Podcast Platform Boosts Engagement 7× Using AI Recommendations
A leading podcast platform partnered with Dataforest to replace manual recommendations with an AI-powered personalization engine. The new system analyzes user behavior and context in real time to deliver tailored suggestions in under 0.5 seconds, handling up to 20 recommendations per second. This resulted in 7× higher user engagement, enhancing listener experience and significantly increasing the client’s revenue.
7
×
higher user engagement
<
0.5
secs
average recommendation delivery speed
~
20
recommendations/sec throughput
The client is a prominent web and mobile podcast platform based in Saudi Arabia, widely recognized across the MENA region for delivering high-quality, authentic journalism across text, visual, and audio formats. It operates as part of a major media holding that manages multiple outlets spanning news, digital platforms, and social media channels.

Databricks

TensorFlow

Spark

PostgreSQL
.svg)
Databricks vector search
THE CHALLENGE
The podcast platform faced very limited personalization due to its manual recommendation process
The podcast platform relied on static, manually curated recommendations that couldn’t adapt to user behavior. This restricted engagement, slowed revenue growth, and left the platform behind competitors who leveraged dynamic personalization.
.svg)
No Adaptability to User Behavior
Recommendations weren’t responsive to user preferences, resulting in low engagement and poor discovery of new content.
.svg)
Missing Real-Time and Unified Data Infrastructure
The system lacked pipelines to process and unify data across sources, preventing real-time insights and consistent content delivery. This also led to data duplication — with content coming from multiple sources, users often received recommendations for podcasts they had already seen on other platforms.
.svg)
Cold Start Problem for New Users
With no recommendation system for users without history, new listeners had a poor first experience.
.svg)
Scalability Gaps
The legacy approach couldn’t support rapid growth in users and content, limiting future expansion.
THE SOLUTION
AI-Powered Recommendation Engine with 7x Engagement Boost
We built a flexible recommendation model that processes diverse user signals in real time.
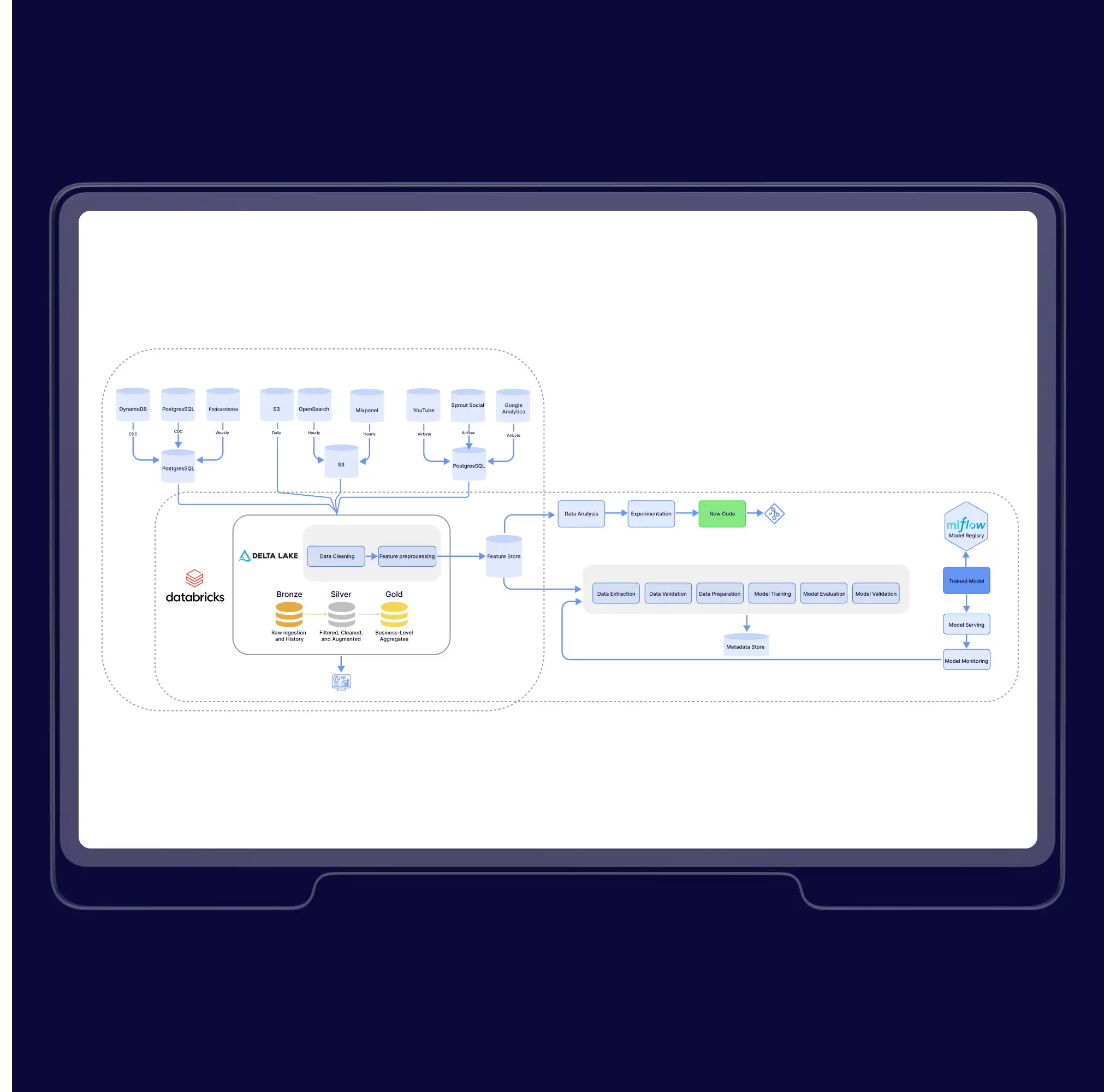
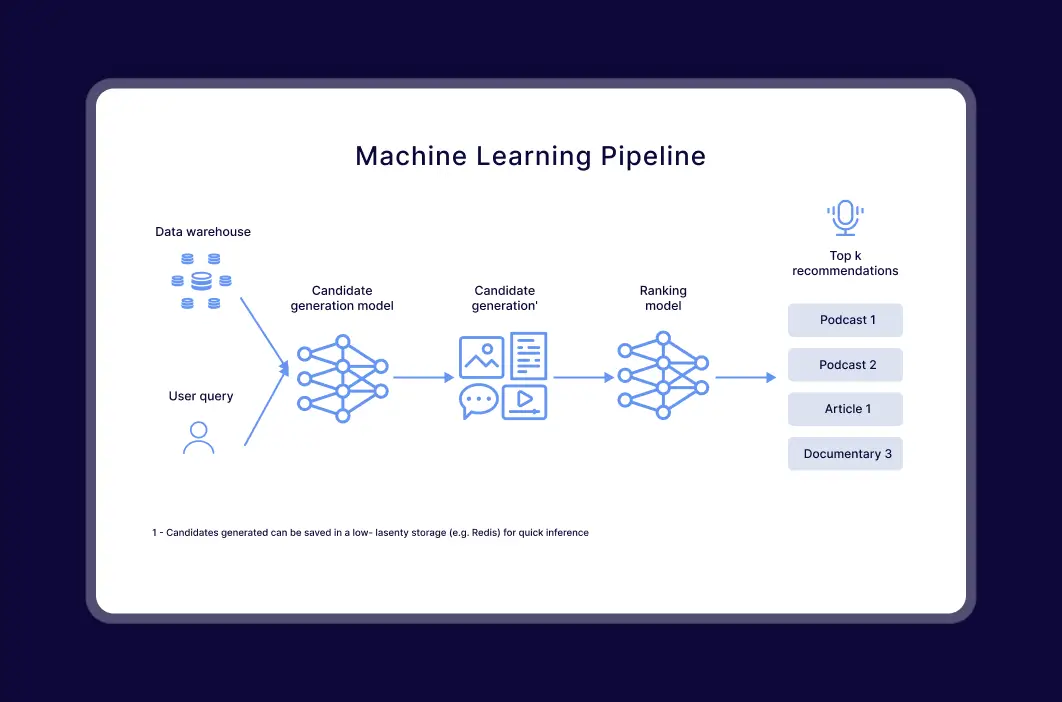
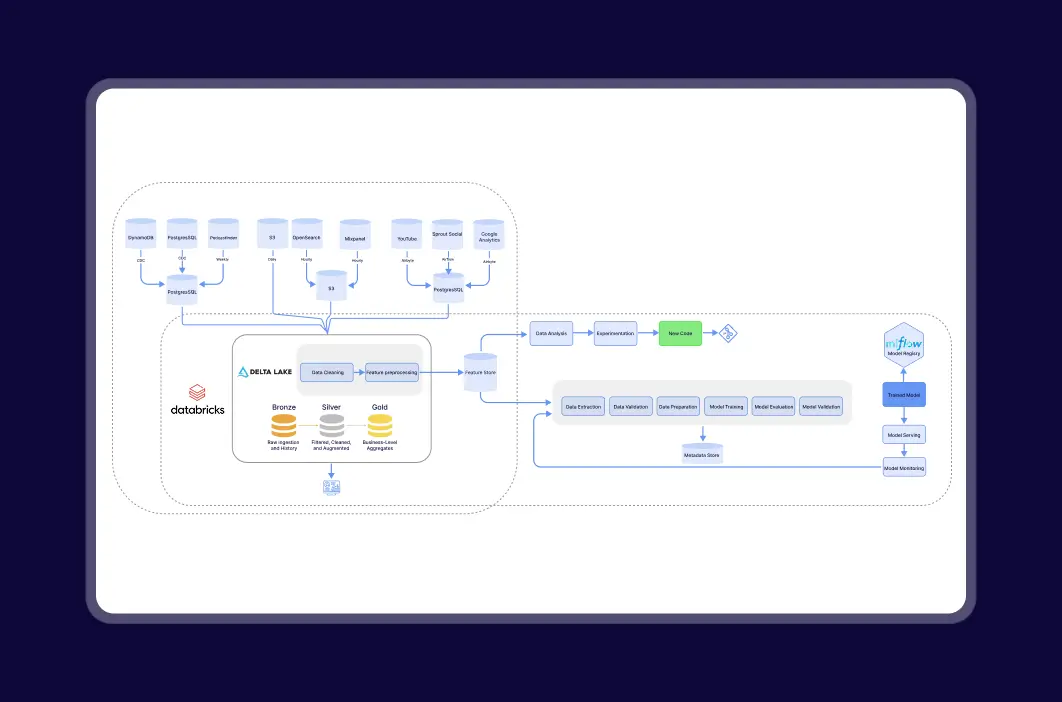
The solution architecture included four interconnected recommendation models based on two-tower architectures, each designed to process different user signals and content types.
It delivers highly relevant podcast suggestions, improving user engagement by 7x and enabling scalable growth.
.svg)
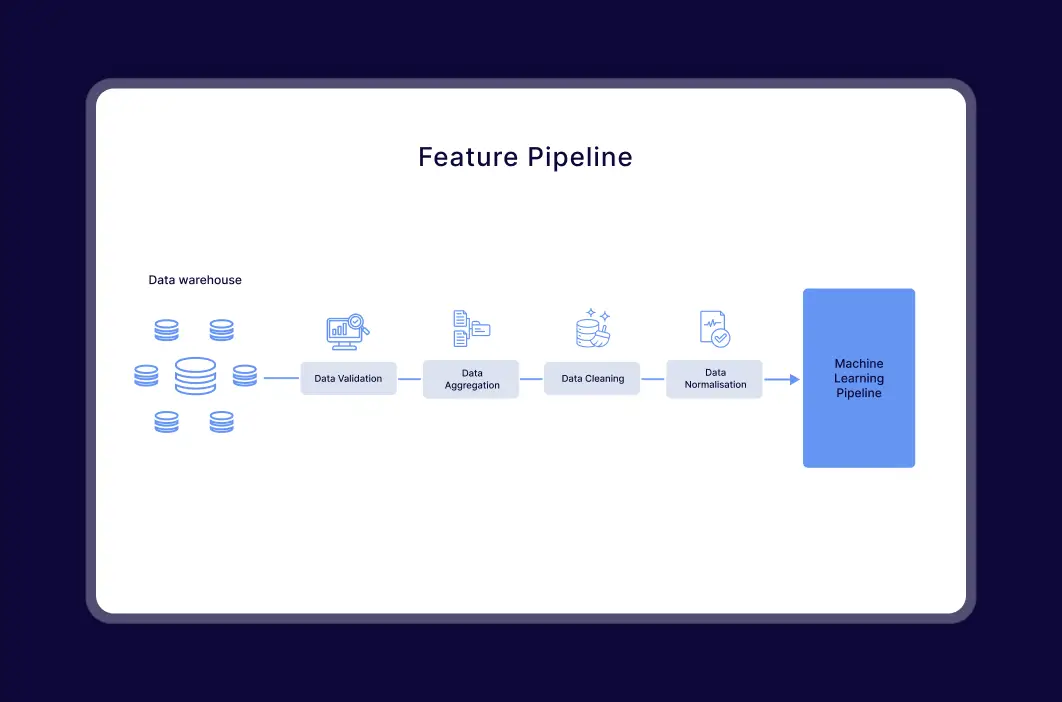
Real-Time and Unified Data Infrastructure
We developed automated ETL pipelines that continuously collect, clean, and synchronize data from all media channels — including the website, social platforms, and radio. This eliminated data duplication and enabled instant processing for consistent, high-quality recommendations across all user touchpoints.
.svg)
Contextual Cold Start Solution
For new listeners without behavioral history, we introduced a context-aware recommendation module that leverages signals like time of day, device type, location, and language. This ensured that even first-time users received meaningful, personalized recommendations — improving retention from the very first session.
.svg)
Adaptive Personalization Engine
To address low adaptability to user behavior, we implemented four recommendation models built on two-tower architectures. These models analyze multiple user signals such as listening history, engagement patterns, and metadata, dynamically adjusting to user preferences and delivering relevant podcast suggestions in real time.
.svg)
Modular and Scalable Architecture
We designed the system as a modular, multi-model framework capable of expanding with the platform’s growing user base and content library. Each recommendation model functions independently but integrates seamlessly through a centralized ranking layer, ensuring consistent performance and scalability as data volume increases.
THE RESULT
AI-Powered Personalization: 7x More Podcast Engagement and 30% Higher User Interaction
A leading podcast platform in Saudi Arabia and the MENA region needed to replace its static, manually curated recommendations to drive growth and user satisfaction. DATAFOREST delivered a scalable AI-powered recommendation engine that personalizes podcast suggestions in real time based on user behavior, preferences, and context.
We developed a modular system with a learning-based ranking model and a real-time data pipeline to process user activity efficiently. Key challenges included scaling the architecture, integrating diverse interaction signals, handling data duplication across multiple content sources, and solving the cold start problem for new users. These were addressed by unifying data streams through real-time ETL pipelines, applying deduplication logic to eliminate repeated content, and combining behavioral data with contextual metadata (e.g., time, language, location). Recommendations now auto-update every 48 hours, ensuring ongoing relevance and eliminating manual work.
This transformation enabled the podcast to personalize content at scale, increase user satisfaction, boost revenue, and future-proof its platform with a flexible, data-driven solution.
average recommendation delivery speed
personalized recommendations processed per second
higher user engagement compared to the manual system (A/B tested)

Podcast Platform Boosts Engagement 7× Using AI Recommendations
The Way We Deal with Your Task and Help Achieve Results





Real-Time AI Voice Agent for Cold Calling
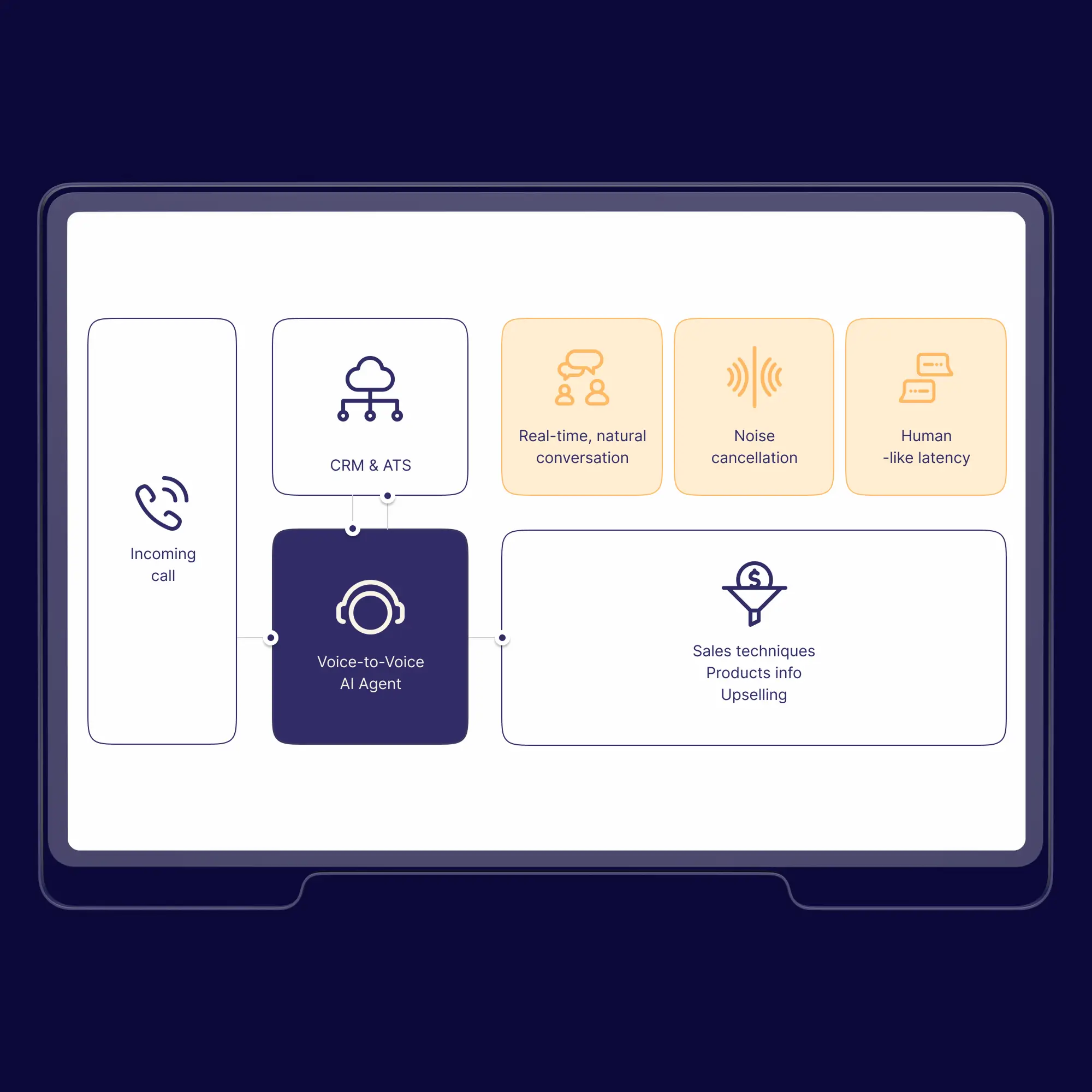
AI-Powered Cold Calling: Real-Time Voice-to-Voice Conversations
Improving Chatbot Builder with AI Agents

Improve chatbot efficiency and usability with AI Agent
LLM-Powered Recommendation System
.webp)
LLM-Powered Recommendation System
Real-Time AI Voice Agent for Cold Calling
AI-Powered Cold Calling: Real-Time Voice-to-Voice Conversations
Improving Chatbot Builder with AI Agents
Improve chatbot efficiency and usability with AI Agent
LLM-Powered Recommendation System
LLM-Powered Recommendation System
Reporting & Analysis Automation with AI Chatbots

Automating Reporting and Analysis with Intelligent AI Chatbots
Latest publications
All publications
Mastering Vendor Risk Management: A Strategic Business Approach

Data Visualization: Making Numbers Tell a Story

Generative AI for Small Businesses: Buzz Becomes Big Honey
Latest publications
All publications
Step-by-Step AI Implementation Plan in 2026

Generative AI Applications in Large Businesses
Generative AI for Small Businesses: Buzz Becomes Big Honey
We’d love to hear from you
Share project details, like scope or challenges. We'll review and follow up with next steps.
