Migration approach determined: incremental domain-by-domain vs. parallel build
- Skills gap assessment completed for current team vs. target architecture requirements

Team structure, roles, and organizational readiness
Architecture is where technology and people intersect. The technical blueprint matters, but the organizational structure that implements and sustains it matters more. Enterprise data architecture initiatives that fail almost always cite people and process failures, not technology failures.
The 4 roles your data architecture function needs
Enterprise/Data Architect (1–2 FTEs at initial scale). Owns the architecture blueprint, selects and enforces standards, evaluates new patterns and technologies, and interfaces with EA and technology leadership. This role requires deep technical knowledge of architecture patterns and frameworks, combined with the business acumen to translate architectural decisions into business outcomes. According to the research file, demand for data architects has grown 28%+ annually - sourcing this role is consistently the longest hiring timeline in data programs.
Data Engineer (2–4 FTEs at initial scale). Builds and maintains the data pipelines, storage infrastructure, and transformation logic that the architecture design specifies. The ratio of engineers to architects should be at least 2:1; architecture without engineering capacity to execute it is a document, not a program.
Data Steward (1 per priority business domain). The bridge between technical architecture and business data ownership. Stewards own the data quality rules for their domain, resolve definition conflicts, and enforce governance policies in practice. This role is often distributed—a finance analyst who becomes the Finance Data Steward—rather than a dedicated hire.
Data Governance Lead (1 FTE). Operates the governance framework: manages the data catalog, tracks quality metrics, coordinates the governance council, maintains the RACI, and runs the data quality remediation backlog. This role is frequently underinvested and is frequently the reason governance frameworks fail.
Centralized vs. federated: choosing your operating model
The honest answer for most organizations: start centralized, move toward a hybrid CoE model as domain teams develop capability, and only consider full data mesh if you've reached Level 4 maturity with genuine domain team readiness.
Anti-patterns and failure modes that derail EDA initiatives
Every guide in this space tells you what to do. Here's what most of them skip: the specific, observable ways that well-funded enterprise data architecture programs fall apart. These aren't edge cases. They're the norm.
8 EDA anti-patterns to watch for
Tool-first thinking. Selecting the data platform before defining the architecture requirements. The sequence should always be: principles → patterns → governance model → technology selection. Organizations that reverse this sequence end up with expensive tools shaped to the wrong problems.
Governance theater. Creating a Data Governance Council, RACI matrix, and data steward roles—then never actually using them to make binding decisions or enforce standards. Governance theater is identifiable by one symptom: nobody has ever said "no" to a data initiative on governance grounds.
Premature centralization. Attempting to centralize all data under a single governance model before the organization has the maturity to support it. This kills domain team morale and creates bottlenecks that cause business units to build shadow IT data environments.
Boiling-the-ocean syndrome. Scoping Phase 1 to include all data sources, all business domains, and all use cases simultaneously. Architecture programs that try to do everything first typically deliver nothing in the first 12 months and lose executive support.
Data catalog as a destination. Investing heavily in a data catalog tool and treating its population as the goal of the governance program. A data catalog is a means to data discoverability and trust - it's worth nothing if the data inside it isn't governed.
Architecture without ownership. Publishing an architecture blueprint without assigning named accountable owners for each architecture component. Architectural standards that aren't owned are unenforced standards.
Ignoring organizational readiness. Treating data architecture as a technical program managed exclusively by the technology organization. The business stakeholders who will actually use the resulting data products need to be engaged, trained, and incentivized to participate—particularly the data stewards who own domain-level quality.
Treating migration as a single event. Planning a full legacy-to-modern migration in a single "big bang" cutover rather than an incremental, domain-by-domain transition. Big-bang migrations have a disproportionate failure rate; the risk accumulates with every system added to the migration scope.
Conclusion
Build the Rules Before the Pipes
Enterprise data architecture is a business strategy decision, not a technology project. That's not a tagline—it's the organizing principle that separates programs that deliver measurable ROI from those that become cautionary tales.
The market is large and growing fast: $111 billion in 2025, projected to reach more than $220 billion within a decade. The organizations capturing that value aren't necessarily the ones with the most sophisticated technology stacks. They're the ones that established governance before they built pipelines, assigned ownership before they ingested data, and matched their architecture pattern to their organizational maturity rather than to the latest industry trend.
Score yourself against the 5-level maturity model in this guide. If you're at Level 1 or 2, the immediate priority is governance foundation, not pattern selection. If you're at Level 3, the phased roadmap gives you the sequencing to reach Level 4. If you're already at Level 4, the anti-patterns section is probably more relevant to you than the framework comparison.
References
- Fortune Business Insights. Enterprise Data Management Market Size, Share & Industry Analysis. 2025–2026 projection. [fortune businessinsights.com]
- Grand View Research. Enterprise Data Management Market Analysis. 2024–2025. Market sizing and CAGR data.
- Mordor Intelligence. Enterprise Data Management Market Report. 2025.
- IRJMETS (International Research Journal of Modernization in Engineering Technology and Science). Enterprise Data Architecture and Digital Transformation ROI. 2025. 42% and 35% benchmark figures.
- ResearchGate. Enterprise Architecture Maturity and Digital Initiative Implementation Speed. 2024–2025. 43% faster implementation finding.
- Informatica / Gilead Sciences. Case study reference. Data mesh and governance implementation. [informatica.com/customers]
- Improvado. ASUS data consolidation and marketing analytics integration case study. [improvado.io/customers]


.webp)







