

Most organizations are not failing at data because they spend too little. They are failing because they spend without a strategy.
BCG’s 2025 AI at Work survey found that while enterprise AI momentum continues to build, only about half of frontline employees regularly use AI tools. That gap—between money spent and outcomes achieved—is the problem an enterprise data strategy exists to solve.
The pattern is consistent across industries: a data warehouse gets built, a governance committee gets formed, a few dashboards go live, and leadership declares the organization data-driven. Then the next initiative stalls because no one owns the data, the quality is unreliable, and the analytics team is buried in one-off requests instead of generating insight. The investment was real. The strategy was not.
An enterprise data strategy links your data infrastructure directly to your business objectives. It defines what data you collect, who owns it, how it flows across the organization, and how it generates measurable value. Without a structured approach to data platform development, even well-funded data programs drift toward technical complexity without business impact.
The framework below covers governance, architecture trade-offs, a phased implementation roadmap, and the business case your leadership team needs to see.

Key Takeaways
- While more than three-quarters of leaders and managers say they use generative AI (GenAI) several times a week, regular use among frontline employees has stalled at 51%.
- Poor data quality has become a measurable business risk. IBM reported in 2026 that over a quarter of organizations estimate losing more than $5 million annually due to data quality issues.
- 77% of companies lack the data talent needed to execute their strategy—the gap shows up during implementation, not planning (McKinsey, 2025).
- Governance-first strategies routinely stall: the organizations that succeed start with business outcomes and build governance to serve them, not the other way around.
- AI is scaling faster than organizational readiness. McKinsey found that almost all companies are investing in AI, yet only 1% call themselves mature. In 2026, Microsoft reported that AI agents are scaling faster than some companies can keep up with, posing governance and cross-team alignment risks.
What Is an Enterprise Data Strategy?
An enterprise data strategy is an organization-wide plan that defines how a company collects, manages, governs, and uses data to achieve its business objectives. It is not a technology roadmap or a data warehouse project—it is a business strategy that treats data as a first-class asset, assigns clear accountability, and builds the capabilities needed to turn raw information into decisions. A well-formed strategy spans people, processes, and platforms.
Definition and scope
Scope matters here. An enterprise data strategy covers every domain where data creates or destroys value: customer analytics, operational reporting, regulatory compliance, AI readiness, and product development.
Data strategy vs. data governance: where one ends and the other begins
Data governance is a component of data strategy, not a synonym for it. Strategy sets the direction—what data the organization will prioritize, how it will be used, and what outcomes it must produce. Governance sets the rules—who owns which data, how quality is enforced, and how access is controlled. You need both, but confusing them is one of the most common reasons initiatives stall.
AI adoption is broad, but workflow redesign is where the value starts to compound
More than three-quarters of leaders and managers say they use generative AI several times a week, yet regular use among frontline employees has stalled at 51%.
That gap matters now. Companies are learning that adding AI tools to old workflows is not enough to capture the full value of AI. The bigger gains come when businesses redesign workflows end-to-end and rethink how work gets done.
Half of companies, especially in financial services and technology, are moving beyond simple productivity use cases, which BCG calls Deploy, and into workflow redesign, or Reshape.
These findings come from BCG’s annual AI at Work global survey of employees. This year’s survey covers 11 countries and regions and includes more than 10,600 leaders, managers, and frontline white-collar employees. The full results are presented in the accompanying slideshow.

Why Most Data Strategies Fail Despite Heavy Investment
A 2025 report from the IBM Institute for Business Value found that 43% of chief operations officers rank data quality as their top data priority. The concern is grounded in cost: more than a quarter of organizations estimate annual losses above $5 million due to poor data quality, and 7% report losses exceeding $25 million.
The governance-first fallacy
The standard advice is to start with governance. Define your data ownership, establish policies, and build a data catalog. That advice is not wrong—but when governance becomes the strategy rather than a component of it, the result is compliance theater. Teams spend months documenting data lineage for assets on which no business decision depends. Policies get written; behavior does not change.
Talent gaps that derail execution
Strategy documents do not execute themselves. McKinsey reports that 77% of companies lack the necessary data talent and skill sets (Enterprise Data Strategy Framework, 2025). That gap shows up at every layer—from data engineers who can build reliable pipelines to translators who can connect analytical output to business decisions. Most organizations underestimate this problem during planning and discover it during implementation, when timelines slip and use cases stall.
Technology readiness vs. organizational alignment
AI is scaling faster than organizational readiness. McKinsey found that almost all companies are investing in AI, yet only 1% call themselves mature. In 2026, Microsoft reported that AI agents are scaling faster than some companies can keep up with, posing governance and cross-team alignment risks. A modern data lakehouse or AI-ready data platform delivers nothing if the business units feeding it still operate in siloed spreadsheets. Technology readiness and organizational alignment must advance together. Investing in one without the other produces a platform that goes unused.
The Business Case: What a Data Strategy Actually Returns
A data strategy converts raw data from a cost center into a revenue driver. Without one, organizations make slower decisions, lose customers to faster competitors, and incur preventable financial losses due to poor data quality. The financial gap between data leaders and laggards is measurable and growing.
ROI figures from named research
The evidence for investing in a formal enterprise data strategy is not anecdotal. Multiple primary research sources have quantified the return, and the numbers are consistent: organizations that treat data as a strategic asset outperform those that treat it as an IT concern.
The cost of inaction: revenue lost to bad data
Poor data quality has become a measurable business risk. IBM reported in 2026 that over a quarter of organizations estimate losing more than $5 million annually due to data quality issues.
The cost compounds over time. Every quarter without a data quality program is a quarter of avoidable loss.
From investment to outcome: what separates leaders from laggards
The pattern across research is consistent: data leaders do not simply spend more. They align data investment with specific business outcomes—customer acquisition, churn reduction, operational efficiency—and govern data quality as a precondition for analytics, not an afterthought. Businesses that are leaders in personalization achieve compound annual growth rates 10% higher than those of laggards and higher shareholder returns.
Your business case should not be built around infrastructure spend. Build it around the revenue you are currently losing and the customer outcomes you can accelerate.
Core Components of an Enterprise Data Strategy
An enterprise data strategy has five core components: data governance, data quality, data architecture, data literacy, and AI and analytics enablement. Each addresses a distinct failure mode. Miss one, and the others degrade. Governance without quality produces compliant but unreliable data. Architecture without literacy produces a platform nobody uses.
The Data Strategy Component Framework maps these five components to specific owners, deliverables, and accountability structures. Use the table below as a diagnostic: if any row lacks a named owner inside your organization, that component is at risk.
Data governance: policy, ownership, and accountability
Governance is the operating model for data ownership, not a compliance exercise. A CDO without a governance charter is managing by persuasion. Effective governance assigns a named data product owner to every critical domain (customer, product, finance) and gives data stewards the authority to enforce standards, not just document them.
Data quality: measurement and remediation
Quality problems compound silently. A single duplicate customer record corrupts downstream analytics, skews model training, and inflates marketing spend. The remediation cycle—profile, score, fix, monitor—must be continuous, not a one-time cleanse before a platform migration.
Data architecture: the structural backbone
Architecture decisions made here constrain every downstream capability. Whether you choose a centralized data warehouse, a decentralized data mesh, or a federated lakehouse, the choice must match your organizational structure, not just your technical preferences. Section 5 covers this trade-off in detail.
Data literacy and culture
Literacy is a cultural shift, not a training program. It requires executives to visibly model data-driven decision-making.
AI and analytics enablement
AI readiness depends on the four components above being functional first. Teams that deploy machine learning on ungoverned, low-quality data produce models that erode trust rather than build it.
The role structure below maps accountability across the full component stack:
The analytics translator role is consistently underinvested. In practice, the gap between what a data scientist builds and what a business leader uses is almost always a communication failure.
Choosing Your Data Architecture: Centralized, Decentralized, or Federated
The architecture choice you make early in your enterprise data strategy will constrain—or enable—nearly every capability you build afterward. A poor architecture choice means years spent working around structural constraints rather than building on them — which is why many enterprises turn to specialized data architecture service providers during strategic planning and platform modernization initiatives.
Centralized (data warehouse/lakehouse)
A centralized model consolidates data on a single platform—typically a cloud data warehouse or lakehouse—governed and operated by a central data team. It works well when governance maturity is low, and the organization needs consistent definitions across business units. The trade-off is a bottleneck: every data request passes through a single team, slowing delivery as the organization scales.
Decentralized (domain-owned data)
Decentralized architecture pushes data ownership to individual business domains—marketing owns its data, finance owns its data, and so on. Teams move faster because they control their own pipelines and schemas. The risk is fragmentation: without shared standards, the same metric can mean different things across domains, making cross-domain analysis painful.
Federated/data mesh
The federated model—often called a data mesh—combines domain ownership with centrally enforced standards. Each domain produces and maintains its own data products, but a shared governance layer defines interoperability rules, security policies, and quality contracts. This is the most complex model to implement, but it scales well for large, multi-domain enterprises that need both autonomy and consistency.
Decision criteria: which model fits your organization
Use the Data Architecture Decision Framework below to match your organizational profile to the right model.
Before committing to a model, work through these four decision criteria:
- Organization size and domain count—fewer than three distinct domains rarely justify the overhead of a federated model.
- Current governance maturity—decentralized and federated models require existing governance discipline; without it, they amplify inconsistency rather than reduce it.
- Degree of domain autonomy required—if business units have fundamentally different data needs and release cadences, centralized control creates friction that compounds over time.
- Existing technology stack—your current platforms shape what is feasible; migrating to a lakehouse architecture while simultaneously adopting data mesh governance is a high-risk combination.
No model is universally superior. Centralized suits organizations that need consistent governance quickly. Federated suits large enterprises that need domain autonomy at scale. Most organizations land somewhere between the two.
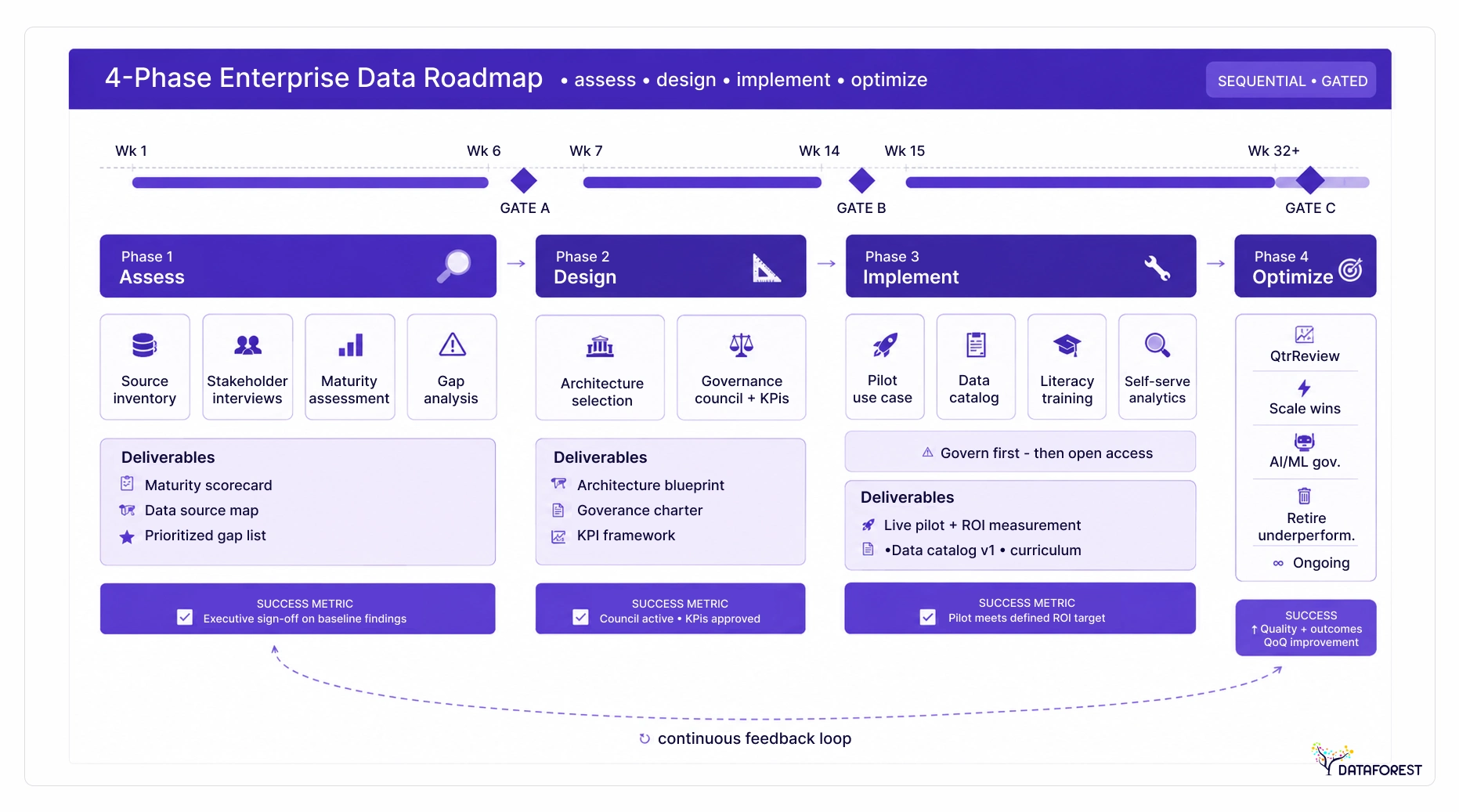
How to Build an Enterprise Data Strategy: A 4-Phase Roadmap
The four sequential phases are: Assess (baseline data maturity and gaps), Design (architecture, governance model, and KPIs), Implement (sequenced priorities from a pilot use case), and Optimize (measure outcomes and scale what works). Each phase has defined deliverables that gate entry to the next.
Phase 1—Assess: baseline your data maturity
Most organizations skip the assessment phase and pay for it later. Before designing anything, you need an honest inventory of which data sources exist, who owns them, what quality problems are endemic, and where the business feels the most pain. A structured maturity assessment surfaces these gaps in a form executives can act on—not a technical audit, but a business-aligned diagnostic.
Phase 2—Design: define architecture, governance, and KPIs
In the design phase, you select your architectural model (centralized, decentralized, or federated), establish the governance council and stewardship model, and define the KPIs that will indicate whether the strategy is working. The design phase produces the documents that align technical teams and business stakeholders before a single tool is purchased.
Phase 3—Implement: execute with sequenced priorities
Implementation fails when organizations underestimate the complexity of legacy modernization. Large-scale platform transitions frequently depend on specialized data migration services to preserve lineage, maintain governance controls, and minimize downtime during phased cutovers. Start with one high-visibility pilot use case that has a measurable ROI target and executive visibility. Build the data catalog, establish data quality thresholds, and launch self-service analytics for a defined user group. Sequence matters: governance infrastructure must precede broad data access, or you create new compliance exposure.
Phase 4—Optimize: measure, iterate, and scale
Teams that sustain data strategy momentum run quarterly reviews against their defined KPIs, retire underperforming use cases, and expand successful patterns to adjacent domains. This phase also integrates AI/ML governance controls as the organization's analytical ambitions grow.
Enterprise Data Strategy Implementation Checklist
Use this checklist to track progress across all four phases.
- Conduct a data maturity assessment
- Identify executive sponsor (CDO or CIO)
- Map current data sources and owners
- Define business-aligned data objectives
- Select architecture model (centralized/decentralized/federated)
- Establish a data governance council
- Assign data stewards per domain
- Define data quality standards and thresholds
- Build data catalog and lineage documentation
- Establish a data literacy training program
- Define KPIs for data strategy success
- Implement self-service analytics capability
- Integrate AI/ML governance controls
- Set data retention and compliance policies
- Launch pilot use case with a measurable ROI target
- Schedule quarterly strategy review cadence
Building the Team: Data Talent, Roles, and Organizational Capability
Most data strategies stall not because the architecture is wrong, but because the people executing it lack the right skills or authority. Technology alone cannot close that gap.
Core roles in a data-driven organization
A functioning data organization needs more than data scientists. The roles below represent the minimum viable team for an enterprise-scale program:
The CDO role is the linchpin. Without executive-level ownership, data governance decisions get escalated indefinitely, and data quality remediation stalls.
Closing the talent gap: build, buy, or partner
The talent shortage in data is real and documented. When you cannot hire fast enough—which is most of the time—you have three practical paths:
- Build: Upskill existing analysts and engineers through structured learning programs. This works well for data literacy and governance roles, but is slow for advanced ML capability.
- Buy: Hire experienced data engineers and scientists externally. Effective for quickly filling specific technical gaps, but expensive and competitive.
- Partner: Engage a data strategy consulting firm [internal link: Data governance frameworks guide] for architecture design, governance setup, or AI readiness assessments. This works when you need speed and a defined deliverable, but less so for ongoing operational capability.
In practice, most enterprises use all three in parallel—partnering for strategy, hiring for core engineering, and building literacy across the business.
Data Culture Maturity Model: from reactive to self-service
Organizational capability is not binary. The Data Culture Maturity Model maps where teams typically sit and what it takes to advance:
Most enterprises sit at Level 2 or 3. Reaching Level 4 requires not just tooling but a deliberate shift in how data ownership is assigned—domain teams must accept accountability for data quality, not just consumption.
Integrating AI and Generative AI into Your Data Strategy
Most AI initiatives stall not because the models are wrong, but because the data feeding them is ungoverned, incomplete, or untraceable. Generative AI raises the stakes further—a large language model trained on poorly documented enterprise data can produce outputs that are confidently wrong, legally exposed, or impossible to audit.
Why AI readiness starts with data, not models
AI readiness depends on data infrastructure—lineage, governance, and quality controls—before it depends on model selection. Teams that have successfully deployed generative AI treat data lineage, training data governance, and bias controls as strategic requirements from day one, not compliance additions after deployment. Without that foundation, model outputs inherit every flaw in the underlying data.
Data lineage and training data governance
Data lineage tracks where data originates, how it transforms, and where it flows—a requirement for any model you intend to audit or retrain. Training data governance extends this to define which datasets are approved for model training, who is authorized to use them, and under what conditions they can be updated. Organizations without a formal training data governance policy routinely discover, after deployment, that their models were trained on data containing PII, stale records, or undocumented business logic.
Bias controls and model accountability
Bias enters AI systems through skewed training data, proxy variables, and underrepresented populations. Controlling for it requires defined detection methods, documented thresholds, and a named owner responsible for remediation. Model explainability requirements—specifying how a model must justify its outputs—should be documented before deployment, not after a compliance incident.
AI-Ready Data Strategy Checklist
Use this checklist to assess whether your data strategy can support AI and generative AI at scale:
- Data lineage is documented end-to-end
- Training data governance policy in place
- Bias detection and monitoring controls are defined
- Model explainability requirements documented
- Data quality thresholds set for AI inputs
- AI output audit trail established
Root causes of data strategy failure (a consolidated reference for teams diagnosing why prior AI or data initiatives underdelivered):
- Governance without business linkage
- Talent and skill gaps
- Technology-organization misalignment
- No executive sponsorship
- Undefined data ownership
- Shadow data pipelines built outside the governed environment

Measuring Data Strategy Success: KPIs and Maturity Benchmarks
Six operational KPIs indicate whether a data strategy is working: data quality score, data literacy rate, time-to-insight, self-service adoption rate, data incident rate, and AI model accuracy. Benchmark these against the Gartner Analytic Ascendancy Model to locate your organization's analytical maturity.
Six KPIs every data strategy should track
Most organizations track technology metrics—pipeline uptime, storage costs, query performance - and miss the business-facing signals that actually indicate whether the strategy is working. While pipeline uptime is a necessary metric, implementing comprehensive data pipeline monitoring and observability provides the deeper insights needed to connect infrastructure health to actual data quality, thereby closing the gap to business-facing signals. The six KPIs below close that gap.
Using the Gartner Analytic Ascendancy Model to benchmark maturity
The Gartner Analytic Ascendancy Model maps analytical maturity across four stages: Descriptive (what happened), Diagnostic (why it happened), Predictive (what will happen), and Prescriptive (what should we do). Most enterprises operate primarily at the Descriptive stage—dashboards and reports—while treating the upper stages as aspirational.
Use the model as a diagnostic tool, not a ranking tool. If your KPIs show strong data quality scores but Time-to-Insight remains slow, the bottleneck is usually Diagnostic capability: analysts spend time explaining data rather than modeling it. If the Self-Service Adoption Rate is low despite good tooling, the gap is literacy, not architecture. Each stage requires different investments, and skipping the Diagnostic to chase Predictive analytics typically produces models trained on poorly understood data.
When to escalate: signals your strategy needs a reset
KPIs trending in the wrong direction for two consecutive quarters is a signal, not a crisis. Three consecutive quarters of decline—or a single sharp drop in Data Quality Score or AI Model Accuracy—warrants a formal strategy review. Other escalation triggers include: business units building shadow data pipelines outside the governed environment; a CDO or data leadership vacancy lasting more than 90 days; or a regulatory finding tied to data lineage. These are organizational failures, not technical ones, and they require executive sponsorship to resolve.
Build Internally or Hire a Data Strategy Consulting Firm?
Organizations that hire a firm without internal readiness often get a polished strategy document that sits unused. Those who build internally without the right talent lose months to avoidable mistakes.
Five criteria for the build-vs-hire decision
What to expect from a consulting engagement
A credible consulting firm assesses your current-state maturity honestly, co-designs a roadmap with your internal stakeholders rather than for them, and transfers enough knowledge that your team can execute without a permanent retainer.
Red flags to screen for: firms that lead with a technology platform recommendation before completing a maturity assessment, engagements scoped entirely as deliverable documents rather than working sessions, and proposals that skip change management entirely.
The engagements that work are time-boxed—typically eight to sixteen weeks—and produce a prioritized roadmap, a governance operating model, and a capability-building plan your internal team owns from day one. Consulting accelerates decisions your organization already has the will to make. It cannot substitute for that will.
Enterprise Data Strategy Implementation Checklist
Use this checklist to confirm readiness before launch. Each item requires a named owner—not a team or department.
- Executive sponsor identified—a C-suite leader with budget authority has formally committed to the strategy
- CDO or equivalent appointed—a single accountable leader owns data strategy execution
- Current-state data maturity assessed—baseline documented across governance, quality, architecture, and literacy
- Business objectives mapped to data use cases—every priority use case traces to a measurable business outcome
- Data governance operating model defined—policies, ownership, and escalation paths documented and approved
- Architecture pattern selected—centralized, decentralized, or federated decision made with documented rationale
- KPIs and success metrics established—at least three leading indicators tracked from day one
- Talent plan confirmed—build, buy, and partner decisions made for each critical role
- AI readiness baseline completed—data lineage, quality thresholds, and bias controls in place before model deployment
- Roadmap phased and sequenced—90-day, 6-month, and 12-month milestones assigned to named owners
Frequently Asked Questions About Enterprise Data Strategy
What is an enterprise data strategy?
An enterprise data strategy is an organization-wide plan that defines how data is collected, managed, governed, and used to achieve business objectives. It covers people, processes, technology, and culture—not just infrastructure. A strong strategy treats data as a business asset with defined ownership, quality standards, and measurable outcomes tied to revenue, efficiency, or risk reduction.
What is the difference between data strategy and data governance?
Data strategy sets the direction—what data capabilities the organization needs and why. Data governance defines the rules that make those capabilities trustworthy: who owns data, how quality is enforced, and what policies apply. Governance is one component of strategy, not a synonym for it. Organizations that treat governance as the whole strategy typically stall before generating business value.
Why is a data strategy important for enterprises?
Without a strategy, data investments fragment across business units, producing redundant systems and inconsistent reporting. A unified strategy aligns data initiatives to business priorities, reduces the cost of poor data quality, and creates the foundation AI and analytics tools require to function reliably. Enterprises that skip this step often find themselves rebuilding from scratch after costly platform failures.
What are the steps to building an enterprise data strategy?
The four core phases are: assess your current data maturity and gaps; design your target architecture, governance model, and KPIs; implement with sequenced priorities starting from high-value use cases; then optimize by measuring outcomes and scaling what works. Each phase has defined deliverables - skipping the assessment phase is the most common reason implementations miss their targets.
What are the key components of an enterprise data strategy?
The five essential components are data governance, data quality, data architecture, data literacy and culture, and AI and analytics enablement. Each must be addressed together. A technically sound architecture with no governance produces unreliable outputs. Strong governance with no investment in literacy means analysts cannot act on the data they are given.
How do you measure the success of a data strategy?
Track six KPIs: data quality score, time-to-insight, self-service adoption rate, AI model accuracy, data literacy rate, and data incident rate. Benchmark against the Gartner Analytics Ascendancy Model to understand where your organization sits across descriptive, diagnostic, predictive, and prescriptive capability levels. The most common advice—start with governance—is also the most common reason data strategies stall. The organizations that succeed start with business outcomes and build governance to serve them.
Conclusion
The gap between investing in data and actually becoming data-driven is not a technology problem. It is a sequencing problem. Organizations that close that gap treat governance, architecture, and talent as interdependent decisions - not separate workstreams handed off to different teams and revisited annually.
As generative AI moves from pilot to production, weak data foundations become a direct blocker - not a background risk. Models are only as reliable as the data they are trained on, and enterprises without clean lineage, documented ownership, and bias controls will find AI initiatives stalling at the same point their analytics initiatives did a decade ago. The organizations that have deployed AI reliably built the data layer first - governed lineage, documented ownership, and bias controls in place before the first model went live.
Start with your current-state assessment this quarter. Map your data domains, identify ownership gaps, and score your maturity against the Gartner Analytic Ascendancy Model. That exercise will surface the structural problems blocking downstream initiatives and give you specific evidence to make the case to leadership.


.webp)







