

The enterprise data architecture market is no longer moving slowly. The data architecture modernization market was valued at $8.8 billion in 2023 and is on track to reach $24.4 billion by 2033 (Business Research Insights). At the same time, Gartner projects that 40% of enterprise applications will embed task-specific AI agents by the end of 2026, and most current data architectures aren't built to feed them. The gap between what organizations have built and what AI-native workloads actually require is closing fast, and the organizations still debating whether to modernize are already behind.
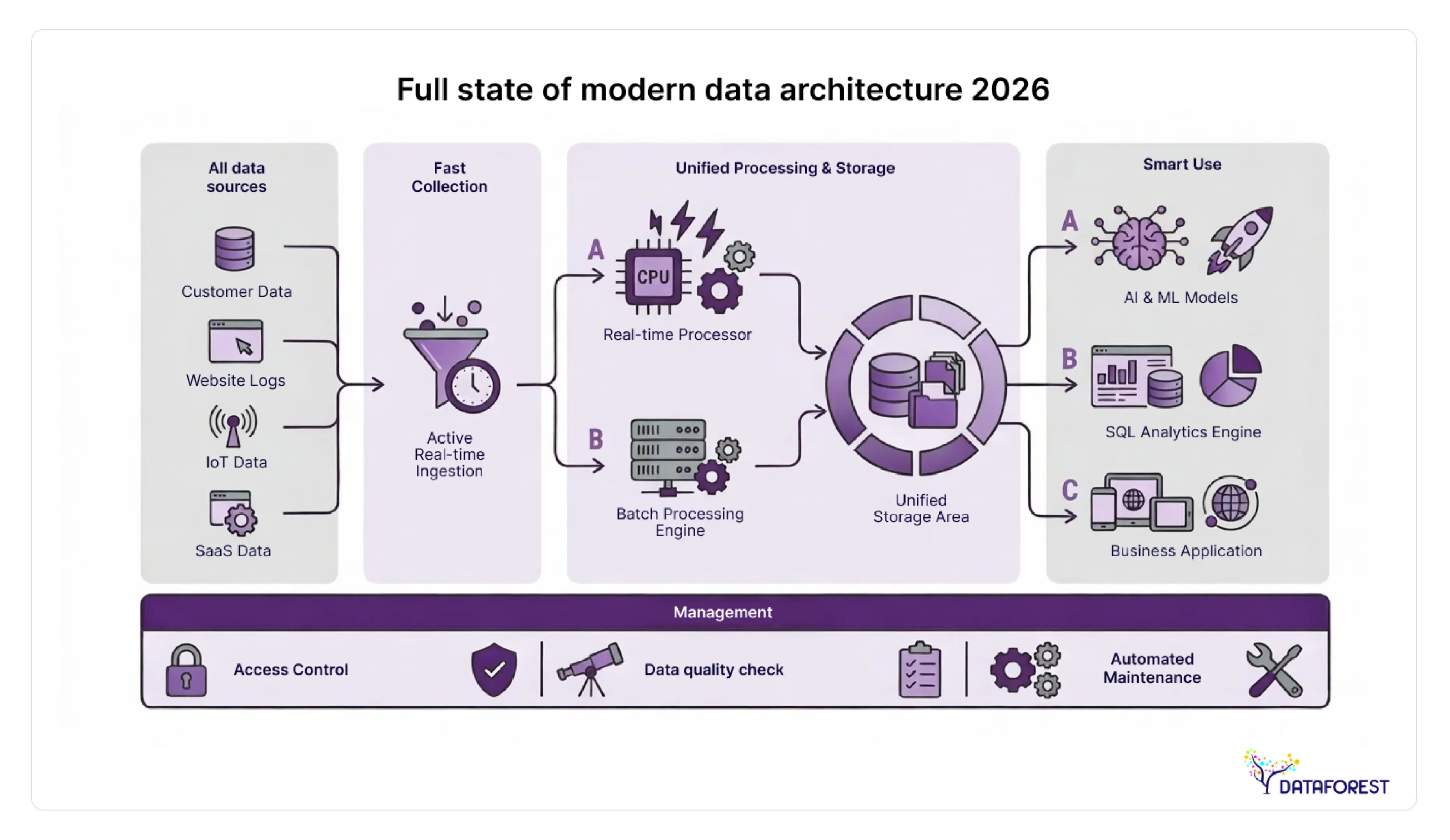
This report covers the full state of modern data architecture in 2026: which patterns are delivering results, what the convergence of Lakehouse, mesh, and fabric actually looks like in practice, what open table formats mean for your infrastructure decisions, how GenAI is reshaping architecture requirements, and where modernization projects go wrong. By the end, you'll have a quantified comparison of architecture patterns, a cost benchmark baseline, an industry-specific requirements matrix, and a 10-point audit checklist to assess your own modernization position.
TL; DR
- Market size: The data architecture modernization market is growing from $8.8B (2023) to $24.4B by 2033, a 10.7% CAGR (Business Research Insights).
- GenAI readiness gap: 67% of enterprises have deployed generative AI (Researchscape/Cloudera), but only 20% express high confidence in their data analysis capability (Ventana Research).
- AI agent adoption: Gartner projects 40% of enterprise applications will embed AI agents by the end of 2026 - most existing architectures can't serve them reliably.
- Lakehouse momentum: The data Lakehouse market is growing at 22.9% CAGR toward $66B by 2033 (MarketResearch), making it the fastest-growing architecture pattern.
- Data volume reality: 64% of enterprises manage more than one petabyte of data; 41% manage more than 500 petabytes (AvePoint AI & IM Report). Architecture isn't an abstract IT discussion - it's a matter of physical scale.
- Budget risk: Gartner reports that 60% of data infrastructure projects exceed their initial budget by at least 30%. Modernization is not a guaranteed win.
- Open table formats: No competitor content on this SERP covers Iceberg, Delta Lake, or Hudi—the actual infrastructure layer that determines whether lakehouses perform or fail.
Quick summary: GenAI deployment has raced ahead of data readiness, and the architectures most organizations built in 2020–2023 are not equipped for AI-native workloads. The question in 2026 isn't which architecture is "best"—it's whether your organization can govern, cost-control, and AI-enable whatever you've already built.
Executive Summary
The data architecture conversation in 2026 has changed character. Three years ago, the question was "should we modernize?" Today, most enterprises have made some move—migrated to a cloud warehouse, stood up a data lake, or launched a mesh initiative—and the new question is "is what we built actually working?" The honest answer is: often not quite.
The enterprise data management market reached $124.9 billion in 2025 and is growing at 12.11% CAGR toward $349.5 billion by 2034 (Precedence Research). That spending is not translating cleanly into capability. Only 20% of data leaders express high confidence in their organization's data analysis capability (Ventana Research), despite the majority having deployed cloud-native tools. Meanwhile, 78% of enterprises manage data across 10 or more heterogeneous platforms (Market Reports World, 2026)—which means even organizations that modernized one system are now managing sprawl.
The analytics market reached $104 billion in 2026 and is projected to grow to $496 billion by 2034 (Polestar/Grand View). The AI training dataset market, a subset driven by GenAI demand, reached $3.2 billion in 2025 and is on track to reach $16.3 billion by 2033 (Grand View Research). Both figures tell the same story: the economic pressure to get data architecture right has never been higher, and the cost of getting it wrong has never been more visible.
Modern data architecture at a glance: 2026 key metrics
The choice in 2026 is no longer between architectures—it's whether your organization can govern, cost-control, and AI-enable whatever you build. Tools are available. Budget pressure is real. The failure mode is usually organizational, not technical.
Audit tip: Run this test before any architecture decision: can your current platform serve a structured GenAI query—retrieve relevant context, apply access controls, and return a traceable result—within 48 hours of a new use case request? If not, you have architecture debt that affects AI delivery, not just analytics.
The Modernization Market in 2026
TL;DR:
- The modernization market is growing at 10.7% CAGR, reaching $24.4B by 2033.
- Data volumes are increasing faster than architectural capacity—394 zettabytes created globally by 2028 (Statista).
- The BLS projects 28% growth in demand for data architects through the decade.
- Investment is concentrated in lakehouse, fabric, and observability—not legacy warehousing.
What's driving architectural change
Global data creation will reach 394 zettabytes by 2028 (Statista). That's not a theoretical number - it's the direct cause of why architectures designed for 2019 data volumes break in 2026. At 64% of enterprises managing at least one petabyte today (AvePoint AI & IM Report), the scaling pressure is already present, not hypothetical.
Three forces are driving the current investment cycle:
- GenAI workloads require architectural capabilities—vector storage, low-latency retrieval, unstructured data management, and fine-grained access control—that most traditional data warehouses were not designed to provide.
- Regulatory pressure (GDPR, CCPA, the EU AI Act) is forcing organizations to build governance into architecture rather than applying it as an afterthought.
- Cost pressure from 2022–2024 cloud spending audits has pushed CFOs into data engineering conversations for the first time, creating demand for FinOps practices that treat data platforms as cost centers requiring active management.
Key market drivers and their architectural impact
The talent shortage deserves attention. A 28% projected increase in data architect demand (BLS) against a tight supply of people who understand both distributed systems and business requirements means most organizations will face a choice: simplify their stack or accept slower execution. That constraint shapes architecture decisions more than any vendor feature list.
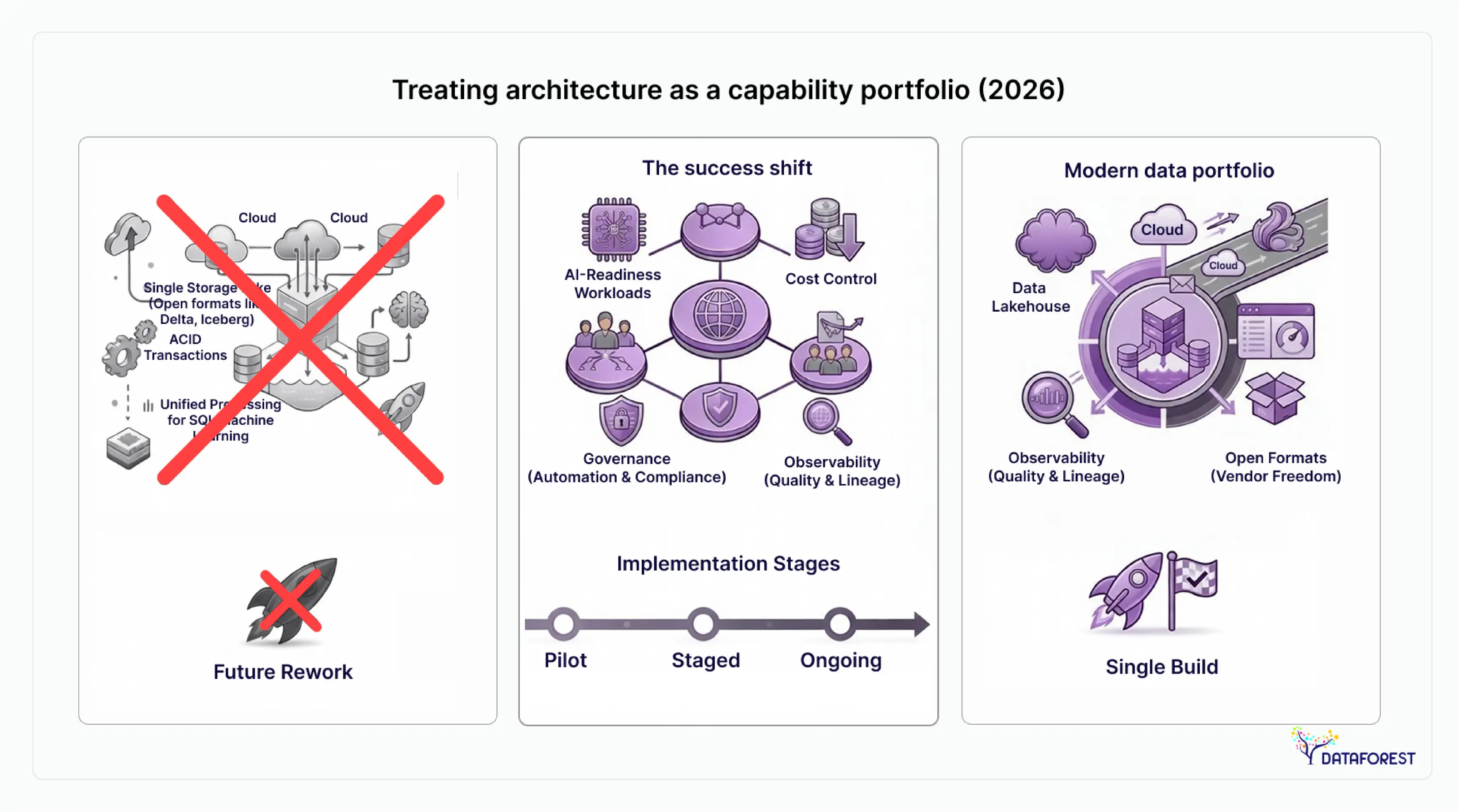
Architecture Patterns That Actually Deliver
TL;DR:
- The lakehouse is the fastest-growing pattern (22.9% CAGR) and the most AI-ready
- Data mesh and data fabric are not competing—the leading implementations combine both
- Kroger's 84.51° subsidiary runs one of the most documented hybrid implementations
- No single pattern dominates across all use cases; selection depends on team structure, data domain count, and governance maturity
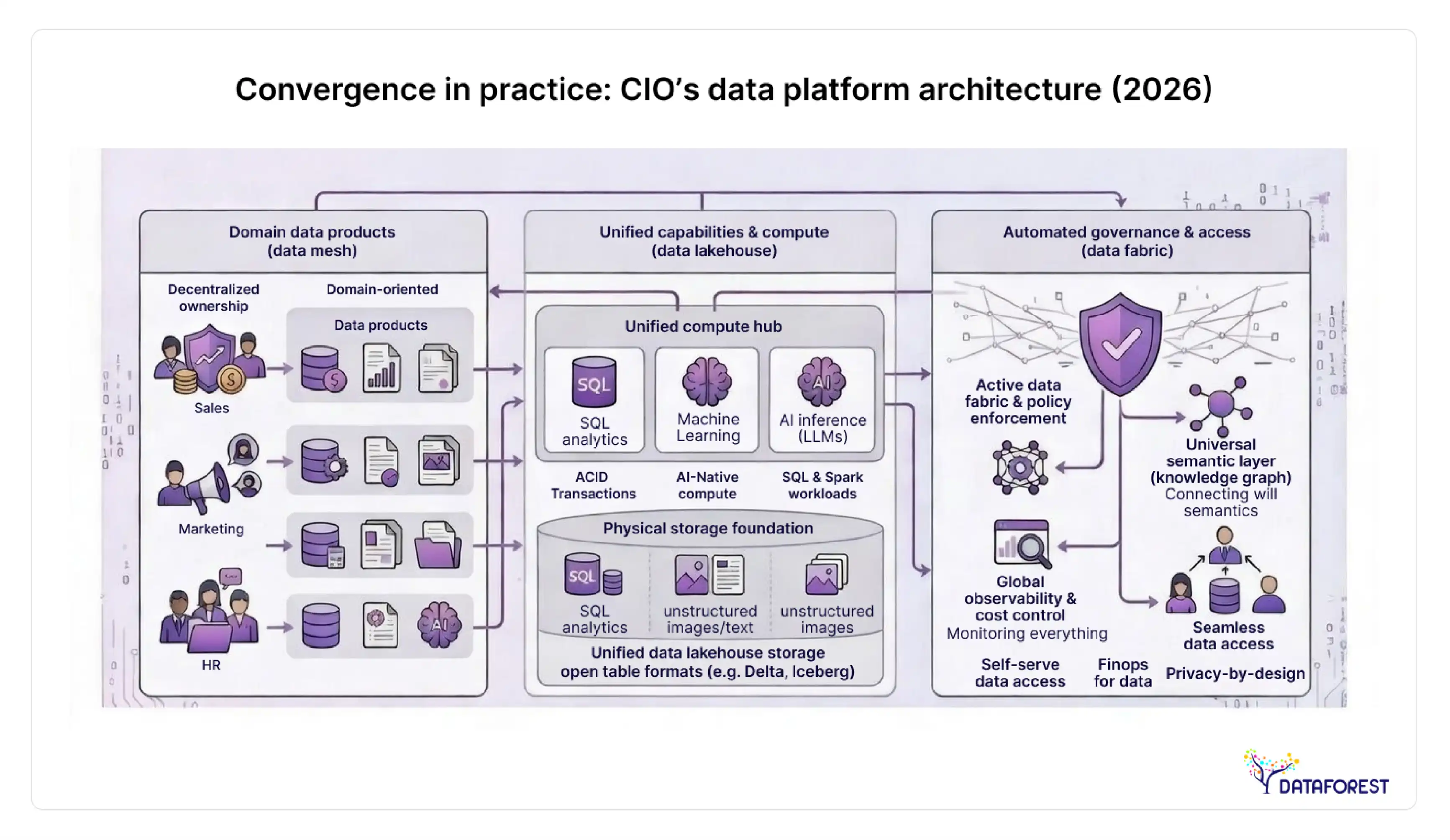
Lakehouse, mesh, and fabric: what each one actually does
The vocabulary around modern data architecture has become muddled. "Lakehouse," "mesh," and "fabric" describe different things—and many organizations implement all three simultaneously without realizing it. Before comparing them, it helps to be clear about what problem each one solves.
A data lakehouse is a storage and compute architecture: it stores data in open formats on object storage and applies warehouse-like query capabilities on top. The lakehouse pattern grows at 22.9% CAGR toward $66 billion by 2033 (MarketResearch) because it solves a concrete problem—the cost and rigidity of traditional cloud warehouses when data volumes are large, and query patterns are unpredictable.
A data mesh is an organizational and ownership architecture: it distributes data ownership to domain teams and treats datasets as products with defined interfaces, SLAs, and discoverability. It solves the bottleneck of centralized data engineering teams that can't keep up with demand across a large enterprise.
A data fabric is a metadata and integration layer: it uses active metadata, knowledge graphs, and AI-assisted data pipelines to connect disparate systems without requiring physical data movement. It solves the integration problem in organizations where data lives in many systems and cannot be consolidated centrally.
The critical insight, and one that no competitor in this SERP covers clearly: these are not competing options. Leading implementations in 2026 run all three—lakehouse as storage layer, fabric as integration and metadata layer, and mesh as the governance and ownership model.
Architecture pattern comparison: 8 evaluation criteria
Kroger / 84.51°: a documented hybrid implementation
Kroger's data science subsidiary, 84.51°, is one of the few publicly documented cases of a large enterprise running a data mesh and fabric hybrid in production. Nate Sylvester, VP of Architecture at 84.51°, described the implementation as a reorganization around data domains—where teams own their data products—with a fabric layer providing the metadata and integration connectors that let those domain products be discovered and consumed across the organization.
The architectural lesson from Kroger isn't that mesh and fabric are complicated. It's that mesh without fabric creates invisible silos—domains that own their data but can't surface it to other teams—and fabric without mesh creates a centralized bottleneck under a different name. The two patterns reinforce each other. Organizations that choose one without the other consistently report the same problem: either centralized teams are overwhelmed, or domain data can't be found.
Kaycee Lai, CEO of Promethium, made a similar observation in industry commentary: "Fabric supports mesh. The metadata layer is what makes distributed ownership operationally viable."
Quick takeaway: The mesh vs. fabric vs. lakehouse debate is effectively resolved by the organizations running these patterns at scale. The architecture that performs in 2026 combines lakehouse storage, fabric metadata, and mesh ownership. Organizations still choosing between them are solving the wrong problem.
Open Table Formats—The Infrastructure Layer Everyone Ignores
TL; DR:
- Apache Iceberg, Delta Lake, and Apache Hudi are the three open table formats that underpin lakehouse architecture.
- No competitor content ranking for this keyword covers these formats, which means no reader currently gets this context.
- Vendor alignment matters: Databricks favors Delta Lake; Snowflake has adopted Iceberg; AWS supports all three.
- Proprietary format lock-in carries a real switching cost, estimated at 20–40% above open-format alternatives.
Open table formats are the actual infrastructure decision underneath the lakehouse pattern. They determine interoperability, performance, governance capability, and vendor portability. Choosing a lakehouse architecture without understanding which table format underlies it is like choosing a car based on color and ignoring whether the engine exists.
What open table formats actually do
Traditional data lakes stored files in raw formats (Parquet, ORC, CSV) without a table layer, which meant no ACID transactions, no schema evolution, and no consistent query results across concurrent readers. Open table formats solve this by adding a metadata layer on top of object storage that enables:
- ACID transactions—reliable concurrent reads and writes without corruption.
- Time travel—querying data as it existed at any prior point.
- Schema evolution—adding or removing columns without rewriting the entire table.
- Incremental processing—reading only changed records rather than full table scans.
These aren't academic features. Without them, production analytics pipelines on data lakes fail intermittently, produce inconsistent results, and require expensive workarounds.
Open table format comparison: feature coverage by format
The vendor alignment column is the one that matters most for architecture decisions. If your primary compute platform is Databricks, Delta Lake is the native format—and Delta tables perform best inside that ecosystem. If you're standardizing on Snowflake or using multiple query engines, Iceberg is the safer choice because of its broader engine compatibility and Snowflake's native support. If your workloads are heavily streaming-first, Hudi's incremental processing model has historically been the strongest option, though Iceberg and Delta have both substantially closed that gap.
Practical benchmark: Target more than 80% of net-new table creation on open formats by the end of 2026. Any table written in a proprietary format today is a migration project in 2028. Benchmark your current ratio: how many of your production tables are on Iceberg, Delta, or Hudi vs. vendor-native formats?
GenAI's Real Demands on Data Architecture
TL; DR:
- 67% of enterprises have deployed GenAI, but only 20% are confident in their data analysis infrastructure (Researchscape; Ventana Research).
- 80% of enterprise data is unstructured—the format GenAI needs most and that most architectures handle worst.
- Gartner projects 40% of enterprise apps will embed AI agents by the end of 2026, creating new architectural demand for agentic data services.
- Data observability is now table-stakes: 2/3 of enterprises will invest in it by 2026 (ISG/Ventana).
There's something genuinely uncomfortable about the state of GenAI and data architecture in 2026. Enterprises moved fast—67% have deployed generative AI, according to the Researchscape/Cloudera survey—but the infrastructure supporting those deployments is often not keeping pace. The KPMG survey found that 50% of data leaders cite customer data analysis as their top GenAI value target, with 48% citing productivity. Yet Ventana Research finds only 20% of those same leaders are highly confident in their data analysis capability.
That gap between deployment and confidence is the architecture problem. GenAI workloads place specific demands on data infrastructure that differ materially from traditional analytics workloads.
What AI-native architecture actually requires
Traditional analytics workloads are structured, batch-oriented, and relatively predictable in their access patterns. A GenAI workload is none of those things. A retrieval-augmented generation (RAG) system needs low-latency access to unstructured content, a vector index for semantic search, fine-grained row- or column-level access control, and automated data freshness guarantees to prevent the model from retrieving stale context. A real-time recommendation system requires streaming ingestion, sub-second query response times, and lineage tracking tight enough to satisfy regulatory audit requirements.
Most architectures built before 2023 were not designed for any of that.
GenAI data architecture requirements vs. current readiness
The agentic AI inflection point
Here's the development that most data architecture discussions in 2026 still treat as future-tense, even though it's already present-tense: agentic AI systems. Gartner projects that 40% of enterprise applications will embed task-specific AI agents by the end of 2026. Data-specific agents—quality agents that flag anomalies, lineage agents that trace data provenance, and profiling agents that automatically classify sensitive fields—are already shipping from vendors such as Acceldata and Collibra.
This matters architecturally because agents don't just consume data. They write to it, transform it, and take actions based on it. An architecture that assumes all data writes come from human-initiated pipelines is not built for agentic systems. The shift is genuinely unsettling in a way that "AI will change everything" rhetoric usually isn't—there's something different about the prospect of data quality agents running correction pipelines at 3 am while no human is watching, and the audit trail for those actions needs to be architectural, not aspirational.
PhonePe: observability at 2000% scale
PhonePe, the Indian fintech platform, experienced a 2000% increase in infrastructure scale—a figure that illustrates the practical ceiling of architectures built without observability. When data volumes multiply by an order of magnitude, the problems you couldn't see before become outages. PhonePe's architecture evolution, documented as an Acceldata implementation case, involved adding a data observability layer that enabled real-time monitoring of pipeline health, data quality metrics, and anomalies across an infrastructure that had grown too large to monitor manually.
The lesson is not that observability is a nice-to-have. It's that every organization that grows into a data architecture eventually discovers that operating it blind is not an option.
Action: Audit your unstructured data estate before starting any GenAI project. Catalog it by type (documents, images, audio, video), classify it by sensitivity, and estimate the percentage that is AI-ready—meaning cleaned, structured enough for retrieval, and access-controlled. Target 60% catalogued within 90 days of a GenAI initiative launch. If you don't know what your unstructured data contains, your GenAI outputs will reflect that uncertainty.
Cost, ROI, and FinOps for Data Platforms
TL;DR:
- Data platform costs are the #1 CFO concern in data architecture decisions—and no competitor provides actual benchmarks.
- The DBaaS market reached $20.8B in 2026 (Business Research Insights), reflecting the shift from CapEx to OpEx data spending.
- A claimed 60–80% first-year ROI from modernization exists in the literature but lacks sourcing.
- FinOps maturity for data teams is the capability gap most organizations underestimate.
The cost conversation around modern data architecture has shifted from "what will this cost to build?" to "what is this costing us to run?" The two questions have very different answers. Cloud data platforms that were cheap at 10 terabytes become expensive at 10 petabytes if query patterns, data retention policies, and compute allocation weren't designed with cost in mind from the start.
The DBaaS market, which reached $20.8 billion in 2026 (Business Research Insights), reflects the migration from on-premises capital expenditure to cloud operational expenditure, which can yield real savings in some cases and a budget disaster in others. The difference is FinOps maturity.
Cost benchmarks by architecture type
The table above deliberately avoids specific dollar figures per terabyte because those numbers are vendor-negotiated, region-dependent, and change frequently. What the table does show is the FinOps maturity requirement—and that column correlates directly with whether organizations realize the cost savings that modernization promises.
Audit task: Calculate your cost-per-insight baseline before any modernization project. The formula: total annual data platform spends (compute + storage + licensing + engineering time) divided by the number of distinct business decisions your data influenced in the last 12 months. Organizations with healthy FinOps practices typically target below $500 per influenced decision. If you don't track decisions influenced by data, that's the first gap to close.

Data Governance in the AI Era
TL;DR:
- Only 20% of data leaders are highly confident in their analysis capability despite significant investment (Ventana Research)
- 2/3 of enterprises are investing in data observability by 2026 (ISG/Ventana) - governance is moving from policy to automation
- The EU AI Act, active in 2026, requires auditability of AI decision inputs - which is an architecture requirement, not a compliance checkbox
- BCG identified 6 distinct GenAI governance use cases that require different architectural responses
Governance in data architecture has traditionally meant policies, access controls, and a data catalog that nobody updates. That model is collapsing under the weight of two simultaneous pressures: AI-generated data at scale (which requires automated classification because humans can't keep up) and regulatory requirements (which require machine-readable lineage because manual documentation doesn't survive audits).
The EU AI Act, which began enforcement cycles in 2026, requires organizations to demonstrate that data used to train or prompt AI systems is documented, auditable, and free of prohibited biases. That's not a policy question—it's an infrastructure question. You cannot satisfy an AI Act audit with a spreadsheet of data sources. You need an automated lineage that traces every data point from ingestion to AI output.
BCG identified 6 GenAI governance use cases with distinct architectural requirements: bias detection in training data, hallucination monitoring in outputs, regulatory compliance documentation, data access control for model inputs, quality monitoring for retrieval pipelines, and version control for dataset snapshots used in fine-tuning. Each of these requires a different technical capability.
Governance capability by architecture pattern
The fabric column is strong across governance dimensions for a reason: active metadata is the mechanism that automates governance rather than making it manual.
Industry-Specific Architecture Decisions
TL;DR:
- A financial services architecture looks nothing like a healthcare one, but every competitor treats modernization as a universal prescription.
- Compliance requirements, latency demands, and data type profiles vary enough by vertical that stack selection should be industry-conditioned.
- Manufacturing and retail face the most immediate AI agent demands due to IoT and real-time personalization workloads.
Every piece of content currently ranking for modern data architecture treats the topic as though every enterprise has the same requirements. That's not analysis, it's avoidance. A healthcare system processing medical imaging under HIPAA and FHIR interoperability requirements needs a fundamentally different architecture than a retail chain running real-time inventory and personalization at 2,700 stores.
Industry-specific architecture requirements matrix
Financial services firms face the sharpest version of the governance-performance tension. A trading system needs sub-second data access; a regulatory reporting system needs an immutable audit trail for every data transformation. Both requirements live on the same platform. The lakehouse + fabric combination handles this better than any single-pattern alternative because the fabric layer enforces policy without adding query latency to the compute path.
Healthcare's defining architectural challenge in 2026 is unstructured clinical data. Radiology images, clinical notes, and genomic sequences cannot be stored and queried with the same patterns as transaction records. The organizations making progress here are using lakehouse storage with vector indexing extensions—storing raw unstructured data in object storage, extracting embeddings, and querying via semantic search rather than SQL.
When Modernization Fails (And When to Wait)
TL;DR:
- 60% of data infrastructure projects exceed their initial budget by at least 30% (Gartner).
- Over-engineering is a real failure mode - organizations sometimes build for problems they don't yet have.
- Legacy systems are sometimes sufficient: if your workload is stable, predictable, and not AI-driven, modernization may have negative ROI.
- "Modern data stack fatigue" is a documented pattern (IBM 2026) as organizations consolidate away from tool sprawl.
Over-engineering occurs when organizations implement a data mesh across five data domains when a well-governed centralized lakehouse would have served them adequately for three more years at a fraction of the cost. Mesh architecture carries genuine organizational overhead—it requires domain teams who understand data product ownership, platform teams who can build and maintain self-serve infrastructure, and a federated governance model that takes years to mature. Deploying it prematurely creates a process without benefit.Over-engineering happens when organizations implement data mesh for five data domains when a well-governed centralized lakehouse would have served them adequately for three more years at a fraction of the cost. To avoid these pitfalls, many enterprises leverage modern data architecture services to right-size their stack and align technical patterns with actual organizational maturity. Mesh architecture carries genuine organizational overhead — it requires domain teams who understand data product ownership, platform teams who can build and maintain self-serve infrastructure, and a federated governance model that takes years to mature. Deploying it prematurely creates a process without benefit.
Premature cloud migration creates a similar problem at the infrastructure level. Organizations that migrated from on-premises warehouses to cloud platforms without redesigning their query patterns or data retention policies often found their cloud spend was 2–4× their original on-premises costs, with equivalent performance. The platform changed; the thinking didn't.
Modern data stack fatigue—IBM's term for it in their 2026 analysis—is the consequence of assembling too many point solutions. Organizations that layered an ingestion tool, a transformation tool, a catalog tool, an orchestration tool, an observability tool, and a BI tool on top of a cloud warehouse created integration overhead that consumed more engineering time than the tools collectively saved.
IBM noted in 2026 that the market is "consolidating to a smaller number of data platforms" and the consolidation is being driven by organizations that tried the maximum-tool approach and found it unsustainable.
When to wait: conditions where modernization has negative near-term ROI
The paradox resolves when you separate "modern data architecture" from "the most complex data architecture." Modern doesn't mean maximum. The right architecture is the simplest one that satisfies your current and 18-month-forward requirements at an acceptable cost and with acceptable governance overhead.
Quick takeaway: The organizations that get the most from data architecture modernization in 2026 are not the ones that implemented the most patterns. They're the ones who chose the right architectural scale for their actual data volume, team size, and use-case portfolio—and have governed it rigorously from day one.
Your Modernization Roadmap
The architecture decision isn't made once. It's made incrementally, and the organizations that execute well typically follow a maturity sequence rather than attempting full-stack transformation simultaneously.
Data architecture maturity model: stages 1–4
Most enterprises sit at Stage 2 in 2026. The path to Stage 3 is where the greatest practical value lies over the next 18–24 months.
Architecture selection decision matrix
Modernization audit checklist
- Baseline your current data volume and growth rate—know whether you're in the 10s or 100s of petabytes before choosing a storage pattern.
- Inventory your table formats— what percentage of production tables are on open formats (Iceberg, Delta, Hudi) vs. proprietary?
- Assess your unstructured data estate—what percentage is catalogued, classified, and access-controlled?
- Calculate your cost-per-insight—total platform spends ÷ business decisions influenced by data in the last 12 months.
- Map your AI workload requirements— list every GenAI use case in your 18-month roadmap and its data access pattern.
- Audit your governance automation—how much of data lineage, quality monitoring, and access control is automated vs. manual?
- Count your active data tools—if you have more than 8 distinct tools in your data stack, consolidation may generate more value than new capabilities.
- Identify your data domains—list every business area that owns and produces data; this number determines whether mesh is appropriate.
- Check your observability coverage—what percentage of production pipelines have automated anomaly detection and alerting?
- Define your vendor portability position—are you locked into a single vendor's proprietary formats, and is that a risk you've deliberately accepted?

Red flags that indicate architecture problems
- Pipeline failures that require manual intervention more than once per week.
- Data quality issues discovered by business users rather than the data team.
- Engineering backlog growing faster than the team's capacity to clear it.
- Cloud data spend is growing faster than data usage or business value delivered.
- New data use cases taking more than 30 days to move from request to production.
- Governance documentation that exists in wikis rather than automated systems.
- No defined data product SLAs for any dataset.
Audit task: Score your architecture maturity on five dimensions: scalability (can it handle 10× current volume?), governance (what percentage is automated?), AI-readiness (can it serve a RAG pipeline today?), cost efficiency (do you know your cost per query?), and team autonomy (can domain teams self-serve without central engineering?). Any dimension below 2 on a 4-point scale is a priority investment for 2026.
2027–2028 Predictions
The honest framing for any prediction: some of these are high-confidence extrapolations from current data; others are directional bets on trends that are nascent in 2026.
High confidence: If current adoption rates continue, the data lakehouse will be the default architecture for net-new enterprise data infrastructure by 2028. The 22.9% CAGR is fast enough that competitive pressure from cloud vendors will make lakehouse capabilities table-stakes even in managed database offerings. Organizations that haven't migrated at least partially to open table formats by 2028 will face increasing friction when evaluating new compute engines.
High confidence: Agentic data management will transition from emerging to mainstream between 2026 and 2028. Gartner's 40% figure for AI agent embedding in enterprise applications by the end of 2026 will likely be followed by a second wave of data-specific agents—autonomous quality monitors, lineage tracers, and cost optimization agents—that remove routine data engineering tasks from human queues entirely. The architectural implication is that data platforms need to be writable by agents, not just readable, and that there be corresponding governance controls on what agents can modify.
Directional: Open-table format consolidation favors Iceberg and Delta Lake. The Apache Paimon format may carve out a streaming-native niche, but the broad engine compatibility of Iceberg and the Databricks ecosystem dominance of Delta Lake make those the two formats worth betting on for long-term portability.
Directional: Semantic layers will become the default infrastructure. The ability to define business metrics once and apply them consistently across any BI tool, AI query, or data product is a governance and consistency problem that semantic layer tools (dbt Semantic Layer, AtScale, Cube) solve in ways that lakehouse storage alone cannot. By 2028, organizations without a semantic layer will face the same inconsistent metric problem that drove the original data warehouse consolidation efforts of the 2000s.
Speculative: Natural language data access will reach 60% adoption in enterprise analytics by 2026, according to a Gartner projection cited in this space. If accurate, that means most business users will interact with data through conversational interfaces by the end of this year—which makes data quality, cataloguing, and access control even more important than in the SQL-first world, because users won't see the query being run on their behalf.
Those who build on open standards, govern with automation, and architect for AI-native workloads will have a compounding advantage in 2028 and beyond. Those who defer those decisions will find the migration costs growing each year they wait.
Conclusions
TL;DR:
- The data architecture modernization market is growing at 10.7% CAGR to $24.4B by 2033—investment at scale is locked in.
- 67% of enterprises have deployed GenAI, but only 20% are confident in the underlying data capability.
- The winning pattern in 2026 combines lakehouse storage, fabric metadata, and mesh ownership—not a single architecture.
- Open table formats (Iceberg, Delta Lake, Hudi) are the infrastructure decision that determines future portability.
- 60% of modernization projects exceed budget—governance, cost discipline, and organizational readiness matter as much as technology.
The core finding of this report is not that any single architecture has won. It's that the organizations succeeding in 2026 have stopped treating architecture as a technology-selection problem and started treating it as a capability-portfolio problem. Which patterns provide AI-readiness? Which provides cost control? Which provides governance automation? The answers don't all point to the same vendor or the same framework.
The choice in 2026 is no longer between architectures—it's whether your organization can govern, cost-control, and AI-enable whatever you build. Enterprises that invest in observability, open table formats, and automated governance alongside their lakehouse or mesh implementations consistently outperform those that focus solely on platform selection.
Two things are likely true simultaneously in 2026: the opportunity in modern data architecture has never been larger, and the failure rate has never been more documented. The 60% budget overrun figure from Gartner isn't an argument against modernization. It's an argument for doing it with realistic timelines, staged implementation, and active cost governance rather than big-bang transformation projects.
The organizations that build AI-ready data infrastructure for AI-native workloads in 2026 won't be doing it again in 2028.
FAQ
What is modern data architecture, and why does it matter in 2026?
Modern data architecture refers to a set of design patterns and infrastructure choices that allow organizations to store, process, govern, and serve data at scale—particularly for AI and analytics workloads. In 2026, it matters because 67% of enterprises have deployed generative AI (Researchscape/Cloudera), but only 20% are confident in their underlying data infrastructure (Ventana Research). The architecture directly determines what AI capabilities are possible and how reliably they operate.
What's the difference between data lakehouse, data mesh, and data fabric?
A data lakehouse is a storage and compute architecture that applies warehouse-like query capabilities to data stored in open formats on object storage. A data mesh is an organizational and ownership model that distributes data ownership to domain teams and treats datasets as products. A data fabric is a metadata and integration layer that connects disparate systems using active metadata and AI-assisted pipelines. In 2026, leading enterprise implementations combine all three rather than choosing between them.
How much does modern data architecture modernization cost?
Costs vary significantly by organization size, existing infrastructure, and scope of modernization. The DBaaS market reached $20.8 billion in 2026 (Business Research Insights), reflecting widespread adoption of managed cloud data services. For internal planning purposes, the key cost variables are: compute (consumption-based in cloud deployments), storage (cheaper than compute for lakehouse patterns), engineering time (often the largest cost), and licensing. Gartner reports that 60% of data infrastructure projects exceed initial budgets by at least 30%—scope and phasing discipline are the primary cost control levers.
What is the ROI of data architecture modernization?
ROI varies depending on what's being replaced and the new capabilities modernization enables. More reliable signals include: reduced engineering time spent on pipeline maintenance, increased data-driven decisions per quarter, and shorter time-to-insight for new use cases. Organizations that modernize a specific high-cost bottleneck—a legacy on-premises warehouse or an aging ETL system—typically achieve faster payback than those undertaking broad-platform migrations.
How do you choose between cloud providers for data architecture?
The choice between AWS, Azure, and GCP for data architecture depends on your existing cloud investment, your preferred table format (Snowflake, which is cross-cloud, favors Iceberg; Databricks, which runs on all three, favors Delta Lake), and your AI services requirements. The research finding that 78% of enterprises manage data across 10 or more platforms (Market Reports World, 2026) suggests that multi-cloud is already the operational reality for most large enterprises. The architecture question is usually how to make platforms interoperable rather than which single provider to consolidate on.
What skills does a team need to implement modern data architecture?
The BLS projects 28% growth in data architect demand through the decade, reflecting genuine scarcity. Core skills required for 2026 implementations include: distributed systems design, SQL and Python fluency, familiarity with at least one open table format (Iceberg or Delta Lake), cloud data platform operations, data governance and cataloguing, and increasingly, understanding of AI/ML data requirements (vector databases, embedding pipelines, RAG architecture). Organizations implementing data mesh also need product management skills within domain teams, which is a talent profile that doesn't naturally exist in traditional data engineering teams.
References
Market research and sizing data
- Business Research Insights - Data Architecture Modernization Market Report
- Precedence Research - Enterprise Data Management Market Size, 2025
- MarketResearch.com - Global Data Lakehouse Market Forecast 2024–2033
- Market Reports World - Data Architecture Modernization Market, 2026
- Market Reports World - Enterprise Data Management Platform Adoption Report, 2026
- Business Research Insights - Database-as-a-Service (DBaaS) Market Report, 2025
- Polestar/Grand View Research - Analytics Market Global Forecast 2026–2034
- Grand View Research - AI Training Dataset Market Size & Forecast, 2025
- Statista - Volume of Data Created Globally, 2028 Forecast
Industry surveys and practitioner research
- Researchscape/Cloudera - Enterprise AI Adoption Survey
- KPMG - Generative AI Value Creation Survey
- Ventana Research / ISG - Data and Analytics Benchmark Report, 2024–2025
- ISG / Ventana Research - Data Observability Investment Forecast, 2025
- AvePoint - AI & Information Management Report
- Gartner - AI Agent Adoption Forecast, 2025
- Gartner - Data Infrastructure Project Budget Overrun Analysis
- Gartner - Natural Language Data Access Forecast, 2025
- BCG - GenAI Data Governance Use Cases Framework
- KPMG - GenAI Survey: Productivity and Customer Data Value Expectations
Case studies and expert analysis
- Dataversity - Data Architecture Trends in 2025: Kroger / 84.51° Case Study
- Dataversity - Nate Sylvester (84.51°) on Data Mesh and Fabric Implementation
- Acceldata - PhonePe Data Observability Case Study
- IBM - Modern Data Architecture: Workload Portability and Market Consolidation, 2026
- Rehan Jalil (Securiti.ai) - Unstructured Data Governance at Scale
- Donna Burbank (Global Data Strategy) - Governance Automation in Modern Architecture
- Kaycee Lai (Promethium) - How Data Fabric Enables Data Mesh Viability
- Matt Aslett (ISG) - Data Observability as Enterprise Standard, 2025
- McKinsey - Data Ubiquity Framework
Architecture standards, vendor documentation, and open-source foundations
- Apache Iceberg - Format Specification and Engine Compatibility Documentation
- Linux Foundation / Delta Lake - Delta Lake Format Documentation
- Apache Hudi - Incremental Processing Format Specification
- Apache Paimon - Streaming-Native Table Format Documentation
- Apache Software Foundation - Open Table Format Governance Overview
- DAMA International - Data Management Body of Knowledge (DMBOK2)
- Cloud Native Computing Foundation - Data Architecture Reference Patterns
- U.S. Bureau of Labor Statistics - Data Architect Occupational Outlook
- EU AI Act - Official Text and Compliance Requirements
- Databricks - Delta Lake and Lakehouse Architecture Documentation, 2025
- Snowflake - Apache Iceberg Integration Documentation, 2025


.webp)







