

Poor data architecture costs the average enterprise $12.9 million every year, according to Gartner. Yet according to IBM's 2025 Chief Data Officer Study, more than 25% of organizations lose over $5 million annually to data quality failures—and most of them can't describe what their data architecture actually looks like, or whether they have one at all.
That's the uncomfortable truth about data architecture: it's not a technical exercise that happens in the background. It's a business decision that costs real money with a measurable price tag for getting it wrong. Every reporting delay, every failed AI initiative, every compliance breach traces back to architectural choices—or the absence of them.
This guide covers what data architecture is, how it's built, and how to know whether yours is working. Specifically, you'll learn:
- How to choose the right architecture type for your organization using a practical decision framework
- A phased implementation roadmap with realistic timelines and team requirements
- A five-level maturity model to assess where your organization stands today
Whether you're a data architect evaluating a modernization project or a CTO building the business case for investment, this is the resource for you. Book a call to stay ahead in technology.

Key takeaways
- Poor data architecture costs enterprises $12.9 million annually on average (Gartner)—making architecture decisions a CFO concern, not just a technical one.
- Most organizations that self-assess as "Level 3" on the data architecture maturity scale are actually operating at Level 2—a gap that consistently delays AI initiatives.
- Building data architecture for AI workloads requires specific structural changes—vector databases, feature stores, real-time inference pipelines, and scalable AI data infrastructure services that support production AI systems.
- 69% of U.S. organizations run legacy data warehouses more than eight years old, according to MarketReportsWorld. Modernization is not optional for organizations pursuing AI.
What is data architecture—and why getting it wrong costs $12.9 million a year
Data architecture is the set of rules, policies, models, and standards that define how data is collected, stored, integrated, and used across an organization. It's the blueprint that governs where data lives, how it moves, who can access it, and what form it takes at each stage.
Think of it as the structural engineering behind your data systems—not the systems themselves, but the principles and designs that determine how those systems fit together. A data warehouse is a tool. The architecture is the decision about when to use a warehouse, how it connects to upstream ingestion and downstream analytics, and what governance rules apply to it.
This distinction matters because most organizations confuse having data systems with having data architecture. They have warehouses, lakes, dashboards, and pipelines. What they lack is intentional design: documented decisions about why those systems exist, how they relate, and what happens when requirements change.
Data architecture is a business decision with a measurable price tag for getting it wrong. Gartner estimates the annual cost of poor data quality at $12.9–15 million per enterprise. IBM's 2025 CDO Study found that more than 25% of organizations lose over $5 million yearly specifically because of data quality failures that stem from architectural gaps. And according to Gartner, 20–30% of enterprise revenue is lost to data inefficiencies that better architecture would prevent.Addressing these inefficiencies requires a structured approach to data architecture modernization, ensuring that legacy bottlenecks don't drain the company's budget.
What data architecture covers
A complete data architecture addresses six areas:
- Data sources: What systems generate data (CRMs, ERPs, IoT sensors, APIs, third-party feeds)
- Storage design: Where data persists and in what form (warehouse, lake, lakehouse, or hybrid)
- Integration: How data moves between systems (ETL, ELT, event streaming, CDC)
- Governance and security: Who can access what, under which policies, with what audit trails
- Metadata management: How data is cataloged, described, and made discoverable
- Analytics and AI serving: How downstream consumers - reports, models, applications - access prepared data
What data architecture is not
Data architecture is not the same as data modeling (which focuses on schema design within a specific system), data engineering (which builds and operates the pipelines), or information architecture (which organizes content for human navigation). All three intersect with data architecture, but none replace it.
Reporting Solution for the Financial Company


Enra Group is the UK's leading provider and distributor of specialist property finance.
What are the core components of a modern data architecture?
Modern data architecture is not monolithic. It's a system of interconnected components, each with a specific role. Understanding each one prevents the most common architectural mistake: building systems that can't talk to each other.
Data sources and ingestion
Data enters your architecture from operational systems - databases, SaaS applications, streaming feeds, files, and external APIs. The ingestion layer determines how that data is captured: in batch (scheduled extracts), in real time (event streaming via Apache Kafka or AWS Kinesis), or through change data capture (CDC), which logs row-level changes in source databases without full extracts.
Ingestion design decisions here have downstream consequences. Organizations that treat ingestion as an afterthought often end up with duplicated data, missed events, and schema drift—all of which compound over time.
Storage layers: warehouse, lake, and lakehouse
The storage layer is where most architecture decisions get contentious. The three dominant patterns - warehouses, lakes, and lakehouses - are covered in detail in the types section below. At the component level, what matters is that your storage design matches your access patterns.
Structured reporting workloads favor warehouses. Unstructured or exploratory workloads favor lakes. Organizations that need both without duplicating data are driving adoption of the lakehouse pattern.
Integration and transformation (ETL/ELT)
Transformation is where raw data becomes useful data. ETL (extract, transform, load) processes data before it lands in storage. ELT (extract, load, transform) lands raw data first and transforms it on read or within the warehouse using tools like dbt.
The shift from ETL to ELT reflects the rise of cloud warehouses with sufficient compute to run transformations at scale (they can load all data first and transform later). Which approach is right depends on your source systems, latency requirements, and tooling budget.
Governance, security, and metadata
Governance is the layer that makes data trustworthy and regulatorily compliant. It includes data classification (which data is sensitive, regulated, or public), access control policies, lineage tracking (where a record came from and how it's been transformed), and quality rules (what constitutes a valid record).
Without governance built into the architecture, it gets bolted on later—at far higher cost and with significant gaps.
Analytics and AI serving layer
The serving layer is where prepared data meets consumers: BI dashboards, data science notebooks, production AI models, and application APIs. Architecture decisions here determine query performance, freshness of data, and what latency is acceptable. For AI workloads specifically, the serving layer must extend to vector databases and feature stores—a requirement that most conventional architectures don't plan for.
Types of data architecture: selection criteria for your organization
The biggest gap in every competing guide on this topic is the absence of selection guidance. Listing architecture types without helping you choose between them is like listing car models without mentioning that some don't have four-wheel drive.
The table below covers the six architecture patterns you're most likely to evaluate—including the data lakehouse, which none of the top-ranking guides on this keyword acknowledge, despite it being the fastest-growing segment of the market.
Data warehouse
The data warehouse is the oldest and most mature pattern. Data is structured, cleaned, and loaded into a relational schema optimized for query performance. Cloud warehouses—Snowflake, BigQuery, Redshift—have removed the capacity constraints of on-premises predecessors and added columnar storage for analytical queries.
Warehouses excel at structured reporting and are the right choice for organizations with well-defined data domains and stable schemas. The limitation is schema rigidity: when source systems change, warehouse schemas break, and the transformation work required to reconcile changes is expensive.
Data lake
A data lake stores raw data in its native format—structured tables, semi-structured JSON or XML, unstructured text, images, audio—typically on object storage like Amazon S3 or Azure Data Lake Storage. The flexibility is the point: you store everything now and decide how to use it later.
The practical problem with data lakes is that "decide later" often means "never govern." Lakes routinely become what practitioners call "data swamps"—repositories with poor metadata, no lineage, and data consumers who can't trust what they're reading. Data lakes require stronger governance discipline than warehouses, not less.
Data lakehouse
The data lakehouse market is projected to grow at 22.9% CAGR to over $66 billion by 2033, according to MarketResearch. Databricks and Snowflake have built their platforms around this paradigm.As organizations move away from maintaining parallel warehouses and lakes, the demand for specialized Modern Data Architecture services has shifted toward implementing open table formats.
The lakehouse uses open table formats—Apache Iceberg, Delta Lake—to impose warehouse-style structure (ACID transactions, schema enforcement, versioning) directly on object storage. The result is lake-scale storage at warehouse-grade query performance, without the data duplication that comes from maintaining both.
For organizations that previously ran a warehouse and a lake in parallel, constantly syncing data between them, the lakehouse eliminates that architecture. It's not a future concept. It's what most net-new enterprise architectures are being built on today.
Data mesh
Data mesh is an organizational and architectural pattern, not just a technology choice. It distributes data ownership to the domain teams that produce it—rather than centralizing all data in a single platform managed by a central team. Each domain team owns its data products and is accountable for their quality and availability.
The appeal is scalability and accountability. A central data team cannot keep up with the data needs of 20 autonomous product teams. Data mesh solves that bottleneck. The cost is high: it requires disciplined org design, a federated governance model, and self-service infrastructure—none of which are cheap or fast to build.
Data mesh is right for large enterprises with mature data cultures. It is almost certainly wrong for organizations with fewer than 500 employees or without dedicated domain engineering teams.
Data fabric
Data fabric is an integration architecture that provides a unified, policy-driven access layer across heterogeneous data sources—on-premises systems, multiple clouds, SaaS tools—without requiring data to be physically moved into a single store. It uses metadata, knowledge graphs, and automated integration to create a logical unified view.
The distinction from data mesh is important. Fabric is about connectivity across systems. Mesh is about organizational ownership of data products. They are not competing patterns; increasingly, they are complementary ones. Gartner has noted that the "fabric vs. mesh debate" is collapsing as organizations adopt elements of both.
Event-driven and streaming architecture
Event-driven architecture treats data as a continuous stream of events rather than records in a database. Apache Kafka is the dominant backbone for event streaming at scale. This pattern is essential for real-time fraud detection, IoT sensor processing, operational analytics, and any use case where latency between event occurrence and data availability must be measured in seconds, not hours.
The complexity cost is real. Event-driven systems require more operational expertise, more careful failure handling, and more rigorous testing than batch systems. If your use case can tolerate hourly or daily data freshness, the added complexity is rarely justified.

Data architecture frameworks compared: TOGAF, DAMA-DMBOK, and Zachman
Frameworks give structure to the practice of data architecture. They define what questions to ask, in what order, and how to document the answers. None of the three frameworks below is inherently superior—the right choice depends on your organization's size, existing governance maturity, and whether your data architecture initiative is standalone or part of a broader enterprise architecture program.
TOGAF
TOGAF, published by The Open Group, is the most widely adopted enterprise architecture framework globally. Its Architecture Development Method (ADM) is a phased process: Preliminary → Architecture Vision → Business, Data, Application, and Technology Architecture → Migration Planning → Implementation Governance → Architecture Change Management.
For data architecture specifically, TOGAF's Data Architecture phase defines what data the organization needs, where it lives, and how it should be managed. It's most useful when data architecture is embedded in a broader EA transformation, and it requires either an internal EA team or external advisory support to run well.
DAMA-DMBOK
The Data Management Body of Knowledge (DAMA-DMBOK), published by DAMA International, is the most data-specific of the three. It covers 11 knowledge areas: data governance, data quality, data integration and interoperability, metadata management, master and reference data, data warehousing and BI, document and content management, data security, reference and master data, data architecture, and data modeling.
For organizations building a data management practice from scratch—rather than fitting data architecture into an enterprise-wide EA program—DAMA-DMBOK is the more practical starting point. It speaks the language of data teams rather than enterprise architects.
Zachman Framework
Zachman is the oldest of the three, developed by John Zachman in 1987. It's a two-dimensional classification matrix rather than a methodology: rows represent audience perspectives (executive, business management, architect, engineer, technician, user), and columns represent architecture dimensions (what, how, where, who, when, why).
Its value is organizational, not procedural. Zachman tells you what artifacts to produce for which audience. It doesn't tell you how to produce them. For data teams, it's most useful as a documentation standard rather than a process guide.
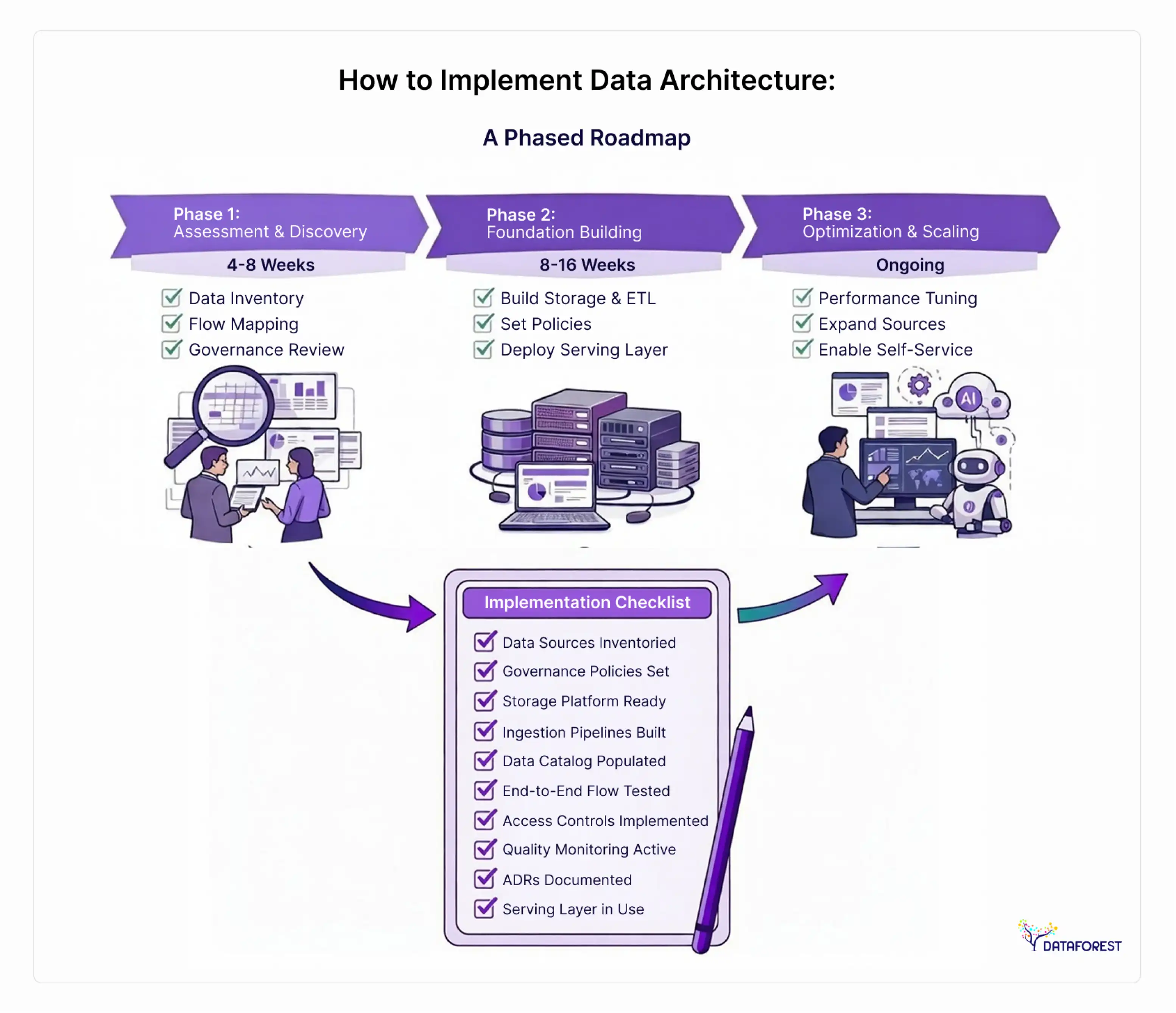
How to implement data architecture: a phased roadmap with timelines
AWS's 4-layer implementation model is the best structural framework currently available. But it stops where practitioners need it to start—it describes the layers without addressing who builds them, what tools are needed, or how long it takes.
Here's an implementation approach that addresses all three.
Phase 1: Assessment and discovery (4–8 weeks)
Before designing anything, you need to understand what you have. Most organizations discover that their actual architecture differs significantly from their perceived architecture during this phase.
What to do:
- Inventory all data sources, including shadow IT and business-owned spreadsheets
- Document current data flows (what moves where, at what frequency)
- Identify data consumers and their unmet needs
- Assess current storage systems (age, performance, maintenance costs)
- Evaluate governance maturity (what policies exist vs. what's enforced)
- Identify regulatory requirements (HIPAA, GDPR, PCI-DSS) that constrain design options
Who you need: Data architect (lead), 1–2 data engineers for technical inventory, business stakeholders from 3–5 key domains, data governance lead
Common failure at this phase: Skipping the governance assessment. Organizations that skip it design technically sound architectures that fail on access control, lineage, or compliance—and have to redo significant work.
Phase 2: Foundation building (8–16 weeks)
This is where architectural decisions become infrastructure. The length varies significantly based on migration complexity and whether you're greenfield (building new) or brownfield (modernizing existing).
What to do:
- Select architecture type and core storage platform
- Design ingestion patterns for each source category
- Build or procure the integration layer (ETL/ELT tooling)
- Establish governance policies and implement a data catalog
- Define data quality rules and monitoring
- Build the first serving layer for 2–3 priority use cases
- Document all architectural decisions (ADRs—architecture decision records)
Who you need: Data architect, 2–4 data engineers, data governance lead, 1 data analyst embedded to validate serving layer outputs
Build vs. buy decision criteria:
Common failure at this phase: Treating the foundation as complete before the serving layer is validated by actual users. Architectures that never get used by analysts because query performance is poor or data quality is untrusted don't survive organizational scrutiny.
Phase 3: Optimization and scaling (ongoing)
Once the foundation is operating with real workloads, you shift to optimization: query performance, cost efficiency, expanded coverage, and governance hardening.
What to do:
- Monitor query performance and cost per workload type
- Expand ingestion coverage to lower-priority sources
- Implement data mesh distribution if domain teams are ready
- Build self-service analytics capability for business users
- Mature metadata and lineage documentation
- Begin AI/ML serving layer if applicable (see AI section below)
Who you need: Data platform team (2–3 engineers), data governance team (1–2 people), domain data stewards per business unit
Implementation checklist
Use this to validate readiness before moving between phases:
- All data sources inventoried and classified by sensitivity
- Governance policies documented and approved by legal/compliance
- Storage platform selected and provisioned
- Ingestion pipelines built for all Tier-1 data sources
- Data catalog populated for all active tables/datasets
- At least one end-to-end data flow has been tested from the source to the serving layer
- Access controls implemented and tested against governance policy
- Data quality rules are defined, and monitoring is in place
- Architecture decision records (ADRs) are written for all major decisions
- At least two business teams are actively using the serving layer
Data architecture maturity model: assess where your organization stands
This model is designed to help you self-place, then identify the most impactful next steps.
A word of caution: organizations consistently overestimate their maturity level. The most common pattern is self-assessing at Level 3 while operating at Level 2. The characteristics below are intentionally specific for that reason.
Data architecture for AI: what changes in 2025–2026
Here's the thing that's driving urgent architecture modernization right now: AI makes bad data architecture impossible to hide.
According to IBM's 2025 Chief Data Officer Study, 43% of COOs now rank data quality as their top data priority—not because data quality suddenly became important, but because AI initiatives expose every gap that reporting tools quietly papered over. An AI model trained on inconsistent, ungoverned data doesn't produce a slightly wrong dashboard. It produces confidently wrong outputs at scale.
Designing data architecture for AI workloads requires additions that conventional warehouse or lake designs don't include.
Four structural requirements for AI-ready data architecture
Vector databases. AI applications using embeddings—semantic search, RAG (retrieval-augmented generation), recommendation engines—require vector databases purpose-built for similarity search. These are not replacements for your transactional or analytical databases; they're a new layer. Options include Pinecone, Weaviate, pgvector (PostgreSQL extension), and Chroma. Your architecture needs to define how vectors are generated, stored, updated, and queried.
Feature stores. Machine learning models are trained on features—engineered representations of raw data. Without a feature store, data science teams recompute the same features repeatedly, often inconsistently. A feature store (Feast, Tecton, or Databricks Feature Store) provides a shared repository of computed features that are versioned, discoverable, and reusable across models. It's the difference between model development that scales and model development that creates technical debt.
RAG architectures. Retrieval-augmented generation combines a large language model with real-time retrieval from your internal data. The data architecture requirement is specific: documents must be chunked, embedded, stored in a vector database, and kept current as source content changes. This is an active data pipeline requirement, not a one-time load.
Real-time inference pipelines. AI models serving real-time decisions—fraud scoring, personalization, anomaly detection—need data delivered in milliseconds. That requires event-driven architecture at the serving layer, not batch ETL.
AI-readiness checklist
Before pursuing AI initiatives, verify:
- Core structured data is governed, quality-monitored, and trusted by analysts
- Data catalog covers all datasets that AI models would consume
- Lineage is tracked well enough to audit model training data
- A feature store is either in place or planned for the model development phase
- Vector database infrastructure is provisioned for embedding-based use cases
- Real-time streaming capability exists for any low-latency AI application
- Data access controls extend to AI model training and inference pipelines
- Governance policies address AI-specific risks (model bias, training data retention, output logging)
Industry-specific architecture patterns
Healthcare, financial services, retail, and manufacturing have meaningfully different architectural requirements—driven by regulatory constraints, data volume profiles, and latency needs. The table below captures the most important distinctions.
Choose what is important to you and order a call.
Healthcare scenario
A 12-hospital health system implemented a data mesh to comply with HIPAA requirements while enabling cross-department analytics. Previously, data requests between departments required manual privacy review and took two weeks to fulfill. After adopting a federated data product model with automated PHI access controls, fulfillment time dropped to two hours for approved use cases. The architectural key was building governance into the data product contract, not as a separate review step.
Financial services scenario
A mid-size asset manager consolidated from 12 separate data sources into a unified lakehouse architecture. Before migration, month-end regulatory reports required 72 hours of manual reconciliation. After, the same reports ran in under four hours from a single source of truth. The architecture decision that made this possible was adopting Apache Iceberg as the open table format, enabling both batch reporting and real-time risk calculations from the same dataset without data duplication.
Retail scenario
A regional retailer with 200+ locations implemented event-driven architecture for inventory management. Previously, inventory data was refreshed overnight. After building a streaming pipeline on Apache Kafka, inventory availability was updated within 60 seconds across all channels—reducing stockout-related lost sales by an estimated 12% in the first quarter of operation.

The cost of poor data architecture: building the business case
Data architecture is not a technical exercise—it's a business decision with a measurable price tag for getting it wrong. If you're building the internal case for investment, these are the numbers you need.
What poor data architecture costs
- $12.9–$15 million per year: Gartner's estimate of the average annual cost of poor data quality per enterprise—covering rework, failed analytics, delayed decisions, and compliance remediation.
- $5 million+ per year for 25%+ of organizations: IBM's 2025 CDO Study found that more than a quarter of organizations lose more than $5 million annually to poor data quality.
- 20–30% of enterprise revenue: Gartner research attributes losses in this range to data inefficiencies—delays, duplicate efforts, inaccurate reporting, and failed initiatives.
- 78% of enterprises manage data across 10 or more platforms (MarketReportsWorld). Every additional platform adds integration complexity and governance risk without a deliberate architecture managing it.
Cost estimation framework by organization size
These are directional ranges based on implementation patterns, not fixed quotes. Verify current tooling costs with vendors.
These ranges cover cloud infrastructure, tooling, internal engineering time, and advisory support for a first-generation modern data architecture. They do not include ongoing operations costs (typically 20–30% of initial build annually).
The ROI calculation
A simplified ROI framework for internal business cases:
- Quantify current cost: Estimate analyst hours spent on manual reconciliation + cost of reporting delays + estimated compliance risk exposure
- Estimate initiative value: Identify 2–3 analytics or AI use cases with quantifiable business impact
- Subtract implementation cost: Use the table above as a starting range
- Calculate payback period: Current annual cost ÷ (annual value unlocked − annual operational cost)
The strongest business cases pair this calculation with a specific AI initiative that's currently blocked by data architecture limitations. According to IBM's 2025 study, 43% of COOs identify data quality as their top priority because of AI, which means architecture investment increasingly has a direct tie to competitive positioning, not just operational efficiency.
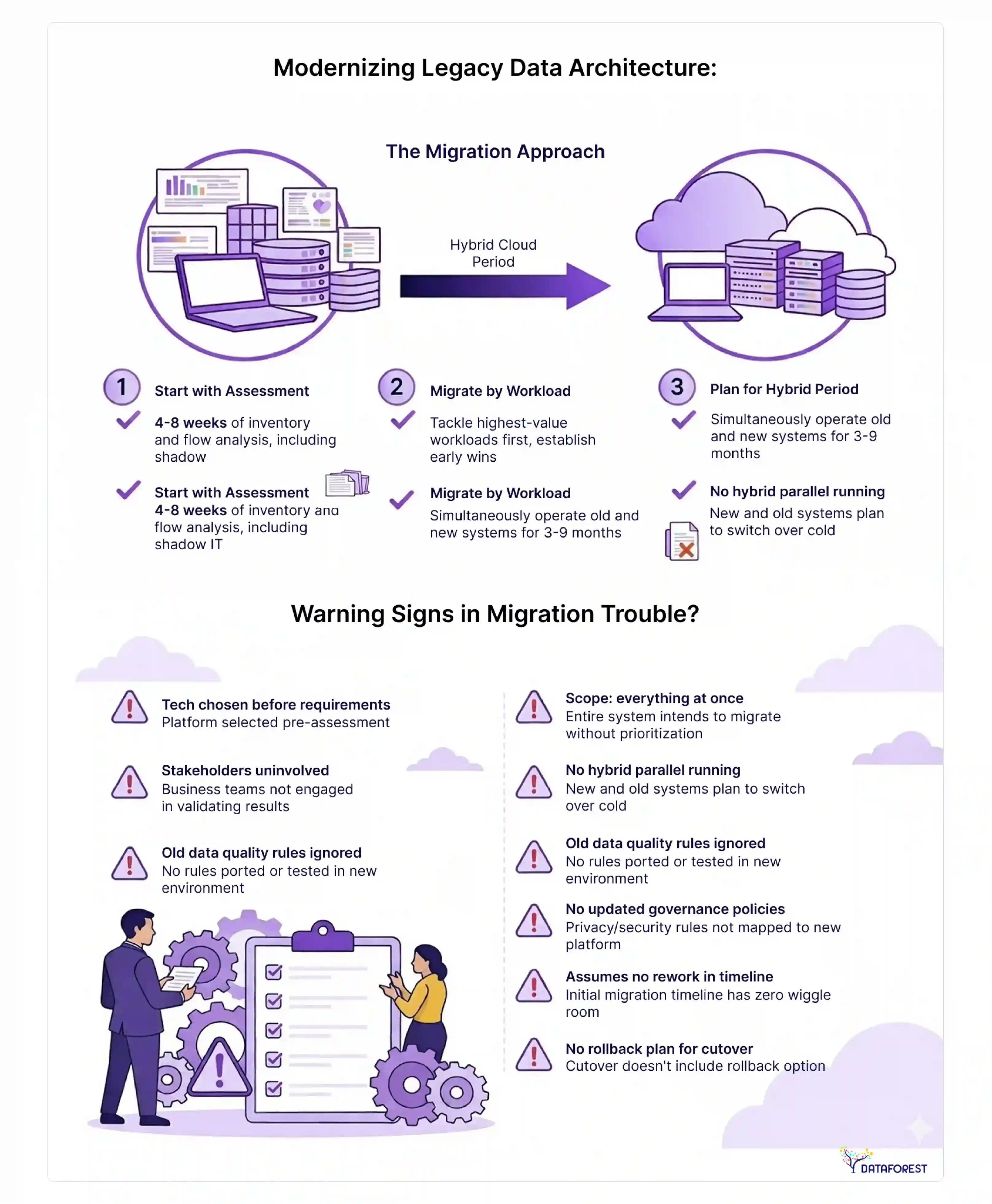
Modernizing legacy data architecture: a migration approach
According to MarketReportsWorld, 69% of U.S. organizations run legacy data warehouses more than eight years old. And 82% manage data across 15 or more applications. For most large enterprises, the question isn't whether to modernize—it's how to do it without breaking what currently works.
The migration approach
Start with assessment, not technology selection. Most failed migrations choose a platform before understanding what they're migrating. Organizations often rely on specialized data migration services to assess dependencies, preserve governance policies, and reduce the risk of downtime during large-scale modernization initiatives. Spend four to eight weeks on assessment (see the implementation roadmap above) before committing to any vendor.
Migrate by workload, not by system. Moving an entire legacy warehouse to a new platform in one lift is high-risk. Instead, identify the three to five workloads with the highest business value and migrate them first. This generates early wins, exposes integration challenges in a controlled scope, and builds team expertise before tackling complex migration work.
Plan for a hybrid period. Expect three to nine months of running old and new architecture in parallel. Design data flows so that source systems write to both; validate outputs match before cutting over. This is operationally expensive but far less expensive than a failed cutover.
Preserve what works. Legacy systems are often reliable exactly because they've been tuned over the years. Identify which ETL jobs, transformation logic, and business rules are correct and worth preserving—vs. which should be redesigned—before migration begins.
Warning signs that a migration is in trouble
- Technology was selected before the requirements were documented
- The migration scope is "everything at once"
- Business stakeholders are not involved in validating outputs
- No parallel running period was planned
- Data quality rules from the legacy system were not ported
- Governance policies were not updated for the new platform's access model
- Timeline assumes zero rework after initial build
- No rollback plan exists for the first production cutover
Common migration pitfalls and how to avoid them
The most expensive mistake in legacy modernization is treating it as a technical migration when it's actually a governance migration. The new platform might be faster and cheaper to operate—but if data consumers can't trust the outputs because lineage is broken, quality rules weren't ported, or access controls are misconfigured, the migration fails in practice even if it succeeds technically. Plan at least as much time for governance validation as for technical migration work.
Data architecture vs related disciplines
These distinctions come up in every architecture conversation, and the confusion is legitimate. The boundaries between disciplines are real but permeable.
Data architecture vs data modeling
Data modeling is a subset of data architecture. A data model defines the structure of data within a specific system—the entities, attributes, and relationships in a database schema. Data architecture is the broader system of decisions: which systems exist, how they connect, what governance applies, and how data flows between them.
An analogy: data modeling is like floor plans for a single room. Data architecture is city planning for the whole building and its relationship to neighboring infrastructure. You need both; one doesn't replace the other.
Data architecture vs data engineering
Data engineering builds and operates the systems that data architecture designs. An architect defines that a real-time streaming pipeline should connect source system A to lakehouse B. A data engineer builds that pipeline, maintains it, monitors it, and responds when it breaks.
In small organizations, one person often does both. In larger ones, the roles specialize. The distinction matters for hiring and team structure: data engineering is an execution discipline; data architecture is a design and governance discipline.
Data architecture vs information architecture
Information architecture is primarily a UX discipline—it organizes information for human navigation, typically in websites, intranets, documentation, and applications. Data architecture organizes data for machine storage, processing, and analysis.
The two intersect when building data-intensive applications where the data structure and the user experience are tightly coupled. But they're governed by different principles, serve different audiences, and involve different skills.
Supporting technologies: a selection guide
Profisee's guide lists 11 technology categories with named tools—the most practical coverage in any competing guide. What's missing is selection guidance. Here's what to use and when.
Is your data architecture ready for AI?
Data architecture is not a technical exercise—it's a business decision with a measurable price tag for getting it wrong. The $12.9 million annual cost of poor data quality, the AI initiatives stalling on ungoverned data, the regulatory fines from untracked access to sensitive records: all of these trace back to architectural choices made (or avoided) years earlier.
The organizations that are pulling ahead on data and AI right now aren't necessarily the ones with the most sophisticated technology. They're the ones with the most intentional architecture: clear decisions about what data exists, where it lives, how it flows, and who governs it.
The frameworks, maturity model, and roadmap in this guide are starting points. The right architecture for your organization depends on your workload profile, your team capacity, your regulatory constraints, and your AI ambitions.
If you're not sure where to start, use the maturity model to assess where you are today. Then pick one phase-one action from the implementation checklist and begin. Architecture improvements compound—small, governed steps outperform big-bang overhauls almost every time.
Please complete the form for a data architecture consultancy.
References
- Gartner. "The Financial Impact of Poor Data Quality." Referenced in IBM IBV 2025 CDO Study and QYResearch data architecture market report.
- IBM Institute for Business Value. CEO Study 2025 / Chief Data Officer Priorities 2025. IBM Corporation, 2025.
- QYResearch. Global Data Architecture Modernization Market Report. 2024.
- Market.us. Modern Data Stack Market Size and Forecast 2025–2035. 2025.
- MarketReportsWorld. Enterprise Data Management and Legacy Architecture Survey. Referenced 2025.
- DAMA International. Data Management Body of Knowledge (DMBOK), 2nd Edition. 2017 (framework reference - methodology, not market data).
- The Open Group. TOGAF Standard, Version 9.2. 2018 (framework reference - methodology, not market data).


.webp)







