AI-Ready Data Infrastructure: Get Your AI From Pilot to Production
DATAFOREST engineers have built AI-ready data infrastructure across healthcare, finance, retail, and manufacturing—getting AI initiatives past pilot and into production.
Sagis Diagnostics: 50% compute cost reduction, 21 data sources unified on an AI-ready infrastructure.




PARTNER

PARTNER
FEATURED IN

.svg)








.svg)
.svg)
.svg)
AI pilots that never reach production
Data scientists spend up to 30% of their time searching for and preparing data instead of building models. Without a governed, pipeline-ready data infrastructure, every AI initiative stalls at the same point—the data layer.

Infrastructure debt compounding quarterly
Legacy platforms cost significantly more than modern cloud-native alternatives. Organizations allocating ~30% of IT budgets to data management still see only 12% achieve AI maturity. You're spending more and getting less.

GenAI without the foundation
RAG applications, agent architectures, and fine-tuning workflows all require infrastructure that most organizations don't have—vector databases, embedding pipelines, feature stores, and real-time serving layers. Without them, GenAI stays in the demo stage.


Stop Letting Infrastructure Hold Back Your AI Strategy
See what's preventing your AI initiatives from reaching production—and get a practical roadmap to fix it.
AI-Ready Data Infrastructure Services That Move You From Legacy to Production AI
DATAFOREST delivers AI-ready data infrastructure across seven core capabilities—each engineered to close the gap between your current data state and production-grade AI operations.
01
Unified Data Architecture Design
02
Scalable Data Pipeline Engineering
03
GenAI & RAG Infrastructure
04
Data Governance, Security & Compliance
05
Legacy-to-AI Infrastructure Migration
06
MLOps & AI Lifecycle Management
07
FinOps & Infrastructure Cost Optimization
Technology Stack for AI-Ready Infrastructure: Choosing the Right Platform
Dimension
Databricks
Snowflake
Google BigQuery
Core strength
Unified lakehouse for analytics + ML + GenAI
Cloud data warehouse with cross-cloud governance
Serverless warehouse with native Google AI
AI/ML readiness
Native — MLflow, Mosaic AI, feature stores built in
Growing — Cortex AI, ML functions, but requires external tooling for deep ML
Strong — BigQuery ML, Vertex AI integration, LLM functions
RAG & GenAI support
Vector search in Delta Lake, LLM serving via Model Serving
Cortex Search, Snowpark Container Services for custom models
Vertex AI integration, vector search in BigQuery
Governance
Unity Catalog — centralized access, lineage, quality
Horizon — cross-cloud governance, object tagging
Dataplex — metadata management, data quality
Real-time capability
Structured Streaming, Real-Time Monitoring (RTM)
Snowpipe Streaming
BigQuery Streaming, Pub/Sub integration
Cost model
DBU-based, committed, or pay-as-you-go
Credit-based, auto-suspend for idle warehouses
On-demand per TB scanned or flat-rate slots
Best for AI infrastructure
Organizations combining analytics, ML, and data engineering on one AI-ready platform
Enterprises needing high-concurrency analytics with growing AI capabilities
Teams requiring fast SQL analytics with native Google AI ecosystem
When to combine platforms: Most enterprise AI infrastructure uses elements of multiple platforms. A Databricks lakehouse as the ML and analytics core with Snowflake for high-concurrency BI and BigQuery for Google-ecosystem workloads is increasingly common. We design the right multi-platform architecture for your AI maturity and workload mix.
Feature Stores & Vector Databases: The GenAI Infrastructure Layer
Modern AI infrastructure extends beyond traditional platforms. RAG applications and ML systems require specialized infrastructure:
Component
Options
When to Use
Vector databases
Pinecone, Weaviate, Milvus, pgvector
RAG applications, semantic search, and embedding storage
Feature stores
Feast, Tecton, Databricks Feature Store
ML feature management, real-time feature serving
Embedding pipelines
Custom (Spark + model serving), managed services
Converting unstructured data to vector representations
Model registries
MLflow, Weights & Biases, SageMaker
Model versioning, experiment tracking, and deployment

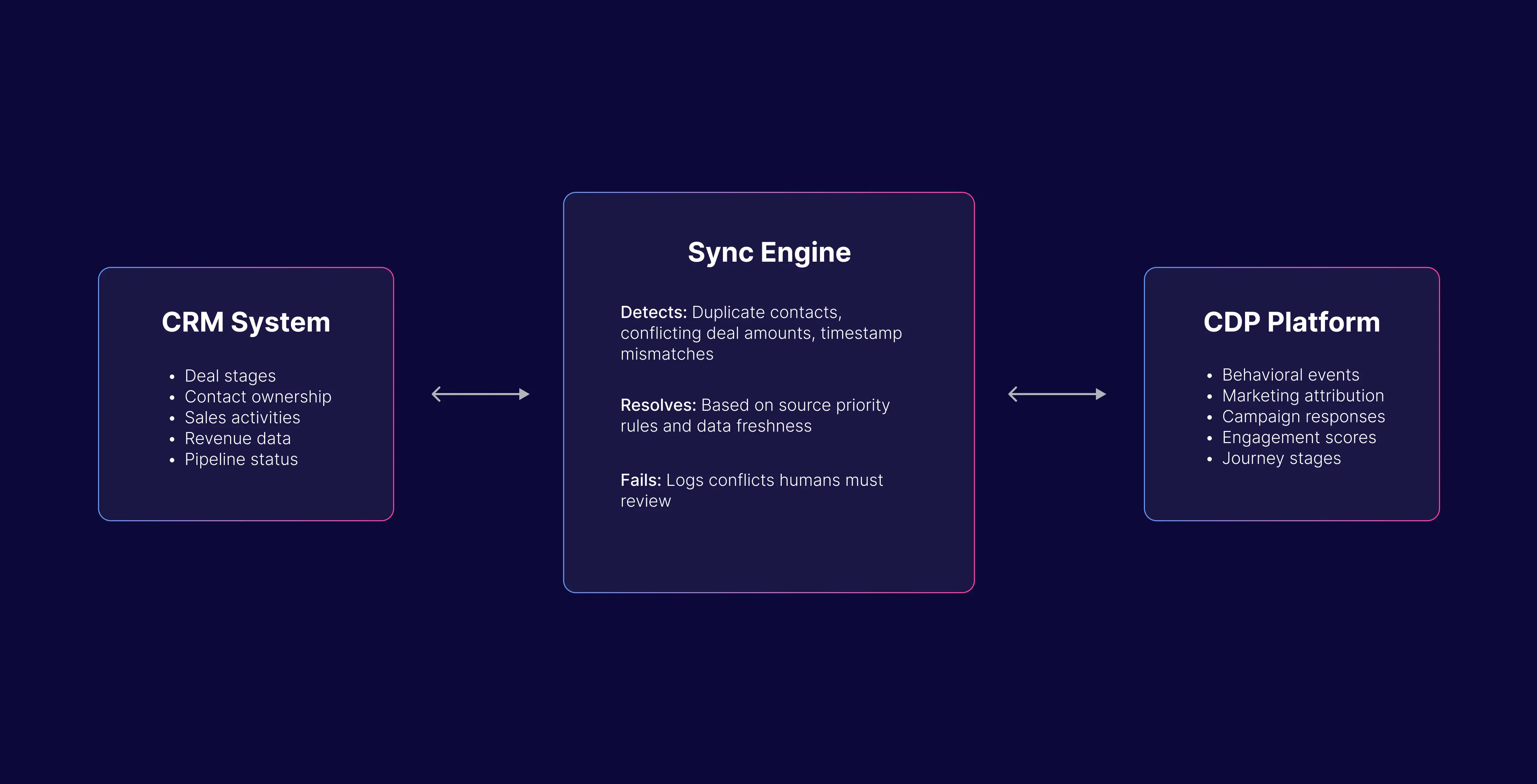
The DATAFOREST AI Infrastructure Acceleration Framework
Every phase has defined deliverables, validation checkpoints, and rollback protocols. You never move forward until the current phase is verified.
.svg)
Phase 1: Data Landscape Audit (Weeks 1–3)
Assess your current data infrastructure—platforms, pipelines, storage, governance gaps, AI readiness, and integration bottlenecks. Build a TCO model comparing your current costs to projected modern infrastructure costs.
Deliverables: Infrastructure maturity scorecard, data source inventory, AI readiness assessment, technology evaluation matrix, risk register, TCO comparison framework.
Deliverables: Infrastructure maturity scorecard, data source inventory, AI readiness assessment, technology evaluation matrix, risk register, TCO comparison framework.
01

Phase 2: Architecture Blueprint & Technology Selection (Weeks 3–5)
Select the right platform architecture and technology stack for your AI workloads. Design governance frameworks, map migration sequencing, and validate the approach with a proof-of-concept before committing to full rollout.
Deliverables: Target AI infrastructure architecture blueprint, technology selection rationale with vendor comparison, governance framework, migration sequence with rollback checkpoints, and PoC validation results.
Deliverables: Target AI infrastructure architecture blueprint, technology selection rationale with vendor comparison, governance framework, migration sequence with rollback checkpoints, and PoC validation results.
02

Phase 3: Foundation Build—Pipelines, Governance, Storage (Weeks 6–14)
Phased infrastructure built with validation at each checkpoint. Pipeline engineering, schema deployment, access management, governance implementation, and integration testing in parallel workstreams.
Deliverables: Production-ready data pipelines, deployed governance layer, storage infrastructure, automated testing suites, performance benchmarks vs. legacy baselines.
Deliverables: Production-ready data pipelines, deployed governance layer, storage infrastructure, automated testing suites, performance benchmarks vs. legacy baselines.
03
.svg)
Phase 4: AI Workload Integration & Testing (Weeks 10–16)
Connect AI/ML workloads to the new infrastructure. Feature store implementation, model serving infrastructure, RAG pipeline deployment, and end-to-end validation under production-like conditions.
Deliverables: Integrated AI workload environments, feature store and model registry, RAG infrastructure (if applicable), load testing results, and performance validation.
Deliverables: Integrated AI workload environments, feature store and model registry, RAG infrastructure (if applicable), load testing results, and performance validation.
04
.svg)
Phase 5: Production Deployment & Knowledge Transfer (Weeks 14–20)
Cut over from legacy systems with zero-downtime migration protocols. Each data domain migrates independently with rollback gates. Full documentation and team training so your engineers own the infrastructure.
Deliverables: Production deployment, migration validation reports, runbooks, architecture documentation, and team training sessions.
Deliverables: Production deployment, migration validation reports, runbooks, architecture documentation, and team training sessions.
05

Phase 6: Ongoing Optimization & Support (Optional Retainer)
FinOps tuning, performance monitoring, schema evolution, and infrastructure scaling. We don't hand you a platform and disappear—92% of our clients return because we build partnerships, not projects.
Deliverables: Cost optimization reports, performance dashboards, quarterly infrastructure reviews, scaling recommendations.
Timeline benchmarks: Initial AI infrastructure pilots reach production in approximately 12 weeks. Full enterprise AI infrastructure implementations take 6–12 months, depending on scope and complexity. DATAFOREST moves from validation to production 4–6 months faster than the industry average.
Deliverables: Cost optimization reports, performance dashboards, quarterly infrastructure reviews, scaling recommendations.
Timeline benchmarks: Initial AI infrastructure pilots reach production in approximately 12 weeks. Full enterprise AI infrastructure implementations take 6–12 months, depending on scope and complexity. DATAFOREST moves from validation to production 4–6 months faster than the industry average.
06
AI-Ready Infrastructure Built for Your Industry
We design AI and data infrastructure for sectors with different data volumes, compliance demands, and operational rhythms. Our project experience spans regulated environments, high-traffic commerce, and data-heavy digital products.
The numbers below represent the count of delivered AI and data infrastructure projects in an industry:
The numbers below represent the count of delivered AI and data infrastructure projects in an industry:

5
projects
projects
Financial services, fintech, banking, investment

5
projects
projects
Marketing, advertising, sales, data intelligence

4
projects
projects
E-commerce, retail

3
projects
projects
Healthcare, pharma, diagnostics
.svg)
2
projects
projects
IT services, SaaS

2
projects
projects
Media, entertainment

2
projects
projects
Manufacturing, logistics
01
Retail / E-commerce
- Unify ERP, eCommerce, POS, WMS, marketing, and customer data into a single governed platform.
- Enable real-time inventory visibility, pricing intelligence, demand forecasting, and personalized customer experiences.
- Create a clean foundation for recommendation engines, churn prediction, and margin optimization.
02
Healthcare
- Unify EHR, scheduling, billing, claims, telehealth, and operational data into one governed, compliant platform.
- Support secure data sharing, operational visibility, and performance analytics across clinical and administrative workflows.
- Build a trusted foundation for AI copilots, document processing, forecasting, and care coordination with strong governance, privacy, and access control.
03
Finance / Insurance
- Connect policy, claims, CRM, billing, and risk data with strong governance, lineage, and access controls.
- Support fraud detection, underwriting analytics, customer 360, and faster regulatory reporting.
- Prepare structured and unstructured data for AI copilots, document intelligence, and decision automation.
Medical Lab Achieves 50% Compute Savings via Databricks Migration
Sagis Diagnostics, a leading U.S. pathology lab, replaced its fragmented Azure SQL setup with a unified Databricks Lakehouse built by Dataforest. The migration consolidated 21 data sources, automated analytics, and ensured HIPAA compliance — delivering full data transparency, pay-per-use efficiency, and a ~50% reduction in compute costs.
.webp)

Medical Lab Achieves 50% Compute Savings via Databricks Migration
U.S. Manufacturer Unifies Enterprise Data, Cuts Manual Work 80–90%
A U.S.-based industrial solutions provider growing through acquisitions needed to unify fragmented ERP data into a scalable reporting foundation. We designed and implemented a Medallion Architecture in GCP with an automated Python-based ingestion framework, standardizing sales, customer, and location data across all entities—eliminating manual Excel consolidation and enabling real-time, acquisition-ready executive reporting in Power BI.
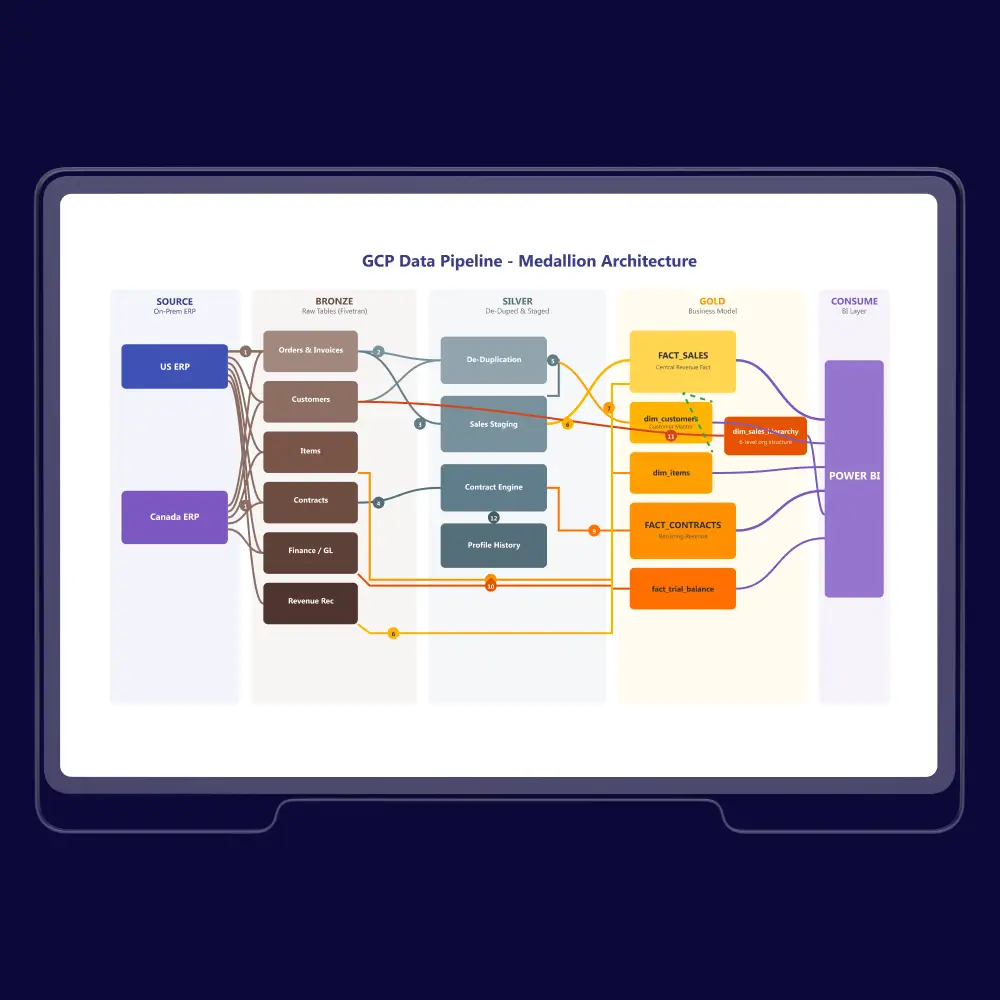
Enterprise Data Platform with Medallion Architecture
All Success Stories
250+
successful data and AI implementations
92%
client return rate
18 years
of data engineering expertise
100+
engineers across data, ML, and DevOps
4–6 months faster
from validation to production versus the industry average
How DATAFOREST Compares: AI Infrastructure Partners
Dimension
Product-Led Vendors
Generic Consultancies
DATAFOREST
Approach
Sell their own platform — recommendations biased toward their product
Vendor-agnostic but shallow on implementation
Vendor-neutral consulting: we recommend the right stack, not our own SaaS
AI infrastructure depth
Traditional ML focus; no RAG/GenAI infrastructure coverage
Strategy decks, not production pipelines
GenAI-native: RAG pipelines, vector DBs, feature stores, agent orchestration
Proof
Third-party examples or zero case studies
Logo walls, no metrics
Named case studies with quantified before/after metrics across 250+ implementations
Process transparency
Educational "how-to" guides, not engagement processes
Generic frameworks
6-phase engagement with timelines, deliverables, and rollback gates at every phase
Technology breadth
Single-platform bias
Depends on available talent
Deep expertise across Databricks, Snowflake, BigQuery — Official Databricks Consulting Partner
Cost transparency
No pricing signals
Opaque retainers
TCO modeling in Phase 1; engagement sizing during assessment
Post-launch
Product support only
Handoff and exit
Ongoing optimization and 92% client return rate
Why You Can Trust DATAFOREST With Your AI Infrastructure
Technology Partnerships:
Compliance Capabilities:
Recognition:


.avif)

Get Your Architecture Assessment
AI-Ready Data Infrastructure Built by Engineers Who've Shipped 250+ Data Systems—From Legacy to Production AI.
Stop funding infrastructure debt. Start with a discovery assessment that gives you an AI readiness scorecard, data source inventory, technology evaluation, and TCO comparison — so your CFO gets a business case, not a slide deck.
Stop funding infrastructure debt. Start with a discovery assessment that gives you an AI readiness scorecard, data source inventory, technology evaluation, and TCO comparison — so your CFO gets a business case, not a slide deck.
92%
client return rate
250+
successful implementations
Databricks
Consulting Partner
Related articles
All publications
March 16, 2026
16 min
Modern Data Architecture: The Decision-maker's Guide (2026)

March 10, 2026
17 min
What Is Data Architecture? The Complete Guide to Types, Frameworks, and Implementation [2026]

March 2, 2026
24 min
2026 State of Modern Data Architecture: Benchmark Report
AI-Ready Data Infrastructure FAQ
What does an AI-ready data infrastructure include?
AI-ready data infrastructure is the complete ecosystem that makes AI work in production: data pipelines (batch and streaming), unified storage (lakehouse, warehouse, or hybrid), governance frameworks, ML infrastructure (feature stores, model registries, serving pipelines), and GenAI-specific layers (vector databases, embedding pipelines, RAG infrastructure). It's everything between your raw data sources and a production AI model — built to scale, governed, and optimized for cost.
How long does it take to build AI-ready infrastructure?
Initial pilots reach production in approximately 12 weeks. Full enterprise AI infrastructure implementations take 6–12 months, depending on the number of data sources, compliance requirements, and migration complexity. DATAFOREST moves from validation to production 4–6 months faster than the industry average through phased delivery with parallel workstreams.
What does an AI infrastructure engagement cost?
Cost depends on scope, data complexity, number of source systems, and target architecture. DATAFOREST builds a TCO model in Phase 1 so you can see projected costs versus what your current infrastructure costs annually. Use our pricing calculator for initial estimates.
Can you work with our existing technology stack?
Yes. Most AI infrastructure builds involve integrating dozens of existing systems — CRMs, ERPs, SaaS applications, legacy databases, IoT streams, and third-party APIs. We support integration through Apache Kafka for streaming, dbt for transformation, Airflow for orchestration, and native connectors for Databricks, Snowflake, and BigQuery. One engagement consolidated data from multiple marketing platforms into an automated collection system with daily updates — integration complexity across heterogeneous sources is what we do across 250+ implementations.
How is this different from hiring a data engineering team?
A data engineering team gives you engineers. AI-ready data infrastructure requires architecture design, technology selection, governance frameworks, MLOps foundations, and GenAI infrastructure patterns — capabilities that take years to build in-house. DATAFOREST provides the full team — data architects, ML engineers, DevOps, and project management. You get production infrastructure, not a hiring process.
Do you support RAG and GenAI workloads?
Yes — we build the infrastructure layer that makes RAG, fine-tuning, and agentic AI work in production: vector database deployment (Pinecone, Weaviate, pgvector), embedding pipelines, prompt caching, guardrails infrastructure, and agent orchestration foundations. Our gen AI data infrastructure expertise converts unstructured data into high-quality, AI-ready resources that power generative AI data pipelines.
What industries do you serve?
Healthcare, financial services, retail and e-commerce, manufacturing and IoT, insurance, travel, real estate, and utilities. Each vertical has distinct compliance requirements, data patterns, and AI infrastructure demands — we design architecture patterns specific to your industry, not generic templates.
What certifications and partnerships do you have?
Official Databricks Consulting Partner, with deployment experience across AWS, Azure, GCP, and Snowflake. HIPAA compliance demonstrated in production implementations. Clutch 1000 for 5 consecutive years, with The Manifest recognizing DATAFOREST as Estonia's Most Reviewed Machine Learning Leader.
What's the cost of NOT modernizing our data infrastructure?
According to Gartner, poor data quality costs businesses an average of $12.9 million annually. Organizations without modern data governance face an 80%+ risk of digital initiative failure. Meanwhile, the global AI market is racing toward $2 trillion by 2030, and companies that can't operationalize AI at scale will lose ground every quarter. Infrastructure debt compounds, and the gap widens.
Let’s discuss your project
Share project details, like scope or challenges. We'll review and follow up with next steps.



