

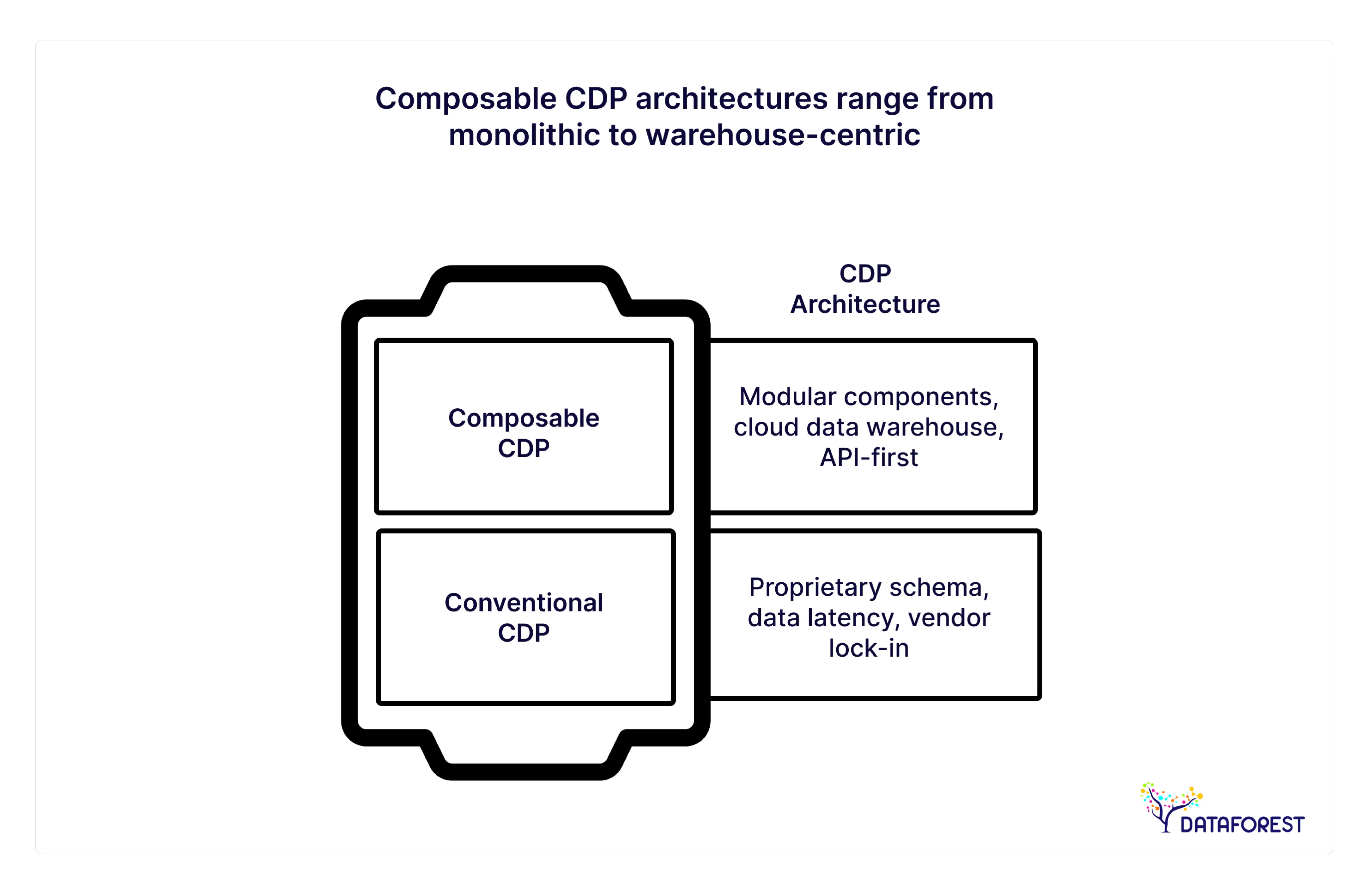
The discussion in consumer data management has definitively turned by 2026. Monolithic “black box” CDPs, where data goes in to die or gets hidden behind proprietary schema, are increasingly seen as a legacy limitation. For today’s C-Suite, the pivot is to a composability model for the CDP: a modular, warehouse-centric architecture where your cloud data infrastructure isn’t simply storage; it’s an active driver of customer experience.
In the high-stakes world of enterprise data strategy, CIOs and CMOs are finding out that duplication is the enemy of agility. Why pay for the privilege of storing your own customer data in a SaaS silo when you have hundreds of petabytes of clean, governed data that’s been meticulously maintained on Snowflake, Databricks, or BigQuery?
This guide gives a good overview of how to build composable CDPs in 2026. We’ll unpack the architecture and CDP architecture design, map out the timeline, and break down what team you need in place to make your data stack a cash cow.
Beneath the Hubbub: The Architectural Shift
Their promise is the “Single Source of Truth” that the traditional CDP offers. But, the truth was too often something like a “Second Source of Truth”—separate from the core data strategy and incapable of delivering more sophisticated predictive analytics use cases.
At DATAFOREST, we see that in 2026, market-leading companies have flipped this on its head. “People are not buying CDPs; they are making them.” Since a composable CDP architecture breaks apart the data collection, transformation, and activation layers (putting you in control), the CDW becomes your epicentre.
This overcomes the “data gravity” issue. Instead of shuffling huge data sets around, you bring the marketing tools to the data. That's the API-first approach to a data platform that serves real-time needs.
Conventional CDPs: the Good, Bad, and Ugly
In order to know and appreciate the future, we must recognize the limitations of the past. The monolithic CDP platforms (Salesforce Data Cloud, Adobe Experience Platform in its former versions) was a product box. They were handy for marketing departments but had little IT support.
But the concealed costs are less and less a tenable approach for today’s enterprise:
- Data Latency: Syncing of data between the CDW and the CDP results in delays, which are a death knell to any real-time personalization campaigns.
- Inflexible Schemas: You have to fit your data model to that of the vendor's definition of a "customer," which usually cannot accommodate complex B2B or hybrid businesses.
- Vendor Lock-in: Extracting terabytes of proprietary data when moving off a monolithic CDP often runs into months of downtime.
To learn more about how to navigate these challenges, check out our thoughts on Digital Transformation Consulting and helping companies move away from legacy debt.
A Practical Guide To Composable CDPs
A clear path to the modular, cloud-native and AI-ready bits.
So, what is a composable CDP? It is not a single product. It’s an architecture where you piece together best-of-breed components on top of your CDW to do the job of a CDP: collect data, unify it, segment, and activate it.
Your cloud data warehouse (Snowflake, Databricks, BigQuery) holds the “Golden Record” in this paradigm. You then pile tools on top of it:
- Ingestion: tools like Fivetran or Snowplow to pipe data in.
- Transformation: Tools like dbt to clean and model data in the warehouse.
- Activation (Reverse ETL): Hightouch or Census to push governed data out to ad platforms, CRMs, and email tools.
This warehouse-held architecture means that when your data engineering team updates a metric in the warehouse, it’s immediately available for marketing activation — a core principle behind a scalable data architecture service approach. It’s an AI-ready data architecture at the core of it, as long as we keep the data where our machine learning models are living.
When to Use a Composable CDP (and When Not)
You need a certain level of maturity for composable to be powerful. When you consider traditional CDP vs composable CDP approaches, the trade-offs become much clearer.
- It's the perfect choice if: You have bought into a modern CDW, have a decent data team (or partner like DATAFOREST), and complex data needs (e.g., joining online behaviour with offline POS transactions).
- It’s not the best option if: You’re a small business that does not have engineering resources, have basic data needs, and are looking for a ready-to-use marketing tool.
For companies in, say, Retail or Fintech, where security and scale matter a great deal, the composable path is almost always better.
Business Drivers for Adopting a Composable CDP in 2026
Why are CEOs betting on this architectural pivot today? Well beyond technology, these drivers are ultimately about business velocity and risk control.
AI, ML, and Advanced Analytics as First-Class Citizens
By 2026, AI is not an experiment; it’s a business necessity. Conventional CDPs are not well-suited to support machine learning pipelines. You have to export data, train models elsewhere, and then import the outcomes again — a clunky, latent process.
With a modular CDP, the platform enables direct integration with Gen AI in place. Your data science team can execute propensity models or churn predictions directly on the CDW using tools such as Databricks or Snowflake Cortex, and the results are actionable immediately.
For example, a global e-commerce brand ran real-time inventory matching algorithms against a user's browsing history using the composable stack, resulting in an 18% lift in conversion for Q4 2025.
For instance, A healthcare provider leveraged the secure CDW environment to perform sensitive patient risk analysis without ever sharing PII with a third-party marketing cloud.
To learn more about how to create infrastructure like this, check out our Generative AI Data Infrastructure.
Data Privacy, Compliance, and First-Party Data Strategies
As third-party cookies are officially deprecated once and for all, as well as tighter GDPR/CCPA laws, third-party technographic data should be a thing of the past in enterprise customer data management. A composable approach can and does store PII (Personally Identifiable Information) in your controlled cloud. You only "activate" (send out) the minimal amount of data hashed out to advertising platforms. This reduces the attack surface, as well as streamlines the compliance audit process.
Cost Efficiency and Long-Term Architectural Flexibility
Older CDPs are priced by “MTUs” (Monthly Tracked Users) or data. As you grow, costs explode. A modular data stack is typically cost-effective, as you’re paying for compute and storage (commodities), not high-margin SaaS fees. Alternatively, you can replace specific parts (e.g., updating your Reverse ETL provider) without having to re-architect the whole data foundation.
Find out how to optimize these spends here in our Cost and Performance Optimisation guide.

Reference Architecture for a Composable CDP in 2026
A Composable CDP Architecture is Only as Good as Its Blueprints. At DATAFOREST, we use a reference architecture that is scalable and available.
Core Architectural Principles
- Decoupling: Storage separates from compute, transformation separates from activation.
- Declarative Definitions: Metrics and audiences exist as code (either traditional SQL or YAML), are version controlled, and testable—no more building metrics in a drag-and-drop app that acts like a black box.
- Source Governance: Security policies are assigned at the source and enforced downstream automatically.
Key Architectural Layers
In general, the stack can be decomposed into four layers.
- Data Collection (The "Event" Layer): Collecting behavioral data from web, mobile, and server-side applications. This feeds the ELT pipelines.
- The Storage & Compute Layer (The Warehouse): The workhorse of the system. This is the birthplace of identity resolution and unification.
- The Transformation & Modeling Layer: Transforming raw events to “user traits” and “audience.”
- The Data Activation Layer: The "Reverse ETL" pattern that syncs the modeled data to end destinations (Salesforce, HubSpot, Google Ads, Braze).
For a deep dive on how we build these pipelines, check out our Data Pipeline & ETL Intelligence service page.
Common Technology Stack Examples
A representative 2026 enterprise stack would look something like this:
- Collection: Snowplow, or RudderStack (we prefer open source for control).
- Warehouse: Snowflake or Databricks Lakehouse. (See our Databricks Architecture solutions).
- Transformation: dbt (data build tool) to define the data models.
- Activation: Hightouch or Census.
- Orchestration: Airflow or Dagster to manage the dependencies.
Team Breakdown: Who You Need and Why
The technology is only 40% of the equation; talent is the other 60%. Creating a composable CDP turns your organization from a software purchaser to a capability creator. This means that you need to redesign your DevOps as a Service and Data Engineering organizations.
Core Roles for a Composable CDP Program
To use and support this architecture effectively, you must fill these roles:
- Data Architect (1 FTE): The architect who designs the schema, chooses tools from the modern data stack, and makes sure the identity resolution structure fits business requirements.
- Data Engineers (2–3 FTEs): Focus on building the ELT pipelines, maintaining warehouse performance, and ensuring data quality.
- Analytics Engineer (1–2 FTEs): The link between data and marketing. They author the dbt models that define "Active Users" or "High-Value Customers."
- Product Manager (Data Platform) (1 FTE): Thinks of the data platform as a product, prioritizing requests from marketing, sales, and product teams.
Internal Team vs. External Data Partner
But hiring this specialized talent is a challenge for many enterprises, and it takes time. A fully functional data team can take anywhere from 6–9 months to hire. This is where having a company like DATAFOREST as your tech partner has really helped fast-track the process. We refer to it as the “special forces” team — setting up the composable CDP framework, putting governors in place, and then turning back over full control to your internal squad.
Have a look at our Data Architecture and DE Consultancy to find out how we cover the last mile.
How Cross-Functional Collaboration Drives ROI
The Composable CDP makes Marketing and IT talk the same language. Marketing specifies the need ("I need a segment of users who have left carts in the last 2 hours"), and the Data Team writes it once in the warehouse. This transparency removes the “black box” pain of marketing numbers not aligning with finance numbers.
Timeline: Implementation Roadmap
A mid-to-large enterprise deployment averages 12–16 weeks — a fraction of what traditional, monolithic CDPs need (9–12 months) to do the same.
- Month 1: Strategy & Foundation. Audit available data, define identity resolution architecture, and configure cloud infrastructure.
- Month 2: Ingestion & Modeling. Integrate sources and create SQL models in dbt in a non-destructive way, and create the golden record.
- Month 3: Activation & Testing. Set up the data activation layer (Reverse ETL), model and map data flows to destinations, and start pilot campaigns.
- Month 4: Scale & Optimize. Extend to all channels, establish predictive analytics use cases, and move to maintenance.
Common Pitfalls and How to Avoid Them
Strategic planning is needed for the implementation of even the greatest tools.
Overengineering the Stack
There is a natural inclination to want to adopt as many tools from the “Modern Data Stack” for one project as possible. Start simple. You don't need to stream every metric in real-time. 90 percent of the use cases by an enterprise data platform can work with batch processing, for example, every 15 minutes. Over-complexity leads to fragility.
Ignoring Governance and Data Quality
Garbage in, garbage out—faster. If the data in your warehouse is dirty, your activation will be dirty. You should include automated data quality checks (e.g., Great Expectations, Monte Carlo) as part of your pipelines. Without it, marketing teams will lose confidence in the data.
Learn more about our quality process in Data Integration and Management.
Treating Composable CDP as a Tool, Not a Capability
A composable CDP is not something you "install." It is a workflow. If you do not alter how your marketing team asks for information or how your engineering team orders data models, that technology will not actually be worth anything.
Measuring Success: KPIs and Business Impact
And how do you demonstrate the ROI of a composable CDP back to the CFO? You should monitor technical and business metrics.
Technical and Data KPIs
- Data Latency: Elapsed time between "event happens" and "available for activation." (Target: < 15 minutes).
- Freshness: Percent of records refreshed within SLA.
- Engineering Hours Saved: Less time spent manually pulling CSVs for marketing.
Business and Revenue KPIs
- Time-to-Market per Campaign: How quickly can a new target group be designed and addressed? (Drop from weeks to hours).
- CAC (Customer Acquisition Cost): Improvements in suppression of existing customers.
- CLV: Hyper-personalized upselling backed by machine learning pipelines for increasing CLV.
Check out how we visualize these metrics with our BI and Data Analytics offerings.
How a Data-Driven Partner Accelerates Composable CDP Success
There are platform decisions to make, but a composable architecture is a strategic decision impacting every level of your tech stack. At DATAFOREST, creating these high-performance data engines for complex industries is our specialty.
We have developed the most advanced end-to-end solutions for high-value E-commerce needing real-time personalization and Healthcare requiring compliance data unification.
Why DATAFOREST?
- Vendor Neutral: We promote the stack that fits your business, not the vendor that pays out the most commission.
- Data Science Roots: We don’t just transport the data, we bring smartness to it. Custom API Development and Data Science expertise make sure your CDP is AI-ready.
- Proven History: See a case study of us building a Custom Retail Customer Data Platform to see our architecture in the wild.
If you need to move off a legacy monolith, or if you have aspirations of an API-first data platform but don’t know where to start, we bring the architectural rigor and engineering muscle necessary.
Are you ready to future-proof your customer data strategy?
Get a free consultation with our Lead Architect now.
Conclusion
During this time, the Composable CDP has graduated from a cutting-edge idea to a state-of-the-art solution for enterprise customer data management by 2026. It provides the nimbleness, strong privacy safeguards, and cost effectiveness that you simply can't get with monolithic platforms. By architecting around the Cloud Data Warehouse and considering data activation as an engineering discipline, you bring out the full potential of your first-party data.
The transformation demands a change of mindset and strong technical expertise; however, the destination—a real data-driven/AI-written enterprise—is worth every penny.
FAQ
What business problems does a composable CDP solve better than traditional CDP platforms?
Legacy CDPs are siloed, causing a gap between the marketing data and an enterprise’s financial/operational data. A composable CDP addresses this by establishing CDW as the single source of truth. It saves the cost of having to pay for data storage twice and allows for much more sophisticated data modeling (B2B2C relationships, etc.) than inflexible, off-the-shelf CDPs can accommodate. It also prevents vendor lock-in and allows the business to fully own its data.
How does a composable CDP support AI and machine learning use cases in large enterprises?
Being composable, a CDP directly connects to the data warehouse (like Databricks or Snowflake) and therefore has native access to all your historical data. This makes it possible for machine learning pipelines to execute in the place where the data is, with no hoops needed. With their favorite tools (Python, R, SQL), data science teams can build propensity, churn, or lifetime value models, and the composable activation layer syncs these model outputs to marketing tools for immediate activation.
How long does it typically take to implement a composable CDP in an enterprise environment?
An MVP of the composable CDP architecture works well within 12–16 weeks (3–4 months) on average. That includes warehouse, ingestion pipelines (ETL), data modeling (dbt), and the first few activation destinations. This is considerably faster than traditional CDPs, which require 9–18 months for data migration and proprietary schema mapping workflows.
What are the most common architecture patterns for composable CDPs in 2026?
The leading pattern in 2026 is the Warehouse-Native, or “Reverse ETL” pattern.
- Ingestion: ELT tools (Fivetran, Airbyte) bring raw data into the warehouse.
- Storage: Cloud DW (Snowflake, BigQuery, Databricks).
- Modeling: Transformation tools (dbt) standardize and bring together data into a “Golden Record.”
- Activation: Reverse ETL tools (Hightouch, Census) sync segments to business apps (Salesforce, Ads, Email).
- Orchestration: Tools such as Airflow take care of when these flows should run and their relationship to each other.
What governance and privacy challenges should be addressed when building a composable CDP?
The first obstacle is to make sure that democratizing access to data doesn’t lead, paradoxically, to a loss of control. You need to enable Role-Based Access Control (RBAC) at the warehouse. And because you’re building the system yourself, you control consent (GDPR / CCPA / DMA). You need to be positive that DNT flags in the warehouse are strictly observed by the activation layer, so users who express a preference not to be synced into advertising platforms.
How does a composable CDP integrate with existing CRM, marketing automation, and product analytics tools?
It connects through API-first data platform approaches that leverage "Reverse ETL." Unlike point-to-point integrations (such as hooking up your website directly to your CRM), the composable CDP passes clean, modeled data from the warehouse back and forth to these tools through their APIs. This means that your CRM (e.g., Salesforce), Marketing Automation (e.g., Marketo), and Product tools (e.g., Mixpanel) all see the same precise customer definitions, metrics, and reporting as they are driven by the same warehouse models.


.webp)







