

A retail giant launched fifty AI agents across ten departments on one central data mesh. Each agent followed the same naming rules and access protocols. This system allowed the firm to triple its agent count in one year, demonstrating successful scaling of agentic AI.
A bank chose a different model and let every team build its own agent logic. These silos created conflicting data outputs and broke security audits. High maintenance costs forced the bank to shut down the project after nine months, halting their progress in scaling agentic AI.
Book a call to fix your data standards.

Why Do Artificial Intelligence Systems Fail in Production?
Technology executives spend millions of dollars on new artificial intelligence software, often with the goal of scaling agentic AI. The early technical prototypes process clean databases on secure servers. The entire system crashes under the massive traffic of the active corporate network.
The high cost of isolated tests
Data engineers build artificial intelligence prototypes on secure and isolated servers. They feed perfectly clean data into these controlled technical tests. The early results impress executives with a 95 percent accuracy rate before scaling agentic AI.
The technical team moves the exact code to the main corporate network. Real production databases push 50 terabytes of messy text into the active pipeline every single day. The original prototype immediately breaks under the massive strain of 10,000 concurrent user requests. The enterprise loses $2,000,000 on the failed transition to a full production system, a common disaster when scaling agentic AI. Such disastrous transitions from prototype to production are often avoided when organizations prioritize operationalizing agentic AI models, ensuring reliable performance even under massive strain.
The barrier of disconnected records
Technology executives buy expensive artificial intelligence algorithms from large software vendors. These mathematical models process clean numbers with extreme speed. The actual corporate network holds 50 petabytes of unformatted text and millions of fragmented database tables. Sales teams and finance departments lock their daily files in separate proprietary systems. The new software fails to read this disconnected information. The system outputs incorrect financial projections based on missing records. So, data architects rebuild the broken pipelines with a central data lakehouse, a necessary step for scaling agentic AI.
The hidden cost of autonomous systems
Standard artificial intelligence answers single questions from a static database. Agentic artificial intelligence triggers thousands of actions across the entire corporate network. These autonomous programs run continuous loops, and they update customer records every ten milliseconds. The sudden spike in automated traffic overwhelms standard application programming interfaces. For example, data architects purchase 500 new cloud servers for the constant data flow. They build new network clusters with fast hardware for instant database writes. The technology budget increases by millions for these machines, proving the hidden costs of scaling agentic AI.
Real-Time AI Voice Agent for Cold Calling
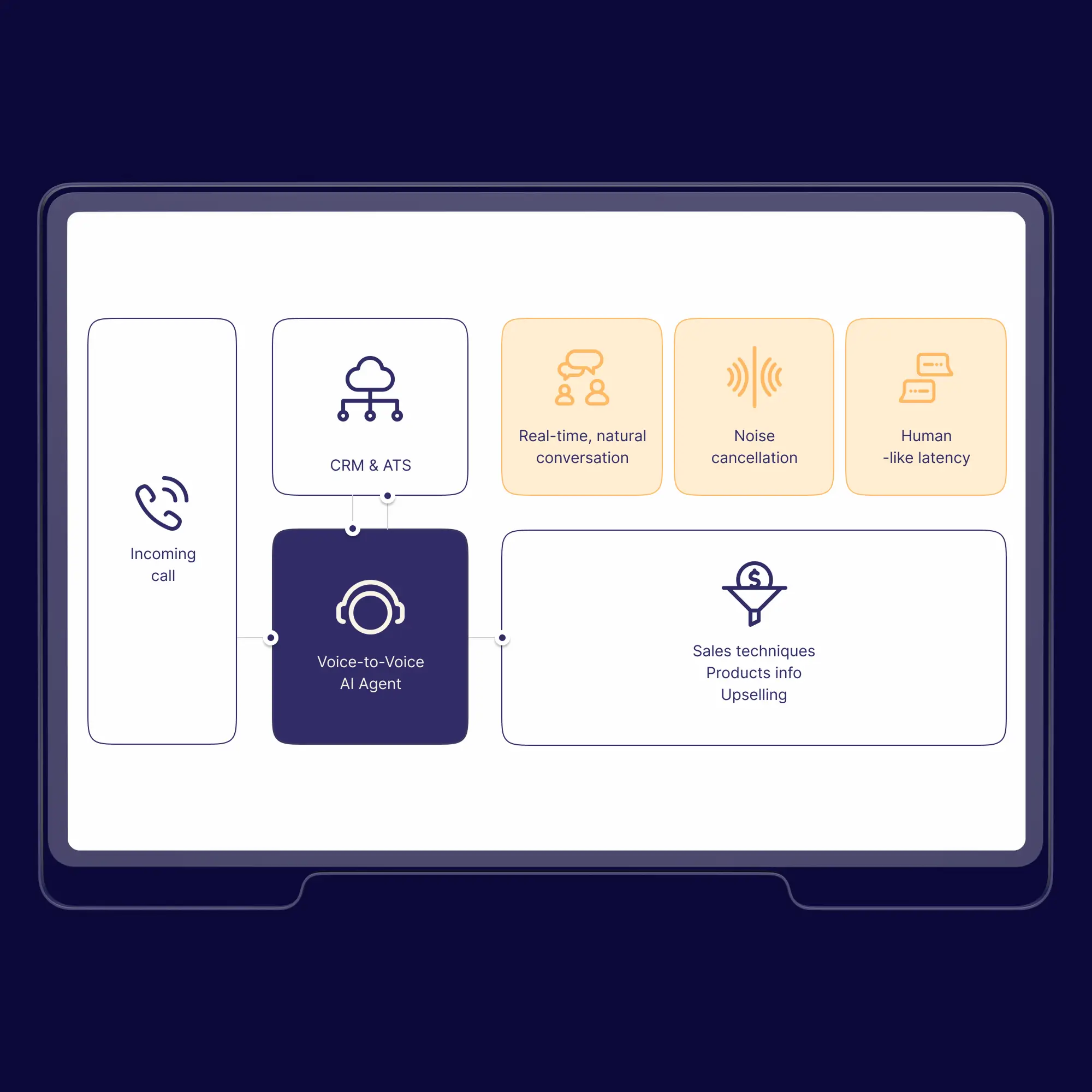

AI-Powered Cold Calling: Real-Time Voice-to-Voice Conversations
What Is the Difference Between Standard and Agentic Artificial Intelligence?
Standard software reads static documents and answers basic questions. Autonomous agents write custom code and update live corporate databases. These active systems demand fast cloud servers and a unified data lakehouse for safely scaling agentic AI.
The shift to independent systems
Enterprise software changes from a passive reference tool to active software, an evolution necessary for scaling agentic AI.
- Basic tools search single text files to generate text answers for human users.
↓
- New systems read 10 database tables simultaneously to write daily financial reports.
↓
- Advanced programs contact 5 separate software applications to update active customer profiles.
↓
- Autonomous agents modify production data networks without a direct human prompt.
↓
- The complete system writes 50 lines of custom code to repair a broken cloud server, a prime example of scaling agentic AI.
A comparison of technical infrastructure
Book a call to stay ahead in technology and accelerate digital transformation initiatives, and prepare for scaling agentic AI.
The danger of fragmented databases
Agentic artificial intelligence requires instant access to 10 different corporate systems at once. Traditional chat interfaces read a single text document and stop their work. Autonomous programs try to update customer addresses in the billing software and the shipping database. These separate platforms lock their records in proprietary file formats. The automated agent finds an unknown table structure and halts the transaction. A failed system update corrupts 5,000 active customer profiles in three seconds. Data architects prevent this software failure with a unified data lakehouse, a mandatory foundation for scaling agentic AI.
Why Do Autonomous Agents Require New Data Pipelines?
Autonomous artificial intelligence crashes on old and broken corporate databases. A single software failure costs an enterprise millions of dollars. DATAFOREST architects prevent these expensive errors with Databricks lakehouse platforms, enabling secure environments for scaling agentic AI.
The cost of bad records
Global Logistics Corporation built an autonomous routing agent for regional deliveries. The software read 5,000 daily shipping manifests from an old database with outdated street maps. The autonomous agent dispatched 40 commercial trucks to a closed highway. The stranded fleet stopped local traffic for four hours. The enterprise lost $400,000 in late delivery penalties. The data team deleted the old tables, and they connected the agent to a clean data lakehouse. For example, the new system routed 10,000 trucks with zero errors the next morning, proving the value of scaling agentic AI.
The limits of old data systems
Old corporate networks lock records in separate silos with strict batch processing schedules. Autonomous agents require instant access to 50 active databases for millisecond decisions. The slow legacy pipelines block these rapid requests and crash the automated software loops, serving as a bottleneck to scaling agentic AI.
Choose what is important to you and order a call to discuss scaling agentic AI.
The blueprint for autonomous access
Data pipelines process 50 terabytes of messy text every day. A central data lakehouse sorts these daily files into three specific tiers. The bronze layer stores raw records. The silver layer drops broken files. The gold layer feeds clean numbers to the active software agents, which is essential for scaling agentic AI.
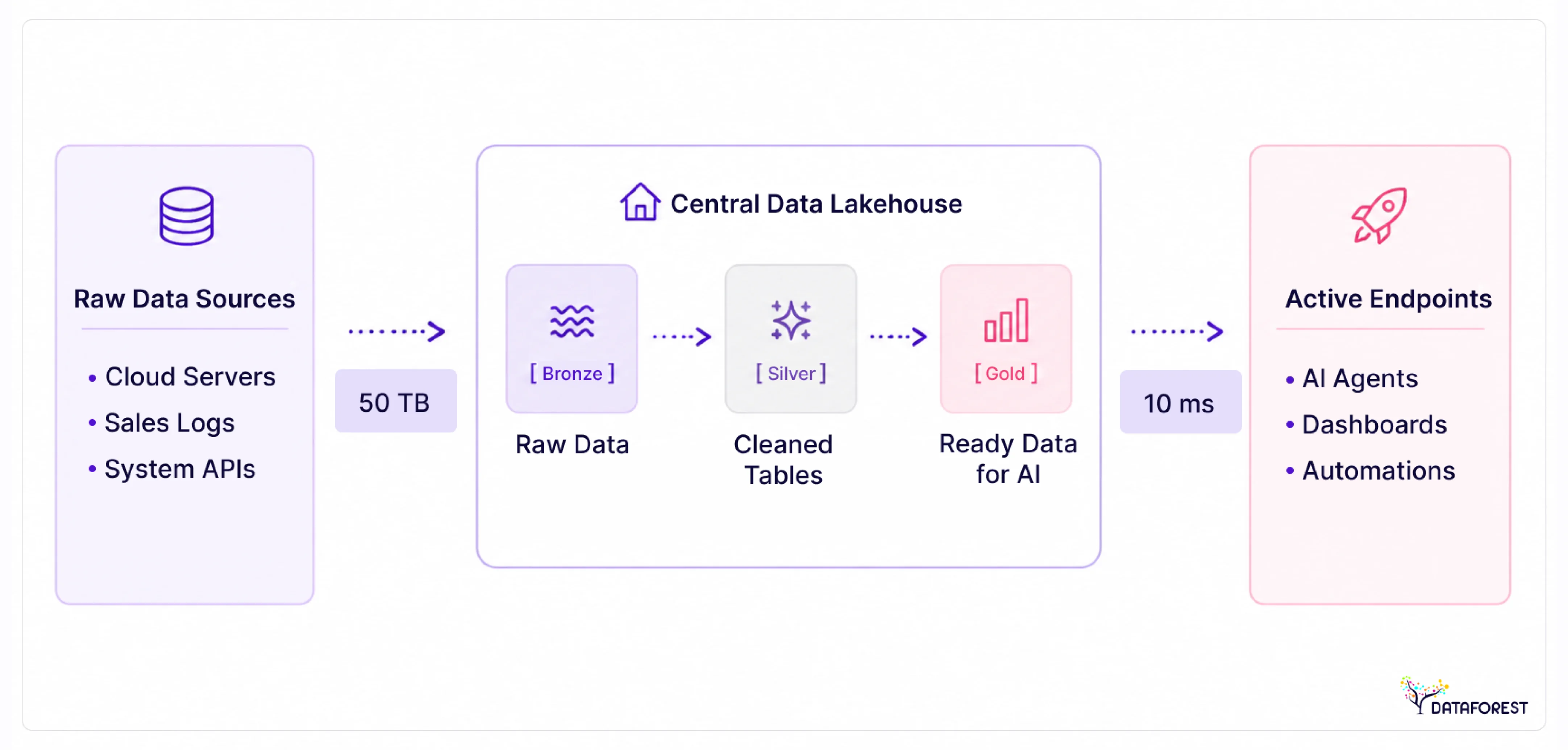
The requirements for system growth
- Store 100 percent of corporate records in a central data lakehouse. This single platform prevents broken file paths when scaling agentic AI.
- Build pipelines for 10,000 new events per second. Autonomous programs fail on delayed batch cycles, requiring a robust real-time data pipeline.
- Write strict data contracts for every database table. A changed column name breaks the software agent.
- Restrict automated software to specific production folders. A single compromised agent corrupts 50 petabytes of corporate text.
- Track every automated database query. Data engineers read these exact system logs. They fix the broken pipeline.
- Separate file storage from cloud servers. Network traffic hits 5,000 requests per minute. Architects add new hardware.
- Filter broken records at the ingestion layer. The data pipeline drops empty files. Clean numbers reach the active software, supporting the framework for scaling agentic AI.

How Do Data Architects Build a Network for Autonomous Agents?
Enterprise software requires a fast and organized network to process petabytes of daily records. Data architects split this massive storage system into distinct technical layers. The blueprint connects scattered corporate files to active artificial intelligence programs, facilitating the process of scaling agentic AI.
The origin of corporate records
The data source layer connects different software applications across the corporate network. Sales departments generate new customer receipts on proprietary billing platforms. Cloud servers log system errors in isolated text files. Autonomous agents require instant access to these scattered files for accurate decisions. Data architects extract this exact information through direct application programming interfaces, a crucial step for scaling agentic AI.
The engine for central storage
The data platform layer organizes petabytes of corporate records in one central location. This system translates incoming files from different software brands into a single standard format. Data architects build these massive storage environments on modern cloud platforms. Autonomous software agents read this clean information to execute 5,000 rapid decisions per minute. A unified structure prevents system crashes and stops expensive automated errors when scaling agentic AI on scalable data platforms.
The translation of raw code
The semantic layer translates technical database columns into plain business terms. Autonomous agents fail to understand obscure labels like 'CUST_ID_99'. Data architects link these exact codes to a central text dictionary. The active software reads this map to calculate accurate monthly revenue. This shared vocabulary prevents artificial intelligence from outputting incorrect financial reports, solving a key challenge in scaling agentic AI and maintaining enterprise data quality.
The packaging of business metrics
The data products layer groups raw tables into fixed business assets. Domain teams publish these specific records on a central Databricks platform. A regional sales department builds a single product to track 10,000 daily transactions. Autonomous agents read this exact file to execute instant pricing updates. This organized structure stops the software from repeating expensive calculations on cloud servers, making scaling agentic AI more cost-effective.
The final connection to business tools
The consumption layer pushes clean numbers directly into active corporate software. Autonomous agents read this exact data to complete automated transactions each hour. Business leaders view the final daily revenue on a single screen. This direct link removes the need for manual reports. Data architects secure these fast pipelines with strict access controls, a vital security measure for scaling agentic AI.
The security rules for corporate records
The governance layer protects petabytes of private company files from unauthorized network access. Data architects assign strict digital locks to sensitive human resources tables. For example, these specific rules stop a broken autonomous program from deleting 10,000 customer profiles. Security servers track every automated database query to trace exact data movement. This constant technical logging blocks external threats and prevents expensive corporate breaches during the phase of scaling agentic AI.
BCG’s 2025 research: effective AI agents can accelerate business processes by 30% to 50%, but only if companies balance autonomy with human oversight and embed controls from day one. BCG also frames the CEO agenda as “now, next, always,” which is a tidy way of saying scale comes from disciplined prioritization, not agent sprawl.
Why Do Artificial Intelligence Agents Need Clean Records?
Old batch pipelines feed corrupted files to the active corporate network. Autonomous artificial intelligence processes 50 petabytes of unformatted text every single day. Data architects stop rapid software crashes with continuous validation rules, an absolute necessity for scaling agentic AI.
The end of batch corrections
Data engineers previously fixed broken database records during a single monthly maintenance window. Autonomous software agents process thousands of live transactions per second. A delayed batch script feeds bad numbers to these active programs. So, data architects add continuous validation tests directly to the data pipeline. A central Databricks lakehouse blocks empty rows and corrupted text files. This active security saves enterprises millions in reversed trades and lost shipments, validating the investment in scaling agentic AI.
The value of text and audio
Past software programs processed neat columns of numbers in rigid tables. Corporate networks now hold petabytes of messy emails, audio calls, and PDF contracts. Modern artificial intelligence agents read these raw text files directly. They extract hidden customer complaints from 10,000 daily support transcripts. Data architects must organize this massive volume of text on a central Databricks platform. Clean text pipelines help executives find money in missed sales opportunities and streamline scaling agentic AI through better unstructured data management.
The map of corporate information
Business leaders need proof for every automated decision on the corporate network. Autonomous agents process legal contracts each hour. Data architects build strict tracking systems to record the exact origin of this text. These lineage logs map the entire path from a raw billing file to a final dashboard. A broken pipeline generates incorrect financial totals. Engineers read the technical metadata to find the exact software error in five minutes, maintaining stability while scaling agentic AI.
The control of machine output
Autonomous software programs create millions of new database records every day. These active agents write transaction logs, calculation steps, and customer messages directly to the main network. This fast machine output pollutes the corporate pipeline with unverified text. Data architects isolate these specific files in a secure folder. They apply strict validation rules to check the automated work for obvious math errors. Clean machine records help engineers build faster algorithms and prevent future network crashes, clearing the path for scaling agentic AI.
Why Do Enterprise AI Agents Fail?
Broken autonomous agents cost technology companies millions of dollars every year. Reckless executives launch these untested programs across entire corporate departments. Smart data architects build a single reliable agent for one specific task before attempting to scale agentic AI.
The problem with total replacements
❌Incorrect: Chief technology officers replace entire customer service departments with artificial intelligence software on a single Monday. The engineering teams connect these new AI agents directly to primary payment databases. Then the broken system blocks ten thousand daily user transactions during the first hour of operation.
✅Correct: Smart technology leaders pick a single internal process like password resets for their first project. A test group of fifty employees measures the success rate of this agent over two weeks. Then the engineering team expands the fixed software to other small tasks, successfully scaling agentic AI.
The choice of target processes
❌Incorrect: Executives force autonomous agents into creative departments like product design. These unguided programs guess subjective details about brand colors and market appeal. Then the managers spend 40 hours on manual corrections every week.
✅Correct: Data architects target repetitive corporate jobs with strict mathematical rules as a baseline for scaling agentic AI. They assign a new agent to sort 5,000 vendor invoices every Friday. The software finishes this predictable accounting task in 10 minutes.
The selection of early agent projects
❌Incorrect: Technology executives place autonomous agents on the main customer phone line. These programs misinterpret the loud voices of 200 callers in a single morning. Then the angry buyers cancel their annual software contracts.
✅Correct: Smart leaders assign new agents to internal technical support tickets. The software sorts 500 employee hardware requests into the correct database tables. The data architects check these daily logs to calculate the exact cost reduction before scaling agentic AI and expanding enterprise AI agents.
The value of shared components
❌Incorrect: Engineering teams write completely new code for every single autonomous agent in the company. These isolated programs share zero internal parts across the 5 corporate divisions. The chief technology officer wastes 500,000 dollars on duplicate engineering by the end of December.
✅Correct: Smart data architects build a central library of core data tools. They connect this exact base code to both vendor contracts and internal employee records. The engineering department launches 20 enterprise agents across the organization in just 3 months, showcasing efficient scaling of agentic AI using a unified agentic AI architecture.
How Do You Prepare Enterprise Architecture for Autonomous Agents?
Thousands of chief technology officers are rushing to deploy autonomous agents this year. But these new independent programs crash existing data pipelines and expose restricted corporate files. Data architects update their current infrastructure and skip the expensive system rebuild, optimizing for scaling agentic AI by creating an AI-ready data architecture.
The value of the current infrastructure
Complete database replacements halt daily corporate operations for 24 months. Data architects connect autonomous agents to the existing Snowflake data warehouse. The engineering team builds a new semantic layer over the medallion architecture. These programs read 50 terabytes of historical company records. The business saves 4 million dollars on fresh server hardware while scaling agentic AI and solidifying its enterprise data architecture.
The growth of connected agent networks
Autonomous agents from different software vendors now talk to each other. A Databricks agent reads a customer file and hands the records to a Microsoft sales agent. Your data architects link these tools through standard application programming interfaces. Then the connected group processes 10,000 daily transactions across 3 cloud providers. The chief information officer avoids vendor restrictions and saves 2 million dollars by December through successfully scaling agentic AI.
The need for strict agent permissions
Autonomous agents request access to restricted corporate databases. An unchecked agent emails the salaries of 50 executives to the entire company. Your data architects prevent this financial disaster with strict identity rules. They give the software exact read permissions for 3 specific Snowflake tables. The chief information officer protects 10 terabytes of sensitive business data, establishing the trust needed for scaling agentic AI.
The need for clear system logs
Autonomous agents hide their mistakes and cost companies millions of dollars. A broken financial program buys 50,000 bad shares and generates zero warning messages. Data architects fix this problem with clear system logs. The tracking software records every single agent decision into a secure Databricks lakehouse. The engineering department reads these 500 daily records to stop bad transactions, allowing for secure scaling of agentic AI.
Bain’s 2025 report says the market is moving from pilots to profits. Its benchmark finding is that AI leaders have already delivered 10% to 25% EBITDA gains by scaling AI across core workflows, and agentic AI now requires more infrastructure for agents to communicate across silos. Bain’s guidance is blunt: build guardrails early, focus on a few domains first, and use fit-for-purpose, human-in-the-loop builds when scaling agentic AI.
How to Govern Enterprise AI Agents?
Strict system governance: Ten independent agents crash primary corporate servers in just five minutes. Chief technology officers stop this financial damage with a central governance operating system. The control software tracks daily agent actions and blocks restricted database queries, establishing baseline AI governance.
Clear control rules: Engineering teams define exact rules before they launch any autonomous program. Then, data architects lock specific Snowflake tables to block unapproved reads. This central system protects millions of customer files from accidental deletions.
System guard agents: Data architects build watchdog agents to supervise the rest of the autonomous network. This security software blocks dangerous Snowflake queries from other active agents. So, the chief technology officer protects terabytes of sensitive financial records.
Agent lifecycle control: Data architects track autonomous agents from their initial deployment to their final deletion. The control platform shuts down outdated programs after 90 days of activity. This hard limit saves the company millions in cloud computing bills.
Distributed agent control: A central technology committee delays the launch of new autonomous programs. Data architects distribute strict security rules across a decentralized data mesh. Then local managers deploy approved Databricks agents for their own teams.

How Does Your Organization Scale AI Agents?
Autonomous agents require a total change to your internal corporate structure. You must bridge the gap between engineering, legal, and operational teams to achieve success.
The new operating model
Traditional business departments block autonomous agents with old approval rules. Your chief technology officer groups different workers to fix this delay. For example, these teams mix three data architects and two legal experts. Then the group deploys 50 Databricks agents in four weeks, proving the effectiveness of the new AI operating model.
New roles for employees
Corporate workers abandon their manual reporting tasks. These experienced employees review tens of complex exceptions from the new autonomous software. Your data architects write strict mathematical boundaries for the active Databricks agents. Then a small human team safely guides 500 digital workers to process more transactions as part of the company's enterprise AI automation.
Shared team goals
Isolated departments block autonomous agents from accessing vital customer records. Your chief technology officer mandates weekly meetings between data architects and legal teams. These groups define common security protocols for all new software projects. The company launches productive agents across multiple divisions in two months, advancing its enterprise agentic AI initiatives.
New technical skills
Engineers learn to write precise instructions for autonomous software instead of basic code. Data architects master the management of complex vector databases and agent pipelines. Employees study how to detect errors in high-speed automated reports. Your firm hires internal experts to guide this workforce shift before the end of the year.
How Do Top Enterprises Succeed with AI Agents?
- Top executives build a central Databricks lakehouse as permanent corporate infrastructure. This base system feeds terabytes of daily records to all active software programs, acting as a strong data foundation for AI.
- Technology leaders ignore the latest software trends and redesign their core business operations around a strict medallion architecture. This structured data flow allows active agents to process daily vendor invoices without human delays, showcasing seamless business process automation.
- Data architects embed strict security protocols directly into a new data mesh on the first day. This central control system blocks unapproved agents from reading terabytes of sensitive cloud storage, ensuring AI compliance.
- Top data architects build a central library of core Databricks tools. The engineering department uses this exact code to launch forty new agents in three months, accelerating AI agent deployment.
- Engineering teams monitor the exact computing cost of every cloud migration agent. Data architects read these daily performance logs to stop expensive software errors within the AI agent infrastructure.
How Can DATAFOREST Help You Scale Enterprise AI Agents?
The DATAFOREST team assesses your current infrastructure to design a scalable foundation for autonomous programs. We build a secure Databricks lakehouse to feed high-quality records directly to your active software. Our data architects implement a strict medallion architecture that organizes your raw information into clean business data. We establish a decentralized data mesh that safely distributes access across your entire enterprise without compromising security. Our engineering department writes strict governance protocols to monitor agent activity and prevent expensive automated errors. This complete architectural transformation allows your company to confidently deploy hundreds of autonomous agents across multiple cloud environments, achieving a robust enterprise AI transformation.
Please complete the form to start scaling your autonomous agents today and optimizing your AI data infrastructure.
Questions on Scaling Agentic AI
What prevents most enterprises from successfully scaling AI agents?
Flawed system integration and fragmented legacy data trap most autonomous programs in the experimental pilot phase. Without strict central governance, unregulated agents drain cloud computing budgets through infinite processing loops and expose restricted corporate files. To successfully scale beyond a few isolated tests, organizations must build a unified data architecture and enforce precise operational boundaries for their autonomous AI systems.
How can technology partners help enterprises accelerate AI agent adoption and scaling?
Technology partners accelerate adoption by building secure Databricks lakehouses and implementing strict medallion architectures to organize raw corporate data. Expert data architects embed central governance protocols directly into a decentralized data mesh to control agent access safely. This unified technical foundation allows companies to bypass isolated pilot programs and confidently scale hundreds of autonomous software agents through a mature AI transformation strategy.
Which business workflows are best suited for AI agent automation?
The best workflows for AI agent automation involve high-volume, structured data processing with precise decision rules. Excellent candidates include automated vendor invoice approvals, cloud infrastructure cost monitoring, and real-time anomaly detection within a lakehouse. By targeting these predictable operations, autonomous programs minimize expensive cloud compute errors and operate safely under strict central governance, perfecting your AI agent workflows.
Should enterprises build single-agent or multi-agent AI systems?
Enterprises must build multi-agent systems to manage complex business operations across decentralized data environments. Specialized agents divide workloads into focused tasks, allowing data architects to enforce strict governance boundaries on each independent program. This distributed network processes massive workloads far more securely and efficiently than a single monolithic application, demonstrating advanced AI agent orchestration.
How can enterprises ensure compliance and auditability in agentic AI systems?
Data architects must embed comprehensive logging mechanisms within the core operating system to record every autonomous action. By deploying strict governance protocols across a decentralized data mesh, engineering teams can instantly block unauthorized database queries. This continuous surveillance creates an immutable audit trail that proves regulatory compliance and protects sensitive corporate records under a comprehensive framework for agentic AI governance.

.svg)
.webp)







