

A fintech analytics team ingests 40 million order events per day from Kafka. Six months in, they have 180 TB of raw JSON files, and every analyst spends three hours each morning writing custom Python scripts to clean nulls and fix schema drift before any real work begins. The data exists. The insights don't.
This is the problem medallion architecture was designed to solve.
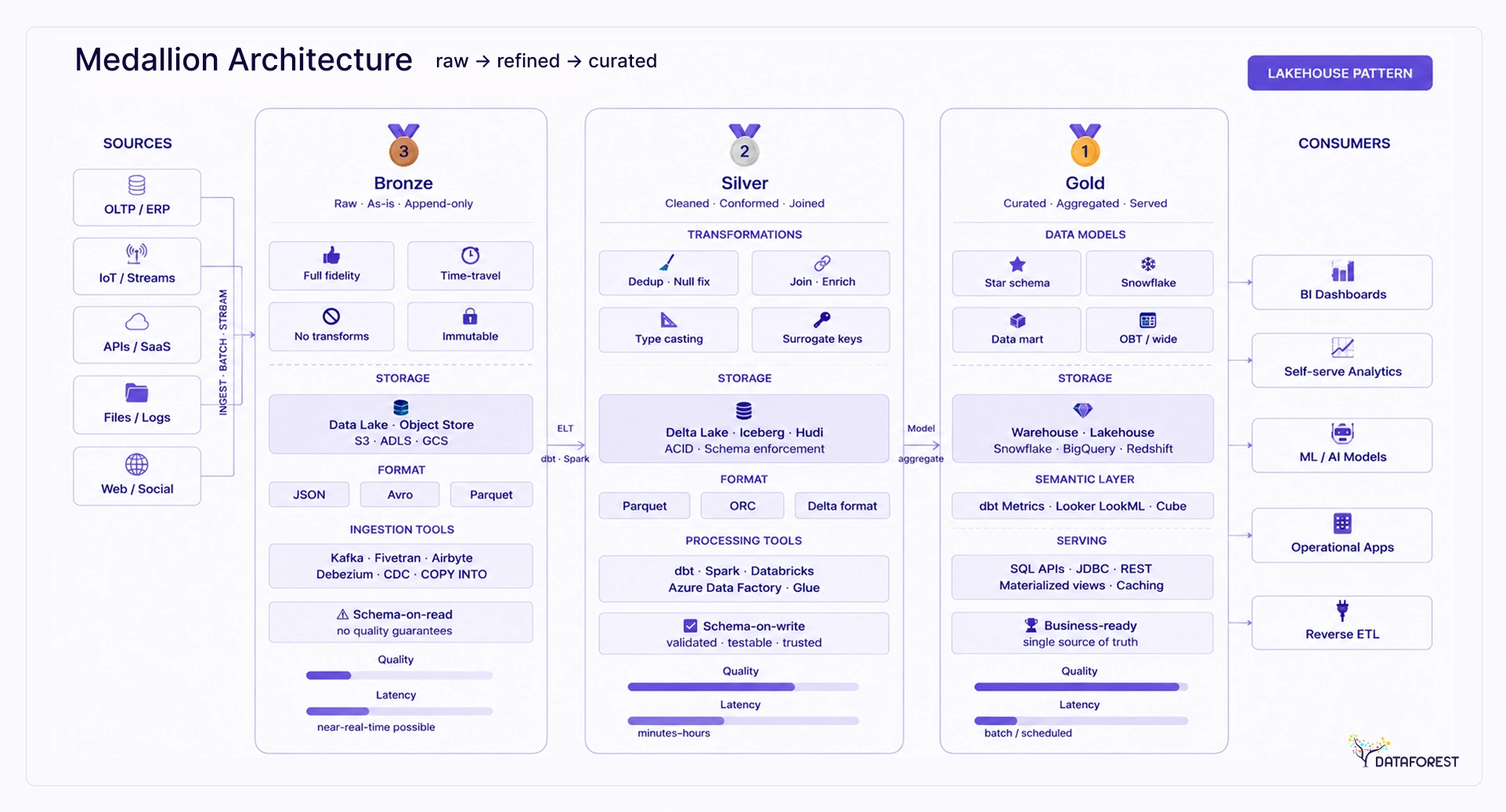
Medallion architecture organizes a data lakehouse into three progressive layers—bronze, silver, and gold—where each layer applies a higher standard of quality to the same underlying data. Raw events land in bronze exactly as they arrived. Silver cleans, conforms, and deduplicates them. Gold aggregates the results into tables built for specific consumers: BI dashboards, machine learning models, or executive reports.
The pattern is simple to describe and surprisingly hard to implement well. Most teams get the layer names right and the ownership model wrong. They treat medallion architecture as a storage convention when it is actually a team contract: a shared agreement about who is responsible for data quality at each stage, and what guarantees downstream consumers can rely on.
The sections below cover how each layer works, how to implement the pattern on Databricks, Snowflake, and Microsoft Fabric, and when a simpler approach is the better choice.
Key Takeaways
- Bronze is more than a staging area. It preserves raw data exactly as it arrives and can support auditing, provenance, lineage, and long-term compliance retention needs.
- Bronze should preserve raw events exactly as they arrive, so that Silver can handle validation and cleanup without analysts having to rebuild the same transforms from scratch.
- Medallion architecture and data mesh solve different problems and are composable—choosing one does not exclude the other
- For AI-heavy pipelines, Medallion architecture keeps raw data in Bronze, pushes validation and enrichment into Silver, and lets teams optimize storage and compute by layer, though the extra validation and transformation steps still need to be managed carefully.
- Most medallion failures happen before a single pipeline runs—skipping layer boundary design and ownership contracts causes layers to collapse into unmanaged zones
What Is Medallion Architecture?
Medallion architecture is a data design pattern that organizes lakehouse data into three progressive layers—Bronze, Silver, and Gold—each representing a higher level of quality, structure, and business readiness. Raw data lands in Bronze, gets cleaned and conformed in Silver, and reaches Gold as aggregated, analytics-ready output.
Progressive data refinement
The Bronze-Silver-Gold framework treats data quality as a pipeline property rather than an afterthought. Bronze holds raw, append-only records exactly as they arrive from source systems—no transformations, no filtering. Silver applies cleaning, deduplication, and schema conformance, producing a standardized dataset that multiple downstream teams can trust. Gold contains business-level aggregates, metrics, and feature sets built for specific consumption patterns: dashboards, machine learning models, or operational reports.
This staged refinement means a bug in a transformation never corrupts your source data. You can reprocess Silver from Bronze, or rebuild Gold from Silver, without touching the original records.
Why the lakehouse pattern needs a layered organization model
A lakehouse without structure quickly becomes a data swamp. Files accumulate, schemas drift, and teams independently duplicate transformation logic. Medallion architecture imposes a clear contract on what each storage zone contains, making governance, lineage tracking, and reuse tractable at scale making governance, lineage tracking, and reuse tractable at scale across a modern Data Platform with modern data architecture services. Databricks, Microsoft Fabric, and Azure all recommend it as the default organization pattern for their lakehouse implementations.
Medallion architecture as a team ownership contract
The layers map directly to team responsibilities. Data engineers own the Bronze-to-Silver pipeline: ingestion, deduplication, and schema enforcement. Analytics engineers own Silver-to-Gold: building the aggregations and dimensional models that business logic requires. Business analysts consume Gold directly, without needing to understand upstream complexity.
This boundary reduces cross-team friction. When a Gold metric looks wrong, the ownership model tells you exactly where to investigate—and who is accountable for the fix.
Data flow: Source systems -> Bronze (raw, append-only) -> Silver (cleaned, conformed) -> Gold (aggregated, consumer-ready) -> Consumption layer
The Three Layers: Bronze, Silver, and Gold
The bronze layer holds raw, unmodified source data exactly as it arrived. The silver layer cleans, conforms, and joins that data into a consistent, query-ready state. The gold layer aggregates silver data into business-specific tables—revenue summaries, patient cohorts, product performance views—built for a defined consumer audience rather than general-purpose querying.
Bronze layer: raw ingestion and the compliance case for keeping it
Bronze is more than a staging area. It preserves raw data exactly as it arrives and can support auditing, provenance, lineage, and long-term compliance retention needs. That requirement alone makes the bronze layer a compliance asset, not just a technical convenience.
Bronze tables are append-only by design. New records land without overwriting existing ones, preserving a full point-in-time history and enabling audit trails and reprocessing. When a transformation bug corrupts silver data, you replay from bronze rather than re-extracting from source systems.
The scale this layer must absorb is real. A fintech analytics team receives 40 million order events per day from Kafka. Six months later, they have 180 TB of raw JSON files—and every analyst spends three hours each morning writing custom Python scripts to clean nulls, correct currency mismatches, and deduplicate records before running a single query. That is the exact problem the silver layer exists to solve.
Silver layer: cleaned, conformed, and query-ready
Silver is where raw data becomes trustworthy. Data engineers apply a defined set of quality rules at this layer so that downstream consumers—analysts, data scientists, and BI tools—never have to write defensive cleaning logic themselves.
The silver layer enforces these quality rule categories on every pipeline run:
- Null checks: reject or quarantine records missing required fields
- Referential integrity: validate foreign keys against known dimension tables
- Range validation: flag values outside acceptable business bounds - negative prices, future birthdates, and similar outliers
- Deduplication: collapse duplicate events using deterministic keys or windowed logic
- Schema drift detection: alert or halt when upstream sources add, rename, or drop columns unexpectedly
Silver tables are typically stored in a columnar format (Parquet or Delta) and partitioned for efficient filtering. They represent a conformed, joined view of source data—not yet aggregated, but clean enough that any analyst can query them without preprocessing.
Gold layer: aggregated tables designed for specific consumers
Gold tables are purpose-built. Each one serves a specific team or use case: a finance dashboard, a machine learning feature store, a regulatory report. Unlike silver, which is general-purpose, gold is intentionally narrow—and that specificity is what makes it fast and reliable for production workloads.
Gold tables typically contain pre-joined, pre-aggregated data: daily revenue by region, weekly active users by cohort, claim denial rates by provider. Because the heavy computation occurs at build time rather than at query time, end users get sub-second responses for datasets that would otherwise require minutes of processing.
Streaming vs. batch ingestion and CDC in the bronze layer
The data flow through a medallion pipeline follows a consistent path regardless of ingestion mode: raw ingestion -> bronze -> silver -> gold -> consumption. What changes is the cadence and mechanism at the first step.
Batch ingestion pulls files or database snapshots on a schedule - hourly, nightly, or weekly. Streaming ingestion, via tools like Kafka or Kinesis, lands events in bronze within seconds of generation. Both approaches write append-only records to bronze; the difference is latency.
Change data capture (CDC) adds a third pattern. Rather than full snapshots, CDC emits row-level change events - inserts, updates, deletes - from source databases. These events land in bronze as append-only records, preserving the full change history. Silver transformations then apply merge logic to reconstruct each entity's current state.
Implementing Medallion Architecture: A Step-by-Step Checklist
Most medallion architecture failures occur before a single pipeline runs—teams skip the design decisions that determine whether layers stay clean or collapse into one another over time. The checklist below covers every decision point from storage setup through pipeline observability. Work through it in order; later steps depend on earlier ones.
12-step medallion architecture implementation checklist
- Define layer boundaries and storage locations
- Choose a table format (Delta Lake, Iceberg, or Parquet)
- Configure append-only writes for the bronze layer
- Enforce schema on read or write at the silver layer
- Design a partitioning strategy aligned to query patterns
- Implement incremental load using watermarks or CDC
- Define data quality rules per layer
- Apply row-level and column-level access controls
- Set retention policies for the bronze layer
- Build pipeline observability with row-count and freshness checks
- Document data lineage from source to gold
- Schedule and test full and incremental refresh cycles
Step 1-3: Layer design and storage setup
Start by mapping each layer to a distinct storage path or namespace—for example, separate containers in Azure Data Lake Storage, separate schemas in Snowflake, or separate lakehouses in Microsoft Fabric's OneLake. Mixing layers in a single namespace is the most common setup mistake and the hardest to undo later.
Table format choice (step 2) shapes everything downstream. Delta Lake is the default on Databricks and Fabric because it supports ACID transactions, time travel, and schema evolution out of the box. Apache Iceberg is a strong alternative when you need cross-engine compatibility. Plain Parquet works for read-heavy bronze archives but lacks the transaction log you need for reliable incremental loads.
For the bronze layer (step 3), configure append-only writes and never allow in-place updates. Raw data is your audit trail. Overwriting it removes the ability to reprocess history when a transformation bug surfaces months later.
Step 4-7: Schema enforcement, partitioning, and incremental load patterns
Schema enforcement at the silver layer (step 4) is where data quality becomes structural rather than aspirational. Schema-on-write catches malformed records at ingestion; schema-on-read gives more flexibility but pushes validation downstream. In practice, teams with strict SLA requirements enforce schema-on-write at silver and use schema-on-read only in exploratory bronze zones.
Partitioning strategy (step 5) must reflect how consumers query the data, not how sources produce it. Partitioning by ingestion date suits bronze. Silver and gold tables typically benefit from partitioning by business date, region, or entity type—whichever column appears most often in WHERE clauses.
Incremental load (step 6) is non-negotiable at scale. Use high-watermark timestamps when sources expose a reliable updated-at column. Use CDC when you need row-level change capture without full table scans. [internal link: Change data capture guide] Define quality rules per layer (step 7): bronze validates only that records arrived and are parseable; silver enforces null checks, referential integrity, and range constraints; gold validates aggregate consistency against known business thresholds.
Step 8-10: Data quality rules and access controls
Access controls (step 8) should be layer-aware. Bronze is typically restricted to pipeline service accounts and data engineers. Silver opens to data scientists and analysts with row-level security applied where PII is present. Gold is the widest-access layer—BI tools, dashboards, and external consumers read from it—so column-level masking of sensitive fields is essential.
Retention policies for the bronze layer (step 9) need to align with your regulatory environment before you write a single record. Many industries require raw data to be retained for extended periods, and retroactively applying retention rules to an existing bronze store is operationally painful. Set the policy at table creation.
Step 11-12: Monitoring, alerting, and pipeline observability
Pipeline observability (step 10, extended through steps 11-12) is the layer most teams defer until something breaks in production. Build row-count checks and freshness checks into every pipeline stage from day one. A silver table that stops updating silently is worse than a pipeline that fails loudly.
Data lineage documentation (step 11) from source to gold lets you answer two questions quickly: which downstream reports are affected when an upstream source changes, and which source records contributed to a specific gold aggregate. Tools like Unity Catalog on Databricks and Microsoft Purview on Fabric capture this automatically when configured correctly.
Finally, schedule and test both full and incremental refresh cycles (step 12) before going to production. Full refreshes expose schema drift and partition mismatches that incremental loads mask. Run both modes in a staging environment against a representative data volume, not just a sample.

Medallion Architecture on Databricks, Snowflake, and Microsoft Fabric
In Databricks, medallion architecture is implemented natively using Delta Lake as the table format across all three layers, with Auto Loader handling incremental ingestion from cloud storage into the Bronze layer and Unity Catalog enforcing governance across Silver and Gold. Databricks coined the pattern, and its official documentation remains the canonical reference for Delta Lake-based implementations.
Databricks: Delta Lake, Unity Catalog, and Auto Loader
Delta Lake gives every layer ACID transactions and time travel—meaning you can query the Bronze layer as it existed at any prior checkpoint, which is invaluable for debugging bad Silver transforms. Auto Loader uses file notifications or directory listings to process new files incrementally as they arrive, so your Bronze ingestion job doesn't rescan the entire storage bucket on every run. Unity Catalog sits above all three layers and provides fine-grained column-level access control, lineage tracking, and audit logs without requiring separate tooling. Teams that have deployed this stack typically wire Auto Loader into a Structured Streaming job, write raw records to a Delta Bronze table, then trigger downstream Silver and Gold jobs via Databricks Workflows.
Snowflake: Dynamic Tables, Streams, and the medallion pattern
Snowflake doesn't have a native lakehouse format in the same sense, but the medallion pattern maps cleanly onto its object model. Bronze tables hold raw, semi-structured data in VARIANT columns. Streams capture row-level change data on those tables, and Tasks schedule the transformation logic that promotes records to Silver. Dynamic Tables, introduced as a declarative alternative to pipeline code, let you define Silver and Gold as SQL queries and let Snowflake handle incremental refresh automatically. Governance is built into Snowflake's role-based access control and, for more granular needs, column-level masking policies. The main trade-off: Snowflake's compute model means running continuous streams costs more than batch-oriented pipelines, so teams with high-volume, low-latency requirements should size their warehouses carefully.
Microsoft Fabric: OneLake, Lakehouses, and the Fabric medallion approach
Microsoft Fabric's official guidance explicitly recommends medallion architecture as the default design pattern for OneLake. The recommended approach is to create three separate Lakehouses—one per layer—within a single Fabric workspace. OneLake shortcuts let downstream Gold consumers reference Silver data without copying it, which keeps storage costs flat as the pipeline scales. Microsoft Purview integrates directly for data cataloging and sensitivity labeling across all three Lakehouses. Fabric's Dataflow Gen2 handles low-code ingestion into Bronze, while Spark notebooks or Data Factory pipelines manage heavier transformation work in Silver.
Azure Data Lake Storage Gen2 as a platform-agnostic foundation
ADLS Gen2 underpins both Databricks and Fabric deployments and works as a standalone storage layer for teams not yet committed to either platform. You organize Bronze, Silver, and Gold as separate containers or folder hierarchies, apply Azure role-based access control at the container level, and mount the storage into whichever compute engine you use. This approach trades native features - no Auto Loader, no Dynamic Tables - for maximum portability.
Medallion Architecture vs. Data Mesh, Star Schema, and Data Vault
Medallion architecture and data mesh are not competing solutions to the same problem. Medallion defines how data moves through quality layers—Bronze, Silver, and Gold—within a single platform. Data mesh defines who owns data and how domains publish it across an organization. A team can run a data mesh in which each domain internally uses the medallion architecture to manage its own pipeline quality.
When medallion and data mesh solve different problems
Data mesh is an organizational pattern. It addresses the bottleneck that forms when a central data team owns every pipeline for every domain—a structure that breaks down past a certain organizational scale. Medallion architecture is a technical pattern. It addresses the problem of data arriving in inconsistent, raw states that require progressive refinement before reaching analysts or models.
The two patterns are composable. In a mature data mesh, each domain team owns a Bronze-to-Gold pipeline within its own lakehouse. The mesh governs how those Gold-layer outputs get shared as data products. Choosing one does not exclude the other.
Star schema: still the right choice for bounded analytical domains
Stop treating star schema as legacy. For a single analytical domain—say, sales reporting or inventory tracking—a well-designed star schema with fact and dimension tables delivers faster query performance and simpler governance than a full medallion pipeline. The trade-off is flexibility: star schemas are optimized for known query patterns and become brittle when source systems change frequently. Medallion architecture handles schema evolution better because raw data is preserved in Bronze.
Data vault: auditability-first design for enterprise warehouses
Data vault prioritizes historical accuracy and auditability above query simplicity. Its hub-satellite-link model records every change to every entity, making it the right choice for regulated industries where you must reconstruct the state of data at any point in time. The cost is real: data vault models are harder to query directly and typically require a presentation layer—which often ends up looking like a Gold layer anyway. Teams running data vault in a lakehouse sometimes adopt medallion conventions for that final presentation stage.
Medallion vs. lakehouse architecture: clarifying the overlap
Lakehouse architecture describes a storage-and-compute paradigm—open file formats, ACID transactions, and unified metadata—that supports both analytical and ML workloads. Medallion architecture is a data organization pattern that runs on top of a lakehouse. You can have a lakehouse without medallion layers, and you can implement medallion conventions on a traditional data warehouse. In practice, the two are almost always paired: the lakehouse provides the foundation, and medallion provides the organizational logic.
For AI-heavy pipelines, Medallion architecture keeps raw data in Bronze, pushes validation and enrichment into Silver, and lets teams optimize storage and compute by layer, though the extra validation and transformation steps still need to be managed carefully.
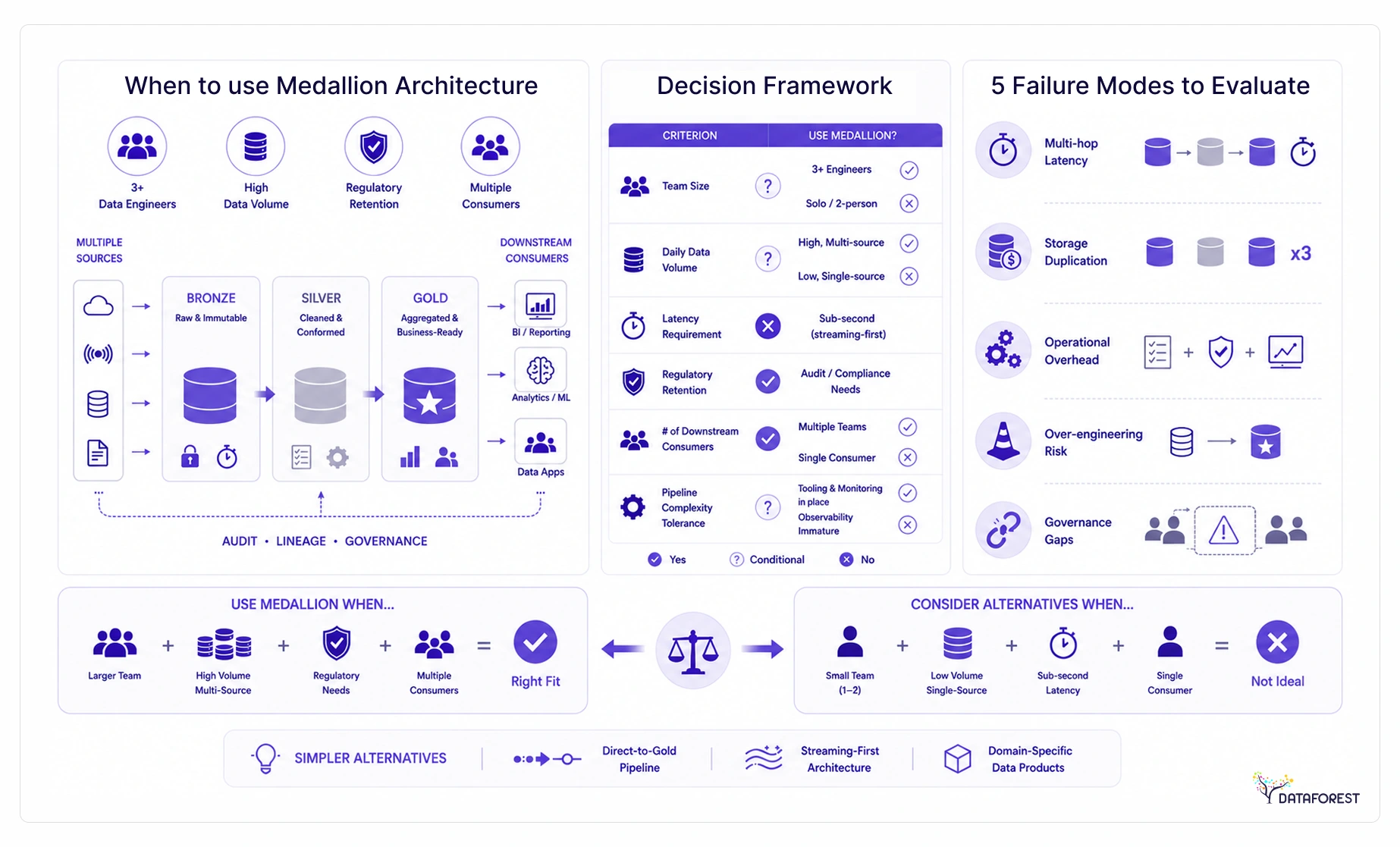
When to Use Medallion Architecture—and When Not To
Medallion architecture fits teams that ingest data from multiple sources, serve diverse downstream consumers, and need auditable data lineage across layers. If your team has at least three data engineers, processes high daily volumes, and operates under regulatory retention requirements, the pattern pays for itself. For smaller teams or single-domain pipelines, simpler alternatives often outperform it.
Decision framework: team size, data volume, and use case fit
Five failure modes to evaluate before you commit
Medallion architecture is widely recommended, but it carries real failure modes that teams discover after committing to the pattern:
- Multi-hop latency: each Bronze-to-Silver and Silver-to-Gold hop adds processing time, making sub-second delivery structurally difficult.
- Storage duplication: raw, cleaned, and aggregated copies of the same data multiply storage spend, particularly for high-volume event streams.
- Operational overhead: maintaining schema enforcement, quality checks, and monitoring across three layers requires sustained engineering capacity that most small teams lack.
- Over-engineering risk: a team running a single dashboard for a single business unit rarely needs three layers of transformation—a direct-to-gold model is simpler and faster to maintain.
- Governance gaps: without explicit ownership contracts between engineering and analytics teams, layers drift into unmanaged zones and quality guarantees collapse.
For AI-heavy pipelines, Medallion architecture keeps raw data in Bronze, pushes validation and enrichment into Silver, and lets teams optimize storage and compute by layer, though the extra validation and transformation steps still need to be managed carefully.
Alternatives to consider for small teams and simple pipelines
Three patterns are worth evaluating before defaulting to medallion:
- Direct-to-gold single-layer: load the cleaned data directly into a single serving layer. Works well for bounded domains with a single consumer and low ingestion complexity.
- Star schema: purpose-built for analytical queries against a stable, well-understood domain. Faster to implement and easier to query than a full medallion pipeline when the domain is fixed.
- Data vault: the right choice when auditability and historical tracking are the primary requirements, not query performance or ML feature serving.
Cost control levers by layer (apply these before deciding the pattern is too expensive):
- Set bronze retention windows aligned to regulatory minimums
- Use Z-ordering or clustering on silver tables to reduce scan costs
- Partition gold tables by the most common filter dimension
- Schedule silver and gold refreshes at the lowest frequency consumers require
The three layers of medallion architecture are not just a storage pattern—they are a contract between data engineers, analytics engineers, and the business. When that contract is honored, the architecture scales. When it is ignored, the layers collapse into a single unmanaged zone.

Real-World Use Cases: Medallion Architecture in Fintech, Healthcare, and Retail
The pattern looks clean on a diagram. Where it earns its keep is in production pipelines, where data arrives messy and at scale from sources that don't agree with each other.
Medallion architecture cuts latency and delivers real-time, trusted data at scale
In a 2025 serverless data pipeline implementation, adopting a Bronze–Silver–Gold architecture enabled raw event capture, structured transformation, and business aggregation, reducing ETL latency by up to 70% while supporting near real-time analytics on high-volume data streams.”
(International Journal of Scientific and Research Publications, 2025)
Raw healthcare data stays auditable while curated layers power clinical analytics
Healthcare data pipelines can use a Bronze-Silver-Gold pattern to retain raw EHR, claims, HL7, and FHIR data for audit and lineage, standardize and deduplicate records in Silver, and publish curated, de-identified analytics in Gold under strict access controls.
Unifying retail signals from POS, inventory, and clickstream into a single analytical pipeline
Retail data platforms commonly ingest inventory, transaction, and clickstream data from heterogeneous systems into a Bronze layer as raw events, then apply schema harmonization and entity conformance in a Silver layer, and finally generate Gold-layer datasets for demand forecasting and merchandising analytics, such as sell-through reporting and feature engineering for ML models.
Silver is where MDM turns scattered records into one trusted customer identity
Bronze preserves raw source-system identifiers, Silver is where records are validated, deduplicated, normalized, and merged into a golden record through MDM, and Gold then consumes that trusted identity for consistent reporting and analytics.
Cost Management and Ingestion Frequency in a Medallion Pipeline
The highest hidden cost in a medallion pipeline is not computing—it is storing data you never query and running pipelines more frequently than your consumers actually need.
Batch vs. streaming ingestion: cost and latency trade-offs
Streaming ingestion delivers low latency but carries higher compute costs: continuous Spark Structured Streaming jobs or managed Kafka connectors run around the clock regardless of data volume. Batch ingestion is cheaper per record but introduces lag—acceptable for daily reporting, problematic for fraud detection or real-time inventory. The right choice depends on the SLA of your gold-layer consumers, not the capabilities of your ingestion tool. Teams that default to streaming everywhere typically find that most of their gold-layer queries run on hourly or daily schedules, making the latency advantage irrelevant and the cost unjustifiable.
Controlling storage costs across three layers
Each layer has a different cost profile. Bronze holds raw, often verbose formats—JSON, XML, Avro—and grows fastest. Silver stores cleaned, columnar data (Parquet or Delta) that compresses significantly better. Gold tables are small by design: pre-aggregated, purpose-built, and queried most frequently. Apply tiered storage policies so bronze data moves to cheaper cold storage after a defined retention window. Vacuum and optimize Delta tables in silver and gold on a regular schedule to reclaim space from small files and stale versions. Partition pruning at the silver layer also reduces scan costs for downstream gold transformations.
Optimizing ingestion frequency by layer
Not every layer needs the same cadence. A practical default: ingest bronze continuously or near-continuously to preserve raw fidelity; refresh silver on a micro-batch or hourly schedule aligned to source system update frequency; rebuild or incrementally update gold on the schedule your BI tools and dashboards actually refresh. Decoupling layer cadences prevents a slow upstream source from blocking downstream consumers and avoids unnecessary reprocessing. Review ingestion schedules quarterly—business reporting cycles change, and a pipeline built for daily refreshes may be running hourly for no reason, silently burning compute budget.
Frequently Asked Questions
What is the difference between bronze, silver, and gold layers?
Bronze holds raw, unmodified data exactly as it arrived from the source—no transformations, no corrections. Silver applies cleaning, deduplication, and schema enforcement so the data is consistent and query-ready. Gold contains business-level aggregates and domain-specific tables built for a specific consumer: a BI dashboard, a risk model, or a recommendation engine. Each layer represents a higher level of trust and a narrower scope of use.
Can medallion architecture work with streaming data?
Yes, and it is increasingly common. Streaming sources continuously land events into bronze, often via message brokers. Micro-batch or streaming jobs then promote records through silver and gold on a schedule that matches the downstream SLA. The layer boundaries stay the same; only the ingestion frequency changes. Platforms like Databricks Structured Streaming and Snowflake Dynamic Tables handle this promotion natively without requiring a separate streaming architecture.
Is medallion architecture the same as a data lakehouse?
No, they operate at different levels. A data lakehouse is a storage and compute platform that combines the flexibility of a data lake with the governance of a warehouse. Medallion architecture is a design pattern you apply on top of that platform to organize data into progressive quality layers. You can implement the medallion pattern on a lakehouse, a cloud data warehouse, or plain object storage. The pattern does not require a specific platform.
How does MDM fit into medallion architecture?
Master Data Management integrates most naturally at the silver-to-gold boundary. Silver holds cleansed, conformed records from individual source systems. Before promotion to gold, an MDM process resolves entity identity—matching customer records, product SKUs, or supplier IDs across systems and assigning a canonical master key. Gold tables then reference that master key, so every downstream consumer works from a single, reconciled version of each entity. Teams that skip this step typically discover conflicting entity counts in gold-layer reports, which erodes analyst trust faster than almost any other data quality failure.
Conclusion
Medallion architecture is not a magic pattern that fixes bad data pipelines on its own. The real value is structural: it forces your team to agree on what 'clean' means before anyone writes a query, and it gives each layer a clear owner. That contract - not the three-tier naming convention - is what makes the pattern work.
Platforms like Databricks and Microsoft Fabric are absorbing more of the orchestration layer, which means the bronze-silver-gold model is increasingly baked into default configurations rather than something teams design from scratch. As streaming-first pipelines and AI feature stores push quality requirements upstream, teams with clean layer boundaries will have less rework to do - the contracts are already in place.
If you are ready to move from concept to implementation, start with a single source system. Map its raw schema to a bronze table, define five concrete data quality rules for the silver layer, and build one gold aggregate that a business stakeholder actually uses. Ship that before designing the full architecture. A working three-layer pipeline for one domain teaches you more than any diagram.


.webp)







