

Companies often keep records in separate systems. Engineers must copy files between these systems to build reports. This work takes time. It leads to conflicting numbers across departments. You might see one revenue figure in sales and another in finance. A Databricks Lakehouse stops this waste through enterprise data integration and cloud data unification. You keep all data in one location. Book a call, get advice from DATAFOREST, and move in the right direction.
Is Your Scattered Data Costing You Money?
Companies lose profit when they cannot see all their data in one place. Teams waste time fixing errors instead of building products. This problem gets worse as you add more software tools without a clear data architecture strategy.
The financial impact of split records
Data silos stop teams from working together effectively. Marketing often holds one list of customers. Sales uses a different list with conflicting numbers. This mismatch leads to bad decisions. Employees spend hours copying files between systems. They must fix format errors manually. This manual work delays important weekly reports. You pay for storage in multiple places. Security risks increase with every new copy you make. Your business reacts slowly to market changes—something a Databricks Lakehouse architecture with Databricks data integration and cross-platform data integration prevents.
Old storage systems cannot keep up
Data warehouses worked well for structured numbers in the past. They struggle with images, video, and text logs. Data lakes accept all file types easily. They often become swamps without clear organization or proper metadata management. Finding specific files in a lake takes too long. Managing two separate systems doubles your engineering work. Engineers must move data constantly between the lake and the warehouse. These connections break often and need repair. Updates take days to reach the final report. You need fast access to both types of data, which Databricks Lakehouse architecture enables with big data integration, data orchestration, and improved data reliability.
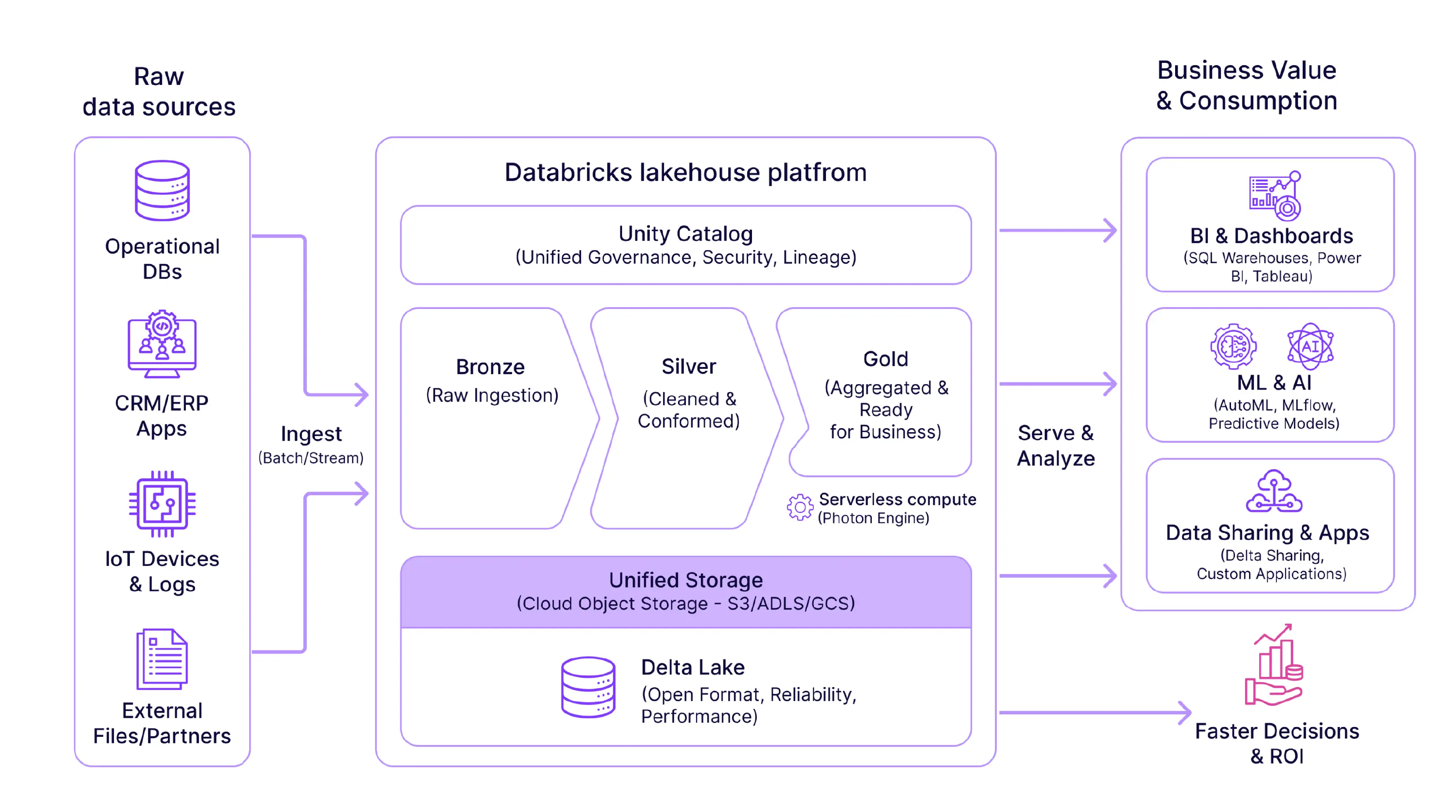
How Does a Lakehouse Solve Data Problems?
Data teams struggle with slow and disconnected systems. A Databricks Lakehouse combines two older technologies into one efficient platform and supports modern real-time analytics, predictive analytics, and Databricks data pipeline automation. It fixes the gap between business analysts and software engineers.
Differences between storage models
Warehouses handle structured tables well. They fail when you add video or text files. Data lakes store these complex files cheaply. But lakes lack strict rules for quality. You often get a swamp of messy files. Teams cannot find what they need quickly. A Lakehouse fixes both of these issues. It adds structure to the messy lake. You keep the low cost of the lake storage. You gain the speed of the warehouse query engine. Analysts run reports fast. Scientists train models on the same files. No one copies data back and forth. It unifies the workflow.
If you see this is your case, then arrange a call.
What the platform actually does
The platform is based on open file formats. You own your data forever. It doesn't lock you into a single vendor. The engine processes large datasets quickly. It easily manages batch jobs. It also processes streaming data in real time. Governance features automatically track every file. You know who is touching sensitive information. Security rules are enforced everywhere. Teams write code in Python or SQL. They collaborate in shared workspaces. This significantly speeds up projects. The Databricks Lakehouse architecture supports every stage of the data lifecycle.
Unified governance: Manage permissions for files, tables, and dashboards in one place.
Open formats: Store data in Delta Lake format for quality and speed.
AI and business intelligence support: Run SQL queries and machine learning models on the same data.
Real-time processing: Instantly receive and analyze streaming data.
Business case for migration
Large companies need reliability above all else. They can’t afford downtime or lost records. Databricks provides a stable foundation for growth. It works on all major clouds. You can easily migrate from AWS to Azure. The platform automatically scales during peak hours. It shuts down clusters during downtime to save money. This flexibility keeps budgets tightly under control. It’s easier to manage compliance. Auditors see a clear history of data usage. The tool supports the full machine learning lifecycle. For organizations looking to operationalize advanced AI, specifically large language models, Databricks for LLMOps offers the necessary infrastructure to manage their unique lifecycle efficiently. Companies launch AI products faster. They stay ahead of the competition.
Streamlined Data Analytics

Their communication was great, and their ability to work within our time zone was very much appreciated.
Why Is It So Hard to Get All Your Data in One Place?
Companies collect vast amounts of data. They don’t get the full picture because pieces are in separate systems. This disconnect slows down decision-making and creates daily friction—the exact problem a Databricks Lakehouse solves.
What your current data configuration looks like
Companies rely on a mix of old and new tools that don’t mesh with each other. Each team builds its own stack, and data is spread across CRM, ERP, files, and custom applications. Many of the connections between these tools started out as quick fixes. Data timelines shift over time, creating inconsistencies that no one tracks. The final dataset arrives in one place late and with errors—a situation eliminated by Databricks Lakehouse architecture.
The tricky parts of data unification
- Systems store data in different formats.
- Old tools break when the workload increases or the rules change.
- Bad records proliferate when multiple sources feed into one place.
- There is no clear owner, so each team protects its own records.
- Security rules restrict data movement.
- Real-time updates fail when pipelines come from past projects.
- Business rules change quickly and leave old data flows behind.
How Do You Build a Central Data Platform?
To bring heterogeneous data together in one place, a clear structure is essential. A Databricks Lakehouse architecture provides this foundation. It's not enough to simply put files in a folder and hope for the best. A structured approach is crucial so that your team can actually use the information later.
Planning the foundation
First, create a list of all your data sources. You need to know where the data is currently located. Map out the relationships between these systems. Architects develop a plan for the central repository. They determine how folders and tables will be organized. A well-designed Databricks Lakehouse architecture prevents chaos and controls storage cost from day one.
Import and cleansing
Databricks developers write automated scripts to ingest and clean the data. Databricks developers write automated scripts to ingest and clean the data. Companies that need to accelerate implementation often choose to hire data engineer specialists to build ingestion pipelines, automate data quality checks, and maintain reliable Lakehouse operations. Raw files move to a bronze zone, cleaned data to silver, and curated reporting data to gold—a framework native to Databricks Lakehouse implementations. You retain this original copy for security and auditing purposes. Scripts clean the datasets and correct formatting errors. The system filters out erroneous or duplicate rows. This cleansed data is moved to the trusted area. In the final step, the data is aggregated for reporting.
Security and analysis
Administrators apply security rules to new tables. They define which teams can view which columns. A central catalog records every file in the system. Business analysts connect their dashboard tools instantly. They run queries without needing to ask the developers for help. Data analysts use the same files for their experiments. The company trusts the numbers because they come from a single source supported by a Databricks Lakehouse architecture.
McKinsey: “A Databricks Lakehouse architecture gives a unified, scalable, governable data foundation. This makes gen AI adoption faster and more impactful.”
Will Lakehouse Accelerate Your Business Growth?
Teams need speed and accuracy to survive in the marketplace. A single data platform eliminates barriers between teams. Profits grow when you act on clear facts. Speed, cost reduction, real-time decision-making, and AI adoption are natural outcomes of a Databricks Lakehouse architecture.
Make decisions based on facts
Leaders hate guesswork. They need accurate numbers to validate their strategies. Legacy systems delay these reports for days. The Databricks Lakehouse architecture provides access to current sales figures in real time. Leaders see trends the moment they occur. They adjust budgets immediately. Marketing campaigns change direction based on live feedback. No one waits for the end of the month. Data is consistent across every department. Trust replaces suspicion in the boardroom.
For example, a retail chain detects a sudden drop in coat sales and cancels a factory order that same day.
Launching machine-learning products
Many AI projects never leave the lab. Data scientists often work in isolation with legacy files. Porting code to production usually breaks the application. A Databricks Lakehouse architecture fixes this broken pipeline. Engineers and scientists share the same workspace. They use the same fresh data sources. Models are trained on the full history of customer actions. Deployment becomes a repeatable software process. You instantly detect fraud or recommend products. The system monitors the accuracy of the model over time.
For example, a logistics company retrains its delivery routing algorithm every night to account for new road construction.
Reduce technical costs
You stop paying for duplicate storage. Traditional setups force you to copy data multiple times. This habit doubles or triples your cloud bill. A Databricks Lakehouse architecture keeps one copy for everyone. You also reduce the need for specialized tools. One platform handles engineering, science, and analytics. This consolidation simplifies the licensing structure. Engineering teams spend less time maintaining connections. They build new features, not fix pipelines. You only pay for the minutes used.
For example, a healthcare provider decommissions four separate SQL servers and cuts its monthly infrastructure costs in half.

Should You Build or Buy Your Own Data Platform?
Should You Build or Buy Your Own Data Platform?Companies often struggle to decide between building internally and partnering externally. The right choice depends on your timeline and available talent, as a wrong move here results in wasted budget and lost months. To mitigate these risks, many leaders start with modern data architecture consulting to validate their roadmap before writing a single line of code. Pairing your internal team with an experienced partner accelerates production and guarantees a compliant, scalable Databricks Lakehouse architecture that aligns with your long-term business goals.
Risks of doing it yourself
Internal teams often lack specific experience with a new platform. They learn by making mistakes in your production system. This trial-and-error approach delays launch by months. You pay for the time they spend reading documentation. The resulting Databricks Lakehouse architecture often doesn’t scale.
- Engineers misconfigure security settings and expose sensitive files.
- Cloud bills increase as clusters run longer than necessary.
- Maintenance tasks overwhelm the team and stall new work.
- Custom code becomes a black box that no one understands.
- Businesses miss market opportunities while waiting for data.
The value of external assistance
Partners bring a library of proven code to the project. They don’t guess at the right setup. They’ve solved these specific problems for other customers. This experience eliminates the risk of a failed implementation. You get a production-ready Databricks Lakehouse architecture much faster.
- The partner immediately trains your team on best practices.
- They implement strict governance rules to protect information.
- Costs stay low thanks to an efficient architecture.
- Your employees focus on analytics, not infrastructure repairs.
- The project is delivered on time and has reliable results.
DATAFOREST will do the same; you need to arrange a call.
Who Truly Benefits from A Single Lakehouse Architecture?
Data aggregation solves specific problems faced by various industries. Banks can better protect their funds. Factories can ensure machines run smoothly. Industries such as banking, e-commerce, healthcare, and manufacturing can all benefit from automation, real-time analytics, and unified AI workloads—all powered by the Databricks Lakehouse architecture.
Banking and Finance
The problem: Banks need to detect fraud as soon as it occurs. They typically cross-check credit card transactions with historical records. This delay allows thieves to steal funds before anyone notices.
The solution: The platform immediately imports transaction logs into the system. The model compares current activity with historical patterns. The bank immediately freezes the card.
Results: Fraud detection rate increased by 30%. False positive rate decreased by 20%. Banks avoided millions of dollars in losses.
Shopping & e-commerce
The problem: Stores struggle to keep the right products on shelves. They guess demand based on last month’s sales. Customers leave when they can’t find what they want.
The solution: A Databricks Lakehouse architecture combines daily sales with weather forecasts and holiday trends. Algorithms accurately predict how many units to order. Managers accurately restock shelves.
Results: Inventory costs are reduced by 15%. Shortages are reduced by 25%—revenue increases because products are in stock.
Factories and logistics
The problem: Machines break down without warning on the assembly line. The factory stops production for several days to fix the equipment. This unplanned downtime disrupts the schedule.
The solution: Sensor data feeds real-time analytics in a Databricks Lakehouse architecture. The software predicts when a part will fail. Technicians replace the part during a scheduled downtime.
Results: Unplanned downtime is reduced by 35%. Maintenance bills are reduced by 10%. Production at the factory remains stable.
Medicine and research
The problem: It takes nearly a decade to develop new drugs. Researchers waste time searching disparate patient databases. This fragmentation slows down life-saving treatments.
The solution: A Databricks Lakehouse architecture combines genetic data and clinical records. Scientists analyze both datasets in a single query. They identify promising compounds much faster.
Results: Discovery time is reduced by 40%. Clinical trials start earlier. New treatments reach patients years sooner.
Forbes: “Lakehouse unifies data storage and workloads. It reduces infrastructure complexity, speeds up onboarding, and supports diverse use cases—from BI to real-time AI.”
DATAFOREST Builds a Production-Ready Databricks Lakehouse Architecture
DATAFOREST unifies a complex enterprise data stack within the Databricks Lakehouse. DATAFOREST is a modern data architecture company that unifies a complex enterprise data stack within the Databricks Lakehouse. We migrate legacy data warehouses (such as Redshift or SQL Server) to a Medallion architecture with bronze, silver, and gold zones. This migration makes raw data available for querying, keeps its consistency clean, and reduces costs. The team builds automated pipelines using Delta Live Tables and Databricks Jobs. These pipelines run reliably and report failures instantly. Engineers connect this data warehouse to existing business intelligence tools (Power BI, Tableau, Looker, etc.) so dashboards are updated in near real-time. We integrate machine learning and AI workflows on a single platform using MLflow, model servicing, and pipeline automation. DATAFOREST provides data governance, security, and audit trail management to ensure regulated sectors (healthcare, finance) remain compliant. We also configure clusters and storage to scale under heavy load while maintaining predictable compute costs. The result: a single platform for analytics, business intelligence, and machine learning that runs at production loads, remains manageable, and delivers analytics quickly. We ensure your Databricks Lakehouse runs at scale, supports analytics, AI, BI, and compliance with repeatable reliability.
Has Lakehouse Replaced Data Warehouses and Data Lakes?
Data warehouses and data lakes are still in use in many large companies. Businesses can't replace their decades-old infrastructure overnight. Many teams continue to maintain legacy repositories for specific financial reports. Data lakes often serve as cost-effective archives for raw data. But the industry is moving away from these separate systems because maintaining fragmented datasets introduces risk, inconsistent governance, and weak data reliability. Managing two different platforms is too time-consuming and expensive. Developers are hesitant to exchange data between data lakes and data warehouses. Databricks' Lakehouse architecture solves this data redundancy problem. New projects almost always start on this central platform. Older models haven't disappeared, but they are being gradually replaced.
Please fill out the form to unify data in Databricks.
Questions On Databricks Lakehouse Architecture
How long does it typically take to unify enterprise data in Databricks Lakehouse?
Companies complete an initial pilot or specific high-value use case in about 12 weeks. A full enterprise migration to a Databricks Lakehouse often takes 6 to 12 months, depending on the volume and complexity of the data. You should avoid trying to migrate each individual data set at once in a “big bang” approach. Teams typically migrate mission-critical data first to prove value and demonstrate immediate ROI to management. Timelines can be significantly shortened if you leverage experienced partners or use automated code transformation tools designed for Databricks Lakehouse architecture deployments.
What business metrics improve first after implementing a single Lakehouse?
The immediate improvement is typically a reduction in monthly cloud infrastructure costs. You stop paying for storage duplication and compute downtime almost instantly with a Databricks Lakehouse architecture. Data latency is reduced from days to minutes, allowing executives to make decisions in real time. Data engineering teams report a dramatic reduction in maintenance hours and support tickets. This efficiency frees up budget and time for new, revenue-generating analytics projects running on the Databricks Lakehouse.
Can Databricks Lakehouse replace our existing BI and BI tools?
It doesn’t necessarily have to replace your current tools, but it certainly can if you prefer consolidation. Databricks Lakehouse offers native “AI/BI dashboards” that do a pretty good job of visualization and internal reporting. However, most large enterprises continue to use Power BI or Tableau for their client-side dashboards. The Databricks Lakehouse architecture becomes a single, high-speed engine that powers these existing tools. This hybrid approach avoids the painful cost of retraining all of your business users.
What level of maturity does your internal data team need before starting a Lakehouse project?
Your team doesn't need to be experts in complex coding languages like Scala to get started. A deep understanding of SQL and basic cloud infrastructure concepts is enough for the initial setup. As the Databricks Lakehouse architecture grows, engineers may adopt modern practices such as CI/CD pipelines, automated testing, and data governance frameworks. Partners can handle Databricks Lakehouse architecture design while your internal team upskills on the job.
Is Databricks Lakehouse a good fit for companies with strict regulatory requirements?
The platform is purpose-built to handle highly regulated data like medical records and financial transactions. Databricks Lakehouse supports major compliance standards out of the box, including HIPAA, GDPR, PCI-DSS, and FedRAMP. Unity Catalog provides a centralized control plane to manage permissions and audit every user action. You can trace the full lineage of any data point—from ingestion to final dashboard—and apply column-level masking, encryption, or role-based access automatically across the Databricks Lakehouse architecture.


.webp)







