

A financial services firm spent $8 million on a modern cloud data platform. The engineers delivered on time. The technology worked exactly as designed. Three months after launch, the platform sat unused—no one had trained the teams, redefined data ownership, or connected the migration to business outcomes that stakeholders actually cared about.
That story isn't unusual. According to Gartner and BCG (2024–2025), roughly 70% of digital transformation initiatives—data architecture modernization included—fail to meet their original objectives. And yet every piece of content on this topic reads like a vendor brochure: pick a pattern, deploy to the cloud, watch your organization transform.
This guide doesn't do that. It treats data architecture modernization as what it actually is: a complex organizational and technical decision with real costs, real failure modes, and real prerequisites. Whether you're a CDO building a business case, an enterprise architect comparing mesh against lakehouse, or a VP of data engineering trying to migrate off a 12-year-old warehouse without losing your job, you'll find what you need here.
Specifically, you'll learn how to choose the right architecture pattern for your organization's actual constraints, how to build a realistic 12-month migration roadmap with budget ranges and rollback criteria, and how to score your organization's readiness before committing a dollar to modernization.
Key takeaways
- According to Market Reports World (2025), 69% of U.S. organizations run data warehouses older than eight years—but age alone isn't a reason to modernize; readiness is.
- Data architecture modernization fails not because of technology but because of people, planning, and premature execution; organizations in the 30% who succeed have a clearer decision framework, not better engineers.
- Capgemini (2025) reports TCO reductions of 20–50% after successful modernization, but projects that skip organizational alignment rarely reach those numbers.
- No single architecture pattern—mesh, fabric, or lakehouse—is universally correct; the right choice depends on data ownership structure, team size, and compliance requirements, not technology preference.
- Modernization is the wrong move for organizations with data volumes under 1TB, no AI/ML ambitions, or teams currently mid-ERP-migration—and this guide tells you exactly what to do instead.
Why 70% of data architecture modernization projects fail
Most data architecture modernization failures are organizational, not technical. The cloud infrastructure works. The lakehouse gets deployed. The data mesh gets designed. And then nothing moves because nobody agrees on who owns what, what "done" looks like, or how success gets measured.
Data modernization programs follow the same pattern. The root causes cluster into a predictable set: unclear ownership, absent governance frameworks, insufficient change management, and modernization that starts before the organization is ready for it.
Data architecture modernization fails not because of technology - it fails because of people, planning, and premature execution. The organizations in the 30% who succeed don't have better engineers; they have a clearer decision framework before they write a single line of infrastructure code.
Data Modernization Readiness Checklist
- Ownership is clear
- A governance framework exists
- Change management is sufficient
- The organization is ready for modernization
- People's risks are addressed
- Planning is complete
- Execution is not premature
- A clear decision framework is defined before the infrastructure code begins
- Success criteria are set before implementation starts
The technology-versus-people gap
When a modernization project fails, the post-mortem almost always points to the same culprits. Teams weren't trained on the new platform. Data ownership wasn't redefined when the architecture changed. Governance policies were designed for the old system and never updated. Business stakeholders didn't understand what they were getting, so they kept using the legacy system in parallel.
According to MuleSoft (2025), only 28% of enterprise applications are currently connected, and 95% of IT leaders say integration issues directly impede their AI adoption plans. That gap isn't a data engineering problem—it's an organizational one. Modern architecture can't fix it if the people strategy isn't built alongside the technical strategy.
The 5 warning signs your current architecture is failing
Not every legacy system needs immediate replacement. These signals indicate genuine, near-term risk:
- Query performance has degraded to the point where reports that once took minutes now take hours, and the engineering team's primary job is patching rather than building.
- Your data warehouse is more than 8 years old—a threshold that correlates with the inability to support modern AI and ML workloads, per Market Reports World (2025).
- Your team spends more than 40% of its time on data integration rather than analytics or product work.
- AI/ML initiatives are stalled because the data layer can't support feature stores, real-time inference, or vector retrieval.
- Data silos have multiplied to the point where answering a single business question requires manual consolidation across four or more systems.
If three or more of these apply, modernization is probably warranted. If fewer than two apply, read the "when NOT to modernize" section before making any investment decisions.
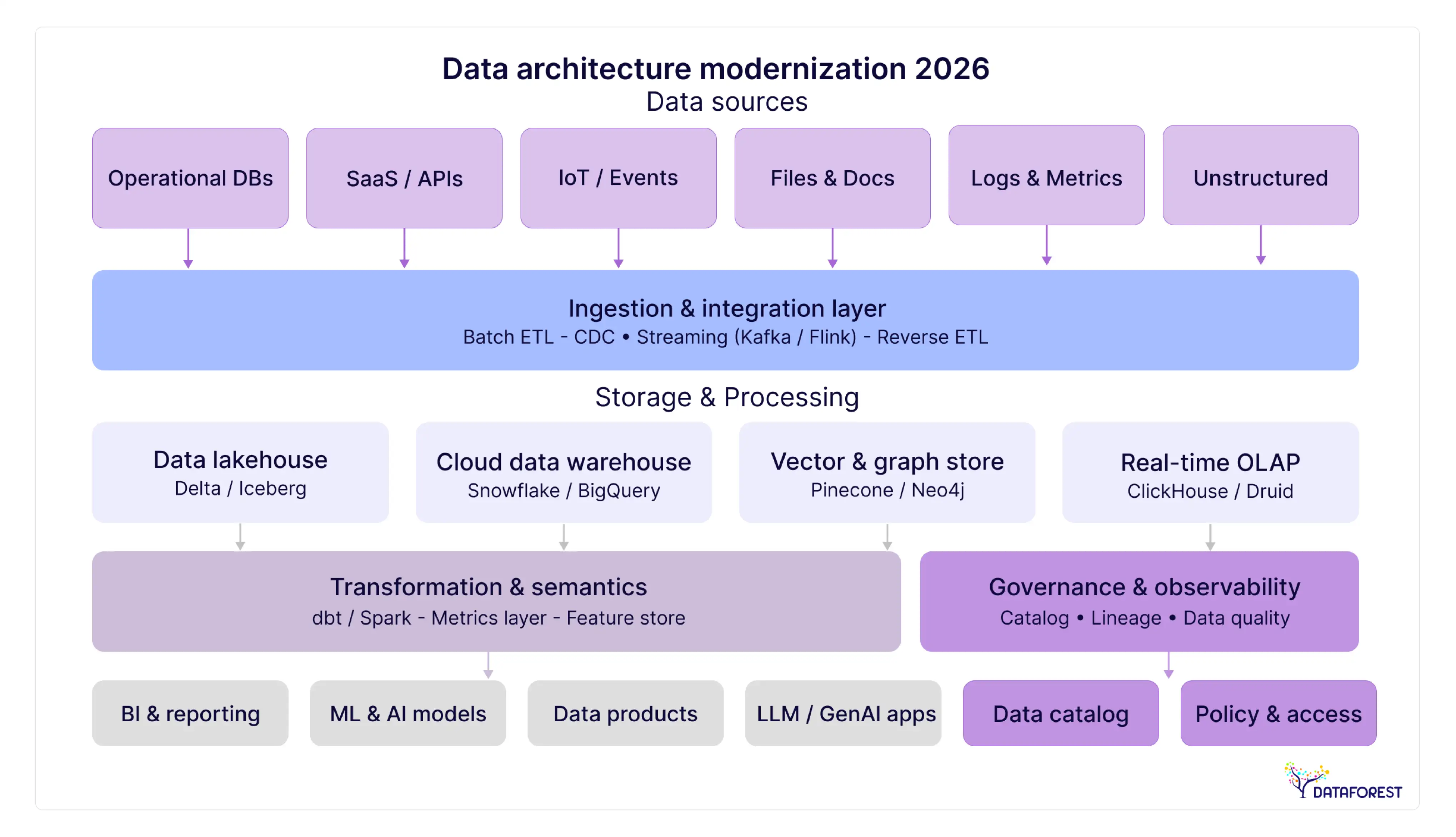
Modern data architecture patterns compared
Every organization modernizing its data architecture eventually hits the same fork: Data Mesh, Data Fabric, or Data Lakehouse? Articles in this space typically offer a qualitative comparison table and call it done. What's missing is the quantified picture - cost ranges, team size requirements, typical implementation timelines, and the specific conditions under which each pattern fails.
The table below provides that picture.
Architecture pattern comparison matrix
Data warehouses deliver reliable, governed analytics through structured schemas, but they slow down when change velocity increases. Data lakes provide flexible, low-cost storage for diverse data and AI pipelines, yet often fail without strong governance and ownership, leading to data swamps. Data lakehouses combine both models into a unified platform, but require clear decision frameworks, mature teams, and disciplined execution to avoid complexity and premature failure.
Data mesh—when distributed ownership works (and when it doesn't)
Data Mesh treats data as a product owned by the domain team that produces it. A marketing team owns its customer engagement data. A logistics team owns its shipment data. Each domain publishes data products that other teams can consume through a self-serve platform.
This works when the organization already has strong, autonomous engineering teams in each business domain, when organizational boundaries rather than technical limitations drive data silos, and when there are enough engineers per domain to maintain both the data products and the governance policies.
It fails when those conditions don't exist. Introducing data mesh into an organization where domain teams lack engineering maturity creates accountability without capability. The result is often worse than the original silo problem because now there's governance overhead with no one to enforce it.
Organizations that successfully implement data mesh typically have 20 or more data engineers distributed across domain teams before beginning the mesh transition—not as a result of it.
Data fabric—the metadata-first approach for complex environments
Data Fabric is the right pattern when the problem isn't ownership but connectivity. Multi-cloud environments, hybrid on-prem/cloud setups, and legacy systems that can't be migrated cleanly are the primary use cases. The fabric uses an intelligent metadata layer to create a unified view of data across disparate systems without requiring those systems to be moved or restructured.
The primary risk with data fabric is that the metadata strategy has to be designed before deployment, not after. Organizations that treat metadata as something they'll figure out later tend to find the fabric becomes a new bottleneck: a unified interface sitting on top of a disorganized mess.
Data fabric is particularly well-suited to financial services organizations with complex regulatory requirements and decades of legacy systems, where ripping and replacing infrastructure isn't realistic.
Data lakehouse—unified storage for analytics and AI workloads
The Data Lakehouse merges the low-cost storage flexibility of a data lake with the structured query performance of a traditional data warehouse. It's the most accessible of the three patterns for mid-market organizations and the most directly applicable to AI/ML use cases.
The medallion architecture—organizing data into raw (bronze), transformed (silver), and curated (gold) zones—is the standard implementation pattern within a lakehouse. Raw ingested data lands in bronze. Cleaned, joined data moves to silver. Business-ready, governed data lives in gold. Tools like dbt handle the transformations; Snowflake, Databricks, or Apache Iceberg manage the storage layer.
The main failure mode is storage cost. Organizations that don't implement tiered storage policies and data lifecycle management often find cloud storage costs exceeding projections at scale. Budget for this upfront.
Choosing your pattern—a 4-factor decision framework
Run through these four questions before committing to a pattern:
- Domain autonomy: Do your business domains have 3+ dedicated data engineers? If yes, mesh is viable. If no, default to lakehouse or fabric.
- Integration complexity: Are you managing 5+ data sources across cloud and on-prem? If yes, the fabric's metadata layer is probably worth the investment. If not, the lakehouse is simpler.
- AI/ML roadmap: Do you have active AI/ML projects planned in the next 18 months? If yes, Lakehouse's native support for vector stores and feature stores gives it a clear advantage.
- Compliance concentration: Are most of your compliance obligations concentrated under one main regulation, or distributed across multiple frameworks and geographies? Distributed compliance favors fabric's centralized policy automation.
Most mid-market organizations land on Lakehouse. Most large, domain-mature enterprises eventually move toward mesh, often via lakehouse first. Fabric tends to be the pattern for complex legacy environments where a full modernization isn't immediately feasible. However, determining the optimal starting point requires a deep audit of your current data debt. Professional data architecture services can help bridge the gap between selecting a theoretical pattern and deploying a production-ready environment that actually scales.

The hidden cost of doing nothing—ROI and TCO framework for modernization
According to Gartner (2025), organizations lose between $9.7 million and $15 million annually from poor data quality alone. That's not the cost of the legacy system - that's just the quality debt it accumulates. Add the maintenance and licensing costs of on-premises infrastructure, the engineering hours spent on integration patches, and the opportunity cost of AI initiatives that can't launch without a modern data layer, and the total gets substantially larger.
Market Reports World (2025) found that organizations successfully modernizing their data architecture achieve 42–49% improvements in query performance and reduce data duplication by 35–40%. At scale, these gains translate directly into analyst productivity, faster product decisions, and reduced storage costs.
The real TCO calculation needs to account for four cost categories that most business cases ignore: data quality costs (the $9.7–15M annual figure above), maintenance overhead (typically 60–70% of a legacy infrastructure budget goes to keeping the lights on rather than building new capability), the cost of deferred AI adoption, and the risk premium from operating a system that can't meet modern compliance requirements.
Modernization investment benchmarks by company size
These ranges come from Capgemini (2025) and Valorem Reply (2026) implementation benchmarks. They're starting points for business case scoping, not fixed quotes.
Capgemini (2025) reports that organizations using a hybrid approach - typically a lakehouse foundation with fabric-style metadata governance - achieve 30–40% cost reductions over 18–24 months. The qualifier: that outcome requires the organizational alignment components described later in this guide. Projects that skip change management rarely reach the lower end of those ranges.
Data architecture modernization roadmap—a 12-month implementation plan
Phase 1 (months 1–3): Assessment and architecture selection
Budget allocation: 10–15% of total project budget.
Key activities:
- Audit current data estate: systems, volumes, ownership, quality scores
- Run the 4-factor architecture decision framework (domain autonomy, integration complexity, AI roadmap, compliance)
- Score organizational readiness using the scorecard in the organizational section below
- Define data domains and owners (for mesh) or metadata taxonomy (for fabric/lakehouse)
- Issue RFPs to 3–5 vendors; evaluate against the 6-dimension scorecard
Success metrics: Architecture pattern selected with documented rationale; organizational readiness score of 60 or above; data domain owners identified and committed.
Rollback criteria: If organizational readiness scores are below 40, pause the project and address people's prerequisites first. Starting below 40 correlates strongly with the 70% failure group.
Phase 2 (months 4–6): Foundation and pilot migration
Budget allocation: 25–30% of the total project budget.
Key activities:
- Deploy cloud storage layer (Snowflake, Databricks, or cloud-native equivalent)
- Migrate one high-value, low-complexity domain or data product as a proof of concept
- Configure orchestration tooling (Apache Airflow, Dagster, or Prefect)
- Establish a data catalog with initial metadata for migrated assets
- Run parallel operations - the legacy system stays live until the pilot is validated
Success metrics: Pilot domain query performance meets or exceeds baseline; data quality scores maintain or improve; zero data loss during migration.
Rollback criteria: If the pilot migration reveals data quality issues affecting more than 10% of records, pause and remediate before expanding the scope.
Phase 3 (months 7–9): Incremental migration and governance
Budget allocation: 35–40% of the total project budget.
Key activities:
- Apply the 70/20/10 migration rule: lift-and-shift 70% of workloads, re-platform 20%, re-architect 10%
- Use the strangler fig pattern for critical production systems (see migration strategies section)
- Launch the training program for data consumers and domain owners
- Activate data quality monitoring across migrated assets
- Begin legacy system decommissioning for fully migrated domains
Success metrics: Training completion rate at 80%+ of targeted users; migrated workloads passing data quality thresholds; legacy system utilization declining as teams adopt the new platform.
Rollback criteria: If business unit adoption falls below 60% after training, escalate to the executive sponsor before proceeding with additional migrations.
Phase 4 (months 10–12): Scale and optimize
Budget allocation: 20–25% of the total project budget.
Key activities:
- Complete remaining migrations
- Implement storage optimization and tiering policies (critical for lakehouse cost management)
- Conduct a full data quality audit
- Document lessons learned and publish architecture decision records
- Establish ongoing governance cadence: data quality reviews, schema evolution process, access audits
Success metrics: TCO reduction tracking toward 20–50% target by month 18–24; user adoption at 85% or higher; legacy system fully decommissioned.
Migration strategies for legacy data architecture - choosing your path
There are three migration paths, and the right mix depends on the nature of each workload - not a single organization-wide decision.
The 70/20/10 migration rule
Valorem Reply (2026) recommends thinking about workloads in three buckets:
Lift-and-shift (70% of workloads): Move the workload to the new infrastructure without redesigning it. Same logic, same structure, new platform. This is faster, lower risk, and appropriate for workloads where the existing design is sound. The cost is that you carry some legacy design debt into the new environment—acceptable for most operational reporting and historical analytics.
Re-platform (20% of workloads): Move and modernize. Keep the business logic but re-implement it using modern tooling. ETL jobs become ELT. Stored procedures become dbt models. This is where most of the engineering investment concentrates.
Re-architect (10% of workloads): Redesign from scratch. Reserve this for workloads where the original design was fundamentally wrong for current use cases—typically real-time streaming requirements where the original was batch-only, or AI/ML pipelines where the original was designed for reporting.
Organizations that try to re-architect everything fail. The complexity and scope expand beyond what teams can manage. The 70/20/10 rule keeps scope realistic and delivers early wins that build organizational confidence.
The strangler fig pattern for zero-downtime migration
For production systems that can't afford downtime, the strangler fig pattern is the standard approach. The idea: build the new system alongside the old one, route new traffic incrementally to the new system, and allow the old system to "strangle" as its traffic load decreases until it can be safely decommissioned.
In practice:
- New data ingestion routes through the modern stack from day one
- Historical data migrates in background batches during off-peak hours
- The legacy system remains live and queryable throughout
- Switchover happens domain by domain, not as a big-bang cutover
- Rollback is always available until the legacy system is formally decommissioned
The strangler fig approach adds 20–30% to the migration timeline compared to a big-bang cutover, but reduces risk substantially. For organizations with regulatory reporting requirements or SLA-bound data products, it's almost always the right approach.
Migration decision tree
Industry-specific data architecture modernization playbooks
A CTO at a mid-size hospital system faces completely different modernization constraints than one at a fintech. The former can't store PHI in a public cloud region without specific BAA agreements and encryption configurations. The latter can't separate transaction data from fraud analytics without violating real-time SLA requirements. Generic modernization advice misses the specifics that matter.
What follows are condensed playbooks for four verticals, each mapping common regulatory requirements to architecture patterns.
Healthcare—HIPAA-compliant architecture modernization
Primary constraints: HIPAA requires strict access controls, audit logging, data residency options, and breach notification readiness. BAA agreements are mandatory with cloud vendors.
Recommended pattern: Data Lakehouse with centralized access governance, or Data Fabric for organizations with five or more existing EHR/EMR systems that can't be consolidated.
Architecture decisions that differ from standard modernization:
- Column-level encryption is non-negotiable; configure at the storage layer before migrating any PHI
- Audit logging must capture all data access, not just modifications - this rules out certain cost-optimized storage tiers
- De-identification pipelines need to be designed before data product pipelines, not as an afterthought
- Cloud region selection must account for data residency requirements for HIPAA-covered entities
A regional health system with 12 hospitals migrated from a siloed EHR data warehouse to a HIPAA-compliant lakehouse using a re-platform approach. The primary outcome: unified patient analytics across sites without PHI leaving approved cloud regions, with audit logging that satisfied compliance requirements. Timeline: 14 months.
Financial services—SOX/PCI-DSS architecture patterns
Primary constraints: SOX requires immutable audit trails and segregation of duties in data pipelines. PCI-DSS requires cardholder data isolation and access minimization. Both demand that architecture changes don't crяeate new control gaps.
Recommended pattern: Data Fabric for large institutions with complex legacy trading and risk systems; Data Lakehouse for fintechs and mid-market financial services with more modern starting points.
Architecture decisions that differ:
- Immutability is a design requirement: choose storage formats (Apache Iceberg, Delta Lake) that support time-travel and append-only tables
- Lineage tracking must cover transformations, not just sources - dbt's built-in lineage matters here
- Cardholder data environments need isolation at the network and storage layer, not just the application layer
- DataOps/CI-CD practices around pipeline code are a SOX control, not a preference
A mid-size asset management firm migrated its risk reporting infrastructure from an on-premises Oracle data warehouse to a lakehouse architecture, using the strangler fig pattern to maintain daily risk report SLAs throughout. Query performance improved by approximately 45%, and the team reduced maintenance overhead from 65% of engineering hours to roughly 30% within 18 months.
Retail—real-time personalization architecture
Primary constraints: Retail modernization is almost always driven by real-time requirements—personalization, inventory visibility, fraud detection. The gap between batch-oriented legacy systems and real-time event pipelines is typically the largest technical challenge.
Recommended pattern: Data Lakehouse for the analytical layer, with a separate real-time streaming layer using Apache Kafka and Apache Flink for event processing. The medallion architecture handles historical analytics while the streaming layer feeds recommendation and personalization systems.
Architecture decisions that differ:
- Lambda vs. Kappa architecture: for most retail personalization, a Kappa approach (streaming-only with reprocessing capability) is simpler to operate than maintaining separate batch and streaming paths
- Data freshness SLAs need to be explicit before architecture selection - "near-real-time" means different things to different teams
- Customer data platforms typically sit on top of the lakehouse rather than replacing it; plan integration points upfront
Manufacturing—IoT and edge data architecture
Primary constraints: Manufacturing generates enormous volumes of sensor data at the edge. The architecture has to handle ingestion at scale while keeping operational technology (OT) systems isolated from IT systems for security.
Recommended pattern: Hybrid architecture with edge processing (reduce data at source), streaming ingestion, and a lakehouse for analytics.
Architecture decisions that differ:
- OT/IT convergence is a security design problem first and a data architecture problem second—involve OT security before designing data pipelines that touch production systems
- Data volumes from sensors often make cloud-first approaches cost-prohibitive; edge preprocessing that reduces volume by 80–90% before cloud ingestion is standard practice
- Equipment manufacturer proprietary protocols often require custom connectors; budget for integration engineering time that generic architecture guides don't account for
The organizational side of modernization—why teams make or break the project
Data architecture modernization fails not because of technology—it fails because of people, planning, and premature execution. The organizations in the 30% who succeed don't have better engineers; they have a clearer decision framework, and they do the organizational work before the infrastructure work.
RACI framework for data ownership in modernization programs
One of the most common failure modes—in data mesh implementations and in any modernization that redistributes data ownership—is ambiguity about who is responsible for what. This RACI structure is a starting template; adjust it to your organizational structure.
A = Accountable, R = Responsible, C = Consulted, I = Informed
The most important cell in this table is the Domain Data Owner row. If that person hasn't been identified, trained, and given enough capacity in their schedule to actually perform the role, the modernization will produce a technically correct architecture that nobody trusts because quality ownership is unclear.
Modernization readiness scorecard—score your organization before investing
Score each dimension 1–5. A total below 30 means organizational prerequisites need attention before modernization begins. A score of 30–45 means proceeding with a phased approach, addressing the lowest-scoring areas first. Above 45, full modernization is appropriate.
If you score below 30, that's not a reason to abandon modernization—it's a signal about where to invest first. Organizations that jump to architecture selection without addressing governance maturity and ownership clarity tend to build expensive infrastructure that produces the same low-quality, untrusted data as the system they replaced.
When NOT to modernize your data architecture
Data architecture modernization is the wrong move—or at least the wrong move right now—under the following five conditions:
Your data volume is under 1TB. A modern lakehouse or data fabric is designed to solve problems that don't exist at this scale. A well-structured relational database with good indexing handles 1TB of analytics data without the operational complexity of a distributed architecture. The cost of modernization would exceed any benefit.
You have no AI/ML ambitions in the next three years. The strongest business case for modernization is enabling AI workloads. If there's no roadmap for machine learning or advanced analytics, the ROI calculation changes significantly. Incremental improvements to your existing stack may deliver more value per dollar spent.
You're mid-ERP migration. Running two major infrastructure transitions simultaneously multiplies risk. ERP migrations absorb enormous amounts of engineering and change management capacity. Starting data architecture modernization while an ERP migration is in flight almost always means one of them gets deprioritized—and data usually loses.
Your regulatory environment requires on-premises infrastructure. Some defense, government, and financial services contexts have data sovereignty requirements that make public cloud modernization architecturally impossible until those requirements change.
Your organization scored below 30 on the readiness scorecard. If governance is absent, ownership is unclear, and executive sponsorship is thin, even the best-designed architecture will fail. The right investment is organizational capability-building, not infrastructure.
In these situations, practical alternatives include: incremental optimization of the existing stack, targeted investments in data quality tooling, or a limited proof-of-concept that builds organizational readiness for a full modernization 12–18 months from now.

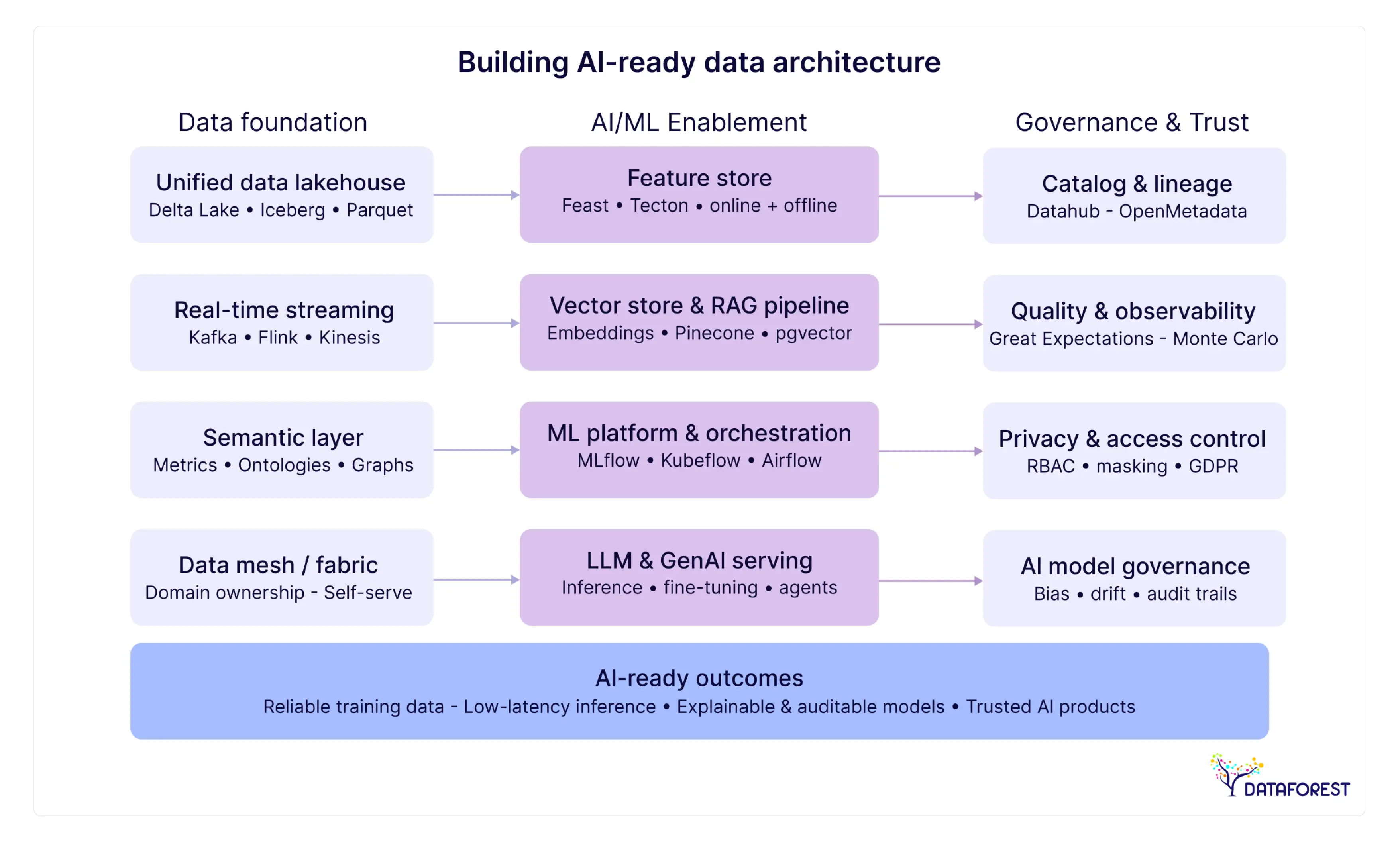
Building AI-ready data architecture—what "AI-readiness" actually means architecturally
Claiming an architecture is "AI-ready" without specifying the components is like claiming a building is "production-ready" without specifying electrical capacity or load-bearing specifications.
Here's what AI-readiness actually requires.
Vector databases and RAG pipelines
Retrieval-Augmented Generation (RAG) is currently the dominant pattern for enterprise AI applications that need to query organizational knowledge—product documentation, customer history, internal policies. RAG requires a vector database: a storage layer optimized for similarity search on high-dimensional embeddings.
Your data architecture needs to account for this. The AI-ready lakehouse integrates a vector store (Pinecone, Weaviate, pgvector within PostgreSQL, or the vector search capabilities built into Databricks and Snowflake) alongside the standard analytical layers. Data pipelines need to include an embedding generation step that converts unstructured text, images, or other content into vectors and keeps them synchronized with source data updates.
The integration point between your data lakehouse and your vector store is an emerging engineering challenge. Budget for it explicitly rather than assuming it's handled by off-the-shelf connectors.
Feature stores and model serving infrastructure
For machine learning applications beyond RAG, the critical infrastructure component is a feature store: a centralized repository of pre-computed features that makes ML model training repeatable and model serving consistent. Without a feature store, teams commonly recompute the same features in multiple places, creating training-serving skew—the phenomenon where a model performs well in training but poorly in production because the data it sees in production differs from what it was trained on.
Feature stores like Feast, Hopsworks, or the managed options in Vertex AI and SageMaker sit on top of your data lakehouse and expose features to both training pipelines and real-time inference endpoints. Designing the feature store layer before you need it—rather than bolting it on after ML teams encounter training-serving skew problems—is one of the clearest signals of architectural maturity.
An AI-ready architecture also needs model versioning (MLflow is standard), a model registry, and a monitoring layer that tracks data drift and prediction quality over time. These aren't optional additions; they're the infrastructure that makes AI reliable in production.
Vendor evaluation framework—selecting the right platform and partner
The 6-dimensional vendor evaluation scorecard
Score each vendor 1–5 on each dimension, then weight by your organizational priorities.
A note on vendor lock-in: according to Informatica's 2025 research, 86% of data leaders cite avoiding vendor lock-in as a top priority. Open table formats—Apache Iceberg is currently the most portable—are the primary mechanism for preserving optionality. If a vendor's architecture requires proprietary storage formats for core functionality, weigh the lock-in dimension accordingly.
When evaluating implementation partners rather than platforms, add two dimensions: reference clients in your specific industry with relevant regulatory context, and demonstrated experience with your chosen migration pattern (the strangler fig pattern, in particular, requires specific experience to execute safely).
Data architecture modernization best practices—lessons from the 30% who succeed
Data architecture modernization fails not because of technology—it fails because of people, planning, and premature execution. The organizations in the 30% who succeed don't have better engineers; they have a clearer decision framework. Here's what that framework looks like in practice.
Implementation checklist
- [✓] Complete the organizational readiness scorecard before selecting an architecture pattern
- [✓] Identify and formally onboard domain data owners before infrastructure deployment begins
- [✓] Define success metrics (not activity metrics) for each phase: query performance, adoption rate, data quality scores, TCO trajectory
- [✓] Choose open table formats (Iceberg, Delta Lake) to preserve vendor optionality
- [✓] Design governance before migration, not after—data catalog, ownership matrix, quality thresholds come first
- [✓] Apply the 70/20/10 rule: lift-and-shift the majority, re-platform a minority, re-architect only what genuinely requires it
- [✓] Use the strangler fig pattern for any production system with an SLA
- [✓] Run parallel operations until the new platform achieves equivalent or better quality scores than the legacy system
- [✓] Build the training program before go-live, not after adoption lags
- [✓] Establish rollback criteria for each phase - written, agreed upon, and tested before migration begins
- [✓] Budget for storage optimization work as a distinct workstream, especially for lakehouse deployments at scale
- [✓] Plan vector store and feature store integration points even if AI/ML workloads are 6–12 months away
Red flags that modernization is heading toward the 70%
Watch for these during execution:
- Architecture decisions are being made without domain owners present—the people who will own the data aren't shaping the design.
- The legacy system is being decommissioned on a timeline driven by cost reduction rather than new-system readiness.
- Data quality metrics aren't being tracked in the new environment—teams are assuming quality will improve without measuring it.
- Training is being treated as a launch event rather than an ongoing program.
- The governance framework is documented but not enforced—exceptions are approved without a change process.
- Engineering velocity on the new platform is lower than expected, but no root cause analysis has been done.
- Business stakeholders are asking for reports from the legacy system "just while the new one stabilizes"—if this persists beyond 60 days post-migration, it signals an adoption problem requiring escalation.
- The executive sponsor has rotated or disengaged—most modernization projects that lose executive sponsorship mid-stream don't recover.
Conclusion
Architecture Follows Readiness
There's a version of data architecture modernization where an organization picks a trending pattern, deploys infrastructure, and declares success. This version accounts for most of the 70% that fail.
The decisions that separate the successful 30% happen before the first line of infrastructure code: choosing the right pattern for organizational constraints rather than industry trends, assessing readiness honestly before committing investment, and designing governance alongside technology rather than as an afterthought.
The market is growing toward $24.4 billion by 2033 (Business Research Insights, 2025), and competitive pressure from AI adoption means the window for staying on an 8-year-old data warehouse infrastructure is genuinely narrowing. But getting there on a timeline driven by urgency rather than readiness is the fastest route to the 70%.
Start with the readiness scorecard. Be honest about the score. Address the gaps before committing the budget. The architecture decision comes second.
References
- Business Research Insights / Verified Market Research. (2025). Data architecture modernization market analysis. Market valued at $8.8 billion (2024), projected to be $24.4 billion by 2033, CAGR approximately 12%.
- Gartner; BCG. (2024–2025). Digital transformation failure rates. Approximately 70% of initiatives fail to meet stated objectives.
- Capgemini. (2025). Data modernization TCO benchmarks. 20–50% total cost of ownership reduction documented across modernization engagements.
- Gartner. (2025). The cost of poor data quality. Organizations lose $9.7–15 million annually.
- MuleSoft. (2025). Connectivity benchmark report. 28% of enterprise applications are currently connected; 95% of IT leaders cite integration issues as a barrier to AI adoption.
- Market Reports World. (2025). U.S. data infrastructure analysis. 69% of organizations report data warehouses older than 8 years; post-modernization query performance improvements of 42–49%; data duplication reductions of 35–40%.
- Valorem Reply. (2026). Hybrid cloud migration benchmarks. 30–40% cost reduction over 18–24 months; 70/20/10 workload migration framework.
- Exploding Topics. (2024). Global data creation statistics. 400 million terabytes of data are generated daily.


.webp)







