
.webp)
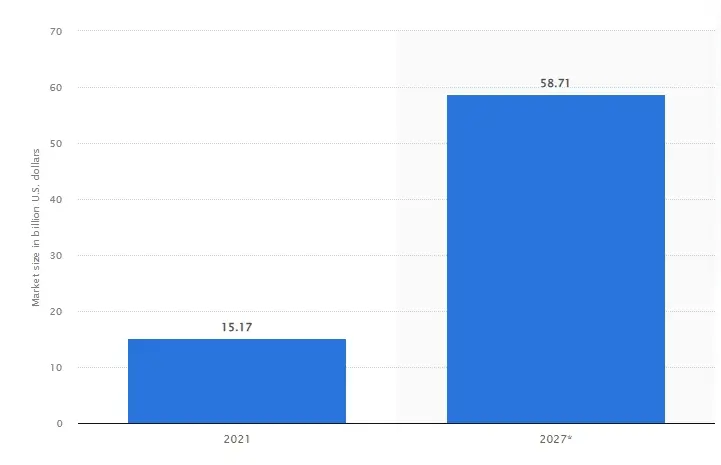
To make the most of global digitalization, organizations have access to Big Data that they can use to drive business growth, research, and development. However, obtaining relevant information can take time and effort. That is where web scraping comes into play.
The technique amounts to extracting data from websites by using automated software tools. In this article, we will explain what the practice is, why it matters in today's digital world, how the workflow unfolds, and what it can be applied to. We will also weigh the legal and ethical considerations, survey real applications, and review the tooling and techniques involved.
Data parsing



These guys are fully dedicated to their client's success and go the extra mile to ensure things are done right.
These guys are fully dedicated to their client's success and go the extra mile to ensure things are done right.
What Is the Essence of Data Mining as Part of Big Data?
Web scraping — also called data scraping or web data extraction — is the act of pulling content out of pages through automated scraping software tools. The payload may arrive in many shapes: text, images, audio, and video. A web scraper navigates web pages, locates the relevant fields, and lifts them out. Whatever it captures can then be saved in a tidy data structure for downstream use, with storage details such as format, schema, and location decided in advance. If you need an individual approach to a solution, schedule a call.

Lots of Web Scraping Data Options
In today's digital world, information is the most valuable resource for businesses and researchers alike. Automated harvesting is essential for sourcing the inputs that fuel growth. The approach lets organizations gather Big Data quickly and efficiently, handing them a competitive edge over rivals. The same method can track brand mentions on social media, monitor competitors' pricing strategies, and assemble inputs for market research.
Web Scraping Order Without Regard to Data Types
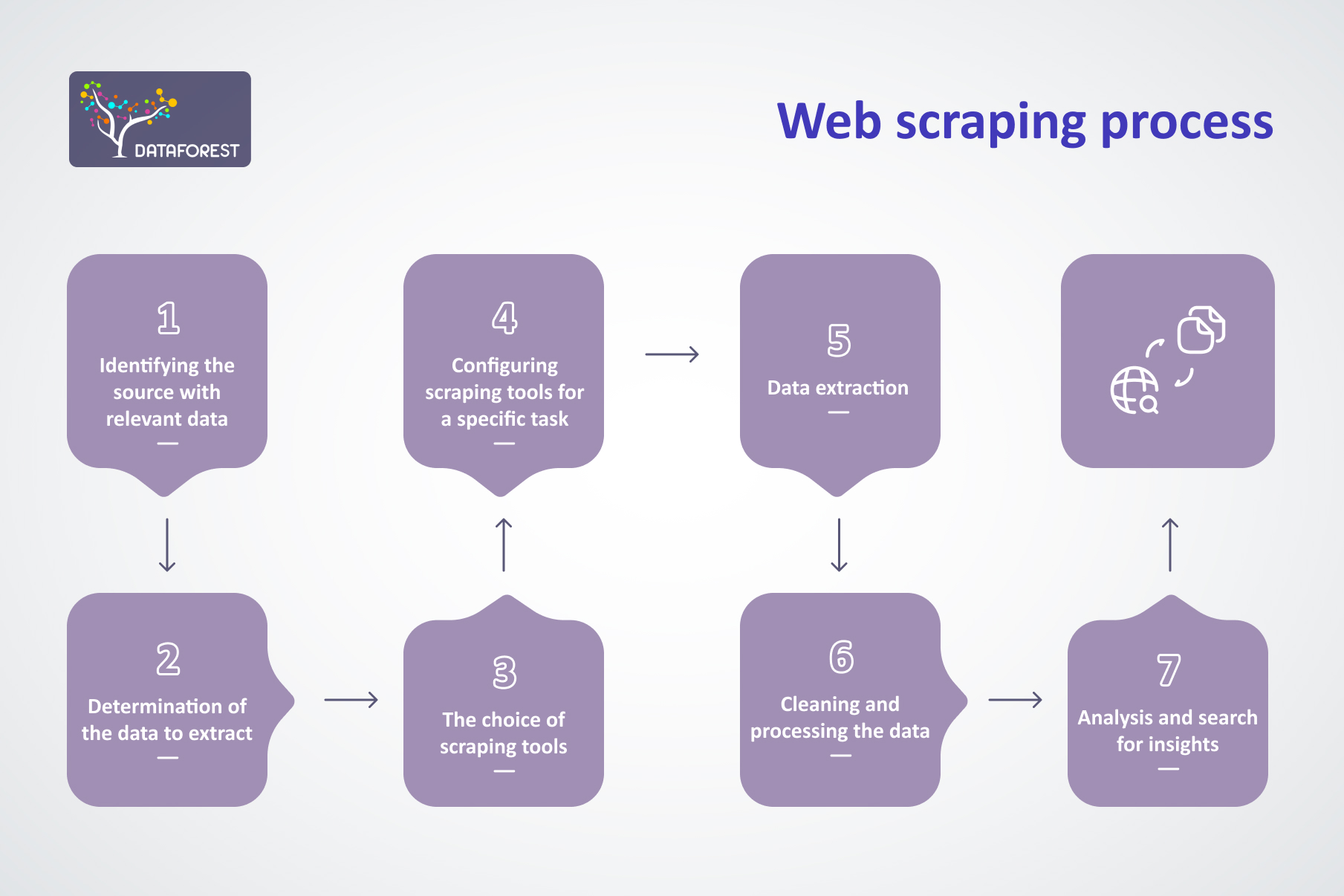
The collection workflow moves through several steps before the desired records leave a site. It remains a vital way to scrape data and to obtain qualitative, relevant material fit for analysis.
Here is an in-depth overview:
- The first step is identifying the website you want to pull from. It could be a competitor's page, a social media platform, or any other resource holding useful records. Pinpointing the source accurately matters, since it guarantees the correct fields are captured.
- Once you have locked onto the target website, you must determine the data you want to extract — product information, pricing, customer reviews, or anything else relevant to your business.
- Various web scraping tools are available, and the right pick depends on the specific needs of your project. Popular options (Beautiful Soup, Scrapy, Selenium, Octoparse, and WebHarvy) automate retrieval and let you extract data from sites swiftly.
- After choosing the instrument, you must configure it to capture the desired fields. That means pointing it at the pages, naming the HTML tags to read, and supplying any other parameters the program expects.
- Once configured, you can run it to extract the data. The program walks the site and lifts the specified content. The harvest can then be saved in a structured form for later use.
- The output may carry errors, duplicates, or noise. Therefore, cleaning and processing the data before analysis is essential — dropping duplicates, fixing mistakes, and filtering out irrelevant rows.
- Once everything is cleaned, you can analyze it to gain insights and make data-driven decisions. Data analysis methods — data visualization, regression analysis, and machine learning — help extract insights from the data.
It should be noted that the process can grow complex, and obstacles may appear along the way. Some sites deploy defenses to block automated retrieval, such as CAPTCHAs or IP blocking. Others demand authentication or login credentials before they release specific data. Being aware of these hurdles, and preparing to clear them, is integral.
The practice can be a powerful means of obtaining relevant material to drive business growth and research. Even so, ethical and legal discipline is essential. Organizations must make sure they are not breaking laws or agreements while collecting.

Where Can You Use Web Scraping Content?
Automated collection is a versatile technique that fits countless applications across many industries. Its limits are set only by the user's imagination. Here are a few illustrations of what the method delivers:
- Market Research: harvested intelligence on competitors' products, pricing strategies, and marketing campaigns. A fashion brand, for instance, can watch the prices and availability of rival items to shape its own pricing.
- Lead Generation: gathering contact information for prospective customers feeds targeted campaigns and lead generation. A real estate firm, say, can compile contact details for potential home buyers and sellers, then reach them with specific marketing.
- Product Data: pulling product data for analysis lets teams refine listings, sharpen pricing, and spot trends. An e-commerce store can monitor prices, descriptions, and reviews to surface popular items, adjust prices, and polish copy.
- Brand Monitoring: tracking brand mentions on social media gauges sentiment, flags emerging issues, and guides timely responses. A company can watch the platforms for mentions, address negative feedback, and lift satisfaction.
- Real Estate: real estate data scraping helps businesses collect property listings, prices, location details, and market trends from relevant online sources. This information supports investment decisions, reveals emerging opportunities, and helps investors identify promising areas for growth.
- Digital Marketing: pulling figures on engagement rates, demographics, and content performance across social channels. A digital marketing agency can study campaigns and tune them for better reach.
- Research and Development: assembling material on scientific research, academic publications, and patents informs R&D, surfaces collaborators, and tracks scientific trends. A pharmaceutical firm can watch the literature for possible drug discoveries.

Legal and Ethical Aspects and Data Security
The technique can be a powerful way to obtain valuable material, yet the legal and ethical implications deserve genuine attention, alongside data security and even application security where defenses come into play.
Legal Considerations
- Sites publish terms of service agreements that users accept before browsing. Those terms can restrict automated retrieval, and breaching them invites legal consequences.
- Copyright law protects the intellectual property of site owners. Copying or redistributing protected content without permission can trigger legal action.
- Data protection laws (GDPR and CCPA) shield individual privacy. Gathering personal records without consent can bring legal punishment.
Ethical Considerations and Consent Legitimate
- Harvesting can sweep up personal information without the knowledge of the people involved. You must respect their privacy and secure permission before collecting.
- Being transparent about the tooling and the records you gather is essential. Organizations must state the purpose of collection and obtain agreement from those concerned.
- Whatever is captured should be handled responsibly and ethically. It must never serve malicious ends such as discrimination or harassment.
- The method should be applied fairly and without bias. Captured records should not be used to discriminate against people based on their differences.
Liability for Violation When Illegal Scraping Is Used
Unethical or unlawful collection carries risks and consequences: legal action, reputational harm, and lost trust from clients and stakeholders.
Following ethical and legal practice therefore matters. Organizations must secure consent or hold a legitimate interest in the records they pursue, and ensure that anything extracted is used responsibly. A documented basis — clear consent or a defensible legitimate interest — keeps the program defensible.
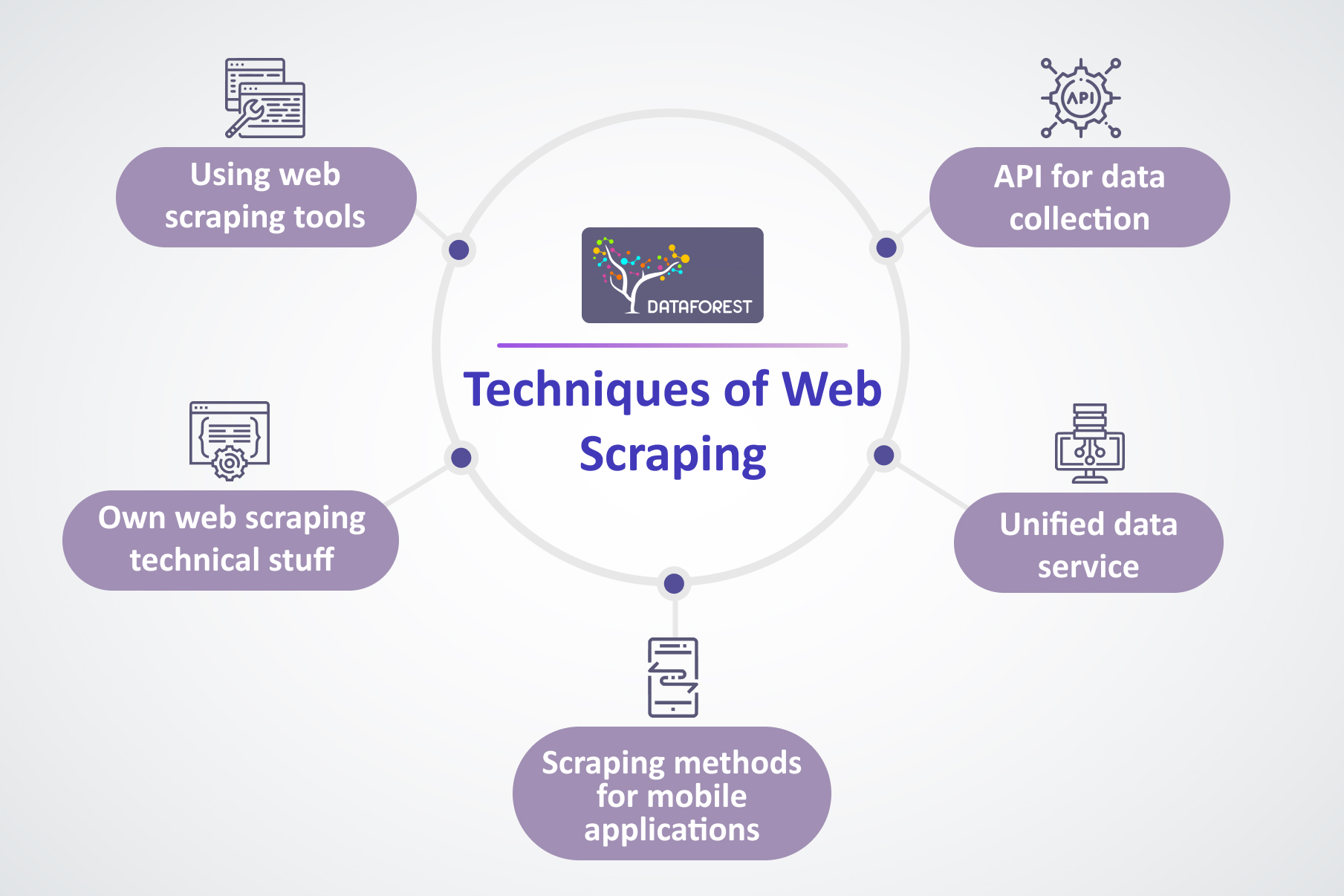
What Techniques Provide High-Quality Web Scraping?
The first method that comes to mind is gathering information by hand, hiring people to track details on the resources of interest. But such labor is slow, and the chance of human error runs high. As data science matured, the field accumulated several proven techniques and tools.

- Using scraping tools
Automatic scrapers or click-to-collect utilities offer an easy route to retrieval.
- No programming knowledge is required. You only need to know which button to press.
- You can create 100,000 data points for less than $100.
- You can harvest millions of web pages without worrying about infrastructure or network bandwidth.
- Even where sites run anti-bot protection to prevent collection, capable scraping software clears these defenses and keeps things running.
- You can pull anytime, anywhere, riding on cloud-based infrastructure.
- Your own technical stack
If your needs are too demanding for an off-the-shelf web extraction tool, consider building a team of developers and data engineers — including full stack web development talent — to transform and load (ETL) records into a database. This route lets you tailor everything to requirements while gaining manageability and flexibility. Mind that it also demands money and resources, and that stack web ownership means you carry the maintenance.
- API for data collection
Programming knowledge is usually needed to use APIs that serve the required data. As demand grows, so do costs, and it is also hard to personalize the collection process.
- Unified data service
Another option, instead of running scraping tools or hiring developers yourself, is outsourcing your data mining needs. Some firms provide IT services and, under the hood, lean on one of the approaches above.
- Scraping methods for mobile applications
Mobile app scraping leans on tools like Selendroid, Appium, Bluestacks, or the Nox emulator to run bulk mobile app scraping in the cloud. Recycling at scale is full of problems if you do it yourself. If that's your aim, also keep in mind:
- Working the PWA of the mobile app, if one exists
- Outsourcing the collection from mobile applications
Top 5 Best Web Scraping Tools
DATAFOREST offers a custom approach to every specific problem. Standard techniques and instruments usually suffice — but only when they benefit the project. We hold that conventional kit can deliver unconventional results.
Leading open source scrapers:
- Scrapy is a Python framework first conceived for harvesting, though it also serves to extract information through an API or as a general web crawler.
- Apache Nutch is a modular Java framework for building a search engine on technologies tuned to the specifics of Internet search.
- StormCrawler is an open-source kit for building scalable, low-latency crawlers atop Apache Storm.
- PySpider is a powerful crawler that exposes an API for fetching content from third-party resources, plus a web interface to govern many parts of the run.
- BS4 is a Python library for pulling records out of HTML and XML files.
Beyond mastery of standard kit, DATAFOREST keeps its own time-tested solutions. Marrying the two approaches covers our clients' needs in web scraping completely, whether they need ready-made web scraping software or a bespoke build.
Applications of Web Scraping With the Specific Data
Automated collection spans a wide range of uses across industries. This section walks through several sectors that rely on it and the specific use cases for web scraping in each. You will see the technique put to work — and screen scraping pressed into service for legacy interfaces — in settings as varied as:
- In the e-commerce industry — gathering product data, watching prices, and parsing customer reviews to refine pricing, polish descriptions, and surface popular items.
- In e-market research — collecting competitors' products, pricing strategies, and marketing campaigns to read the market and make data-driven decisions.
- In the real estate industry — pulling listings, prices, and trends. This material can inform real estate investment decisions, surface opportunities, and keep the market in view.
- In digital marketing — capturing engagement rates, demographics, and content performance across social channels to tune digital marketing campaigns and lift brand awareness.
- In the finance industry — collecting market figures, stock prices, and economic indicators to guide investment, surface opportunities, and watch trends.
- In the healthcare industry — assembling material on medical research, clinical trials, and drug pricing to steer R&D, find collaborators, and track scientific movement.
- In the law industry — collecting cases, court decisions, and legislative updates to read legal trends and spot opportunities.
Use Cases of Automated Web Scraping in Business and Research
The practice has plenty of use cases in both business and research. This section covers the most common ones, and shows where you will see web scraping used day to day.
Business Use Cases
It supports:
- Lead generation through contact details for prospective customers, ready for targeted campaigns.
- Competitive analysis by gathering rivals' products, pricing strategies, and campaigns, yielding market insight for data-driven decisions.
- Brand monitoring by tracking social platforms for mentions, gauging sentiment, flagging issues, and answering feedback.
- Product development by collecting customer feedback, reviews, and ratings to improve features and spot room to grow.
- E-market research by reading consumer behavior, preferences, and trends to guide research and surface openings.
- Data analytics by drawing on and analyzing material from many sources to inform decisions, reveal trends, and illuminate customer behavior.
Cases of Research As Part of Artificial Intelligence
It supports:
- Data collection in research by drawing from many sources, websites and social platforms included. Increasingly this feeds artificial intelligence pipelines.
- Text mining by gathering textual material and surfacing patterns and relationships in copywriting.
- Sentiment analysis by reading customer reviews from social platforms to flag emerging issues.
- Data visualization by collecting and charting material from many sources to expose trends across groups of goods and services.
- Machine learning by amassing training material to lift model accuracy and effectiveness.
Web Scraping for Both Business and Research Solution Class
This solution class delivers numerous benefits to organizations and researchers, including:
- Quick, efficient collection that saves time and resources.
- Valuable insight into market trends, customer behavior, and rivals' strategies, fueling sharper decisions.
- Cost savings, by cutting the need for manual gathering and analysis.
- A competitive edge, through visibility into competitors' strategies, product lines, and pricing.
- Stronger research, via fast access to large volumes of material.
By following the best practices outlined above and choosing the right web scraping tools and techniques, organizations and researchers can pull valuable insights from what they collect and sharpen their decision-making.
Web Scraping Is for Technology Alliance Partners
For technology alliance partners, the method is a verified way to supply customers with valuable records. Still, the legal and ethical considerations matter, and the right instruments and techniques should be chosen with care. Used properly, it grants businesses a competitive edge and underpins informed choices.
As technology advances and more material becomes available, the discipline will remain essential for organizations across industries. It is worth grasping both the upside and the risk, and proceeding responsibly and ethically.
If your business — whatever its size — would benefit from the data collected by scraping, and that isn't obvious to you yet, DATAFOREST stays in touch with simple solutions to complex problems. Let's take a look at yours.

FAQ
What is web scraping, and how does it work?
It is the act of pulling content from sites with automated software or tools. A request goes to a page, the HTML is parsed, and the relevant fields are lifted out via regular expressions or XPath. In short, screen scraping reads what a browser would render, while structured retrieval targets the underlying markup.
Is web scraping legal?
Whether web scraping is legal turns on several factors — a site's terms of service and the jurisdiction where the scraper runs. As a rule, harvesting publicly available information is permitted, while pulling personal or copyrighted material may not be. Knowing what makes a given scraping legal is the operator's responsibility.
What are some standard techniques used in web scraping?
Common approaches include reading HTML content, calling APIs, and using specialized kit such as BeautifulSoup or Scrapy.
What are the benefits of web scraping for businesses and researchers?
It opens fast, easy access to large volumes of material. Those records serve many ends — market research, competitive study, and trend analysis among them.
What are some challenges that arise during the web scraping process?
Typical hurdles include anti-scraping defenses, dynamic pages, and keeping quality and accuracy intact.
How can one ensure the quality and accuracy of the data obtained through web scraping?
Verify the source, validate against multiple sources, and run thorough cleaning and normalization.
What are some ethical considerations to keep in mind while web scraping?
Respect the target site's terms of service, avoid sweeping up personal or sensitive material, and stay transparent about how collection happens.
How can web scraping be used to gain a competitive advantage in the market?
It hands businesses a window into rivals' pricing, product lines, and marketing, which sharpens their own play.
Can web scraping be used for personal data collection, and if so, what are the potential risks involved?
It can, but doing so may be illegal or unethical depending on the source and nature of the material. The risks in private collection include legal action, reputational damage, and lost trust with customers or stakeholders.










