

In the digital-first world, data is not just a by-product of business operations. It is the central nervous system. The ability to use, interpret, and process large streams of information separates market leaders from laggards. A much-cited report by McKinsey found that data-driven organizations are 23 times better at acquiring customers and six times more likely to retain them. But raw data in its native state is a chaotic stream, residing in disjointed silos such as CRM systems, transactional databases, cloud applications, and unstructured databases. The urgent need is to transform this chaos into harmony. This is exactly where the best ETL tools and modern data architectures come into play—Extract, Transform, and Load (ETL) platforms that convert fragmented data into actionable intelligence.
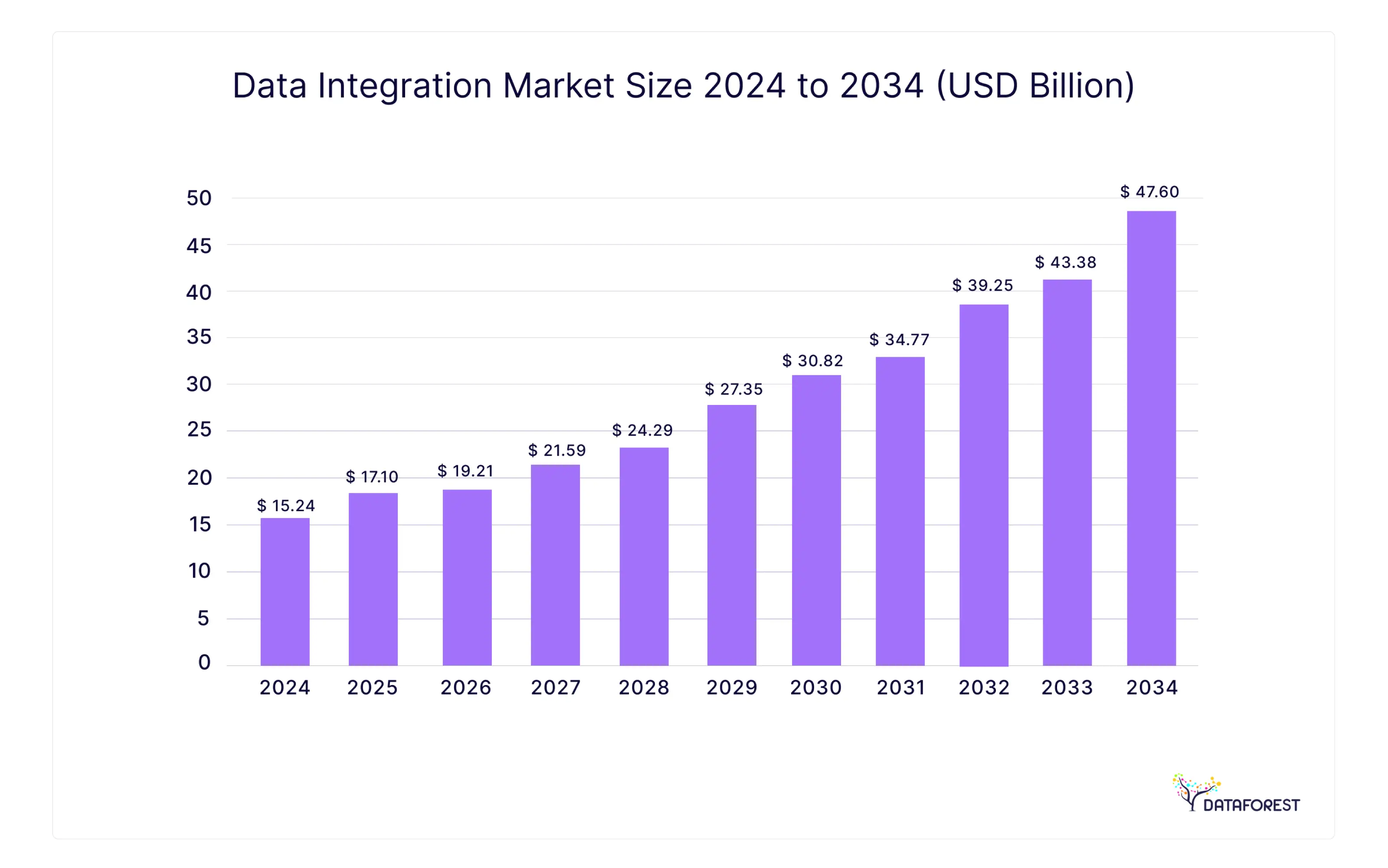
This reality is fueling intense investment in the market for these critical platforms. Projections show the ETL tools market reaching $19.6 billion by 2028, according to MarketsandMarkets research. But that figure represents more than just data movement; it reflects the demand for the best ETL tools capable of intelligent, automated data integration that powers everything from predictive analytics to strategic corporate planning.
Data platforms control the growth rate of your business. Bad choices stop your development teams from making progress. This guide lists the ETL software that keeps your company ahead of the competition. Data powers every single department in your organization.
Do you want to move faster? Select tools that perform well. DATAFOREST builds data systems for many different clients. We help you find the best ETL tools that fit your exact needs, budget, and successful data pipeline strategy.
Choosing an ETL Tool: Tips for Making the Right Choice
Choosing an ETL tool in 2026 requires more than a feature list. Your technology should align with your core business goals. The best ETL tools can serve your current business and expand to future AI projects. The wrong choice can break pipelines and increase costs for your company.
New data from SQL tables to unstructured JSON files. Your system should draw from these sources to feed Snowflake or BigQuery. The best ETL tools provide the best results by understanding how to manage your daily workflows. Clear logic drives your results; our guide to the data integration process lays out these fundamentals in detail.
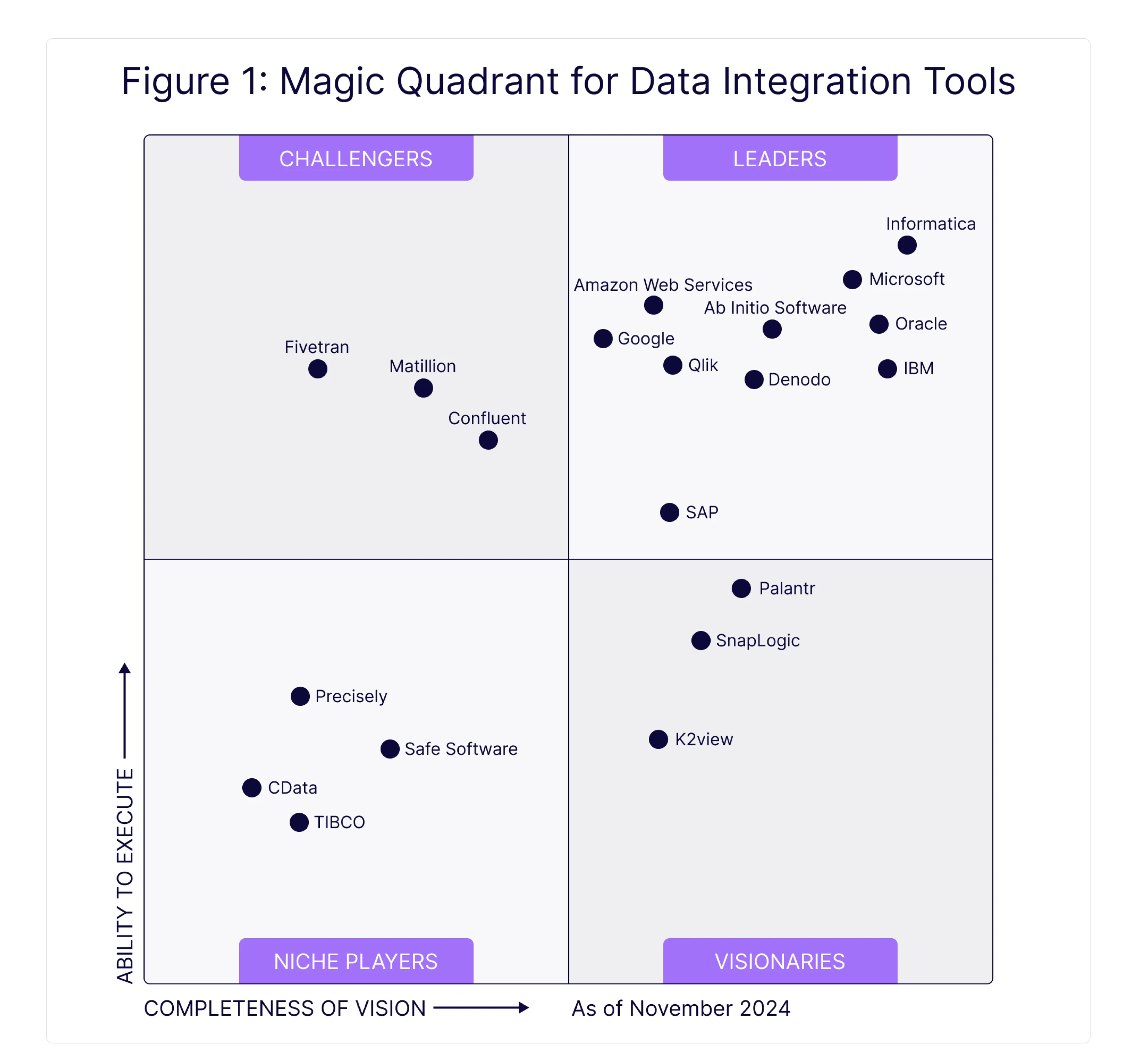
Important ETL Tool Selection Features
When evaluating the best ETL tools on the market, managers should look at the key features of each platform and filter their options through strategic, operational, and financial aspects. We've broken down the most important review steps into the following system.
Summing up the results of last year, Medium notes that hybrid and real-time ETL platforms compete with traditional batch tools. Analysts consistently rank the best ETL tools as those that balance low-code accessibility with developer-grade flexibility.
Best ETL Tools for Your Business
There is no single tool that works for every situation. Choosing the best ETL tools depends only on the business situation. A travel-tech startup has different needs than an international insurance company. A team strives for speed. Any organization needs solid governance and hybrid cloud support. Your business targets dictate the software you buy.
Compare ETL Processing Options
Real-Time Data
Fraud detection and retail inventory require immediate data. Select tools with native support for streaming sources like Amazon Kinesis. Google Cloud Dataflow and AWS Glue handle these high-speed streams well.
Large Batch Processing
Massive datasets for reporting or machine learning need distributed frameworks. Tools built on Hadoop or Spark manage these loads. Azure Data Factory is a strong option for this work.
Cloud-Native Stack
Companies using cloud data warehouses should choose tools with tight integrations. Stitch, Fivetran, and Integrate.io connect easily to these warehouses. These platforms reduce your setup time.
Hybrid and Multi-Cloud
Legacy systems and multiple clouds require cross-platform connectivity. Dell Boomi and Talend link these different environments, helping enterprises manage complex data migration and modernization initiatives while maintaining continuity between on-premise infrastructure and modern cloud ecosystems.
Aligning ETL Tool Features with Business Goals
Your software must solve specific business problems. Use Integrate.io or Skyvia if your analysts need to prepare their own data. These platforms do not require engineering help for basic tasks.
Select AWS Glue if you need a custom system for generative AI data infrastructure. This tool lets you write code to keep your expenses low. Every tool should help you reach your growth targets. DATAFOREST helps you find the best options for your specific needs.

The List of ETL Tools
Our 2026 analysis focuses on the best ETL tools available today, providing targeted analysis to business decision makers. The market is full of powerful options, each with a different set of strengths and design variations. To help you navigate this complex field, we've prepared a visual guide to complete our in-depth reviews.
Watch our video for a dynamic overview of the top 15 ETL tools shaping the industry in 2026:
Now, let’s examine the best ETL tools in detail, starting with leaders in the integration space.
Dell Boomi AtomSphere

Boomi functions as a cloud-native Integration Platform as a Service (iPaaS) that has expanded beyond ETL to include API management, master data management, and workflow automation. It connects legacy systems to modern SaaS applications.
Advantages
- Unified Platform: Offers a single environment for data integration, API management, and master data, reducing tool sprawl.
- Broad Connectivity: Features a vast library of pre-built connectors, excellent for complex, hybrid environments.
- Low-Code Interface: Its visual, drag-and-drop interface empowers a wider range of users to build integrations.
Challenges
- Pricing Complexity: The consumption-based pricing, based on connectors, can become expensive and hard to predict as usage scales.
- Performance on Large Volumes: May not be as performant for extreme big data batch processing compared to Spark-native tools.
- Steeper Learning Curve: Advanced use cases and custom scripting can be less intuitive than on other platforms.
Pricing
Boomi uses a tiered subscription model based on the number of connectors and features. A free trial and paid plans are available, but enterprise plans require a custom quote.
Airbyte

Airbyte moves data using an open-source model. It provides more than 350 connectors to link your systems. You can host the software on your own servers or use their paid cloud service. This tool transfers information from many sources into your data warehouse.
Advantages
- Large Connector Library: The platform offers over 350 connectors. Both the Airbyte team and an open-source community maintain these tools.
- Hosting Choice: You can run the free version on your hardware for full control. Use Airbyte Cloud to save time on maintenance and scaling.
- Simple Interface: The user interface allows you to build pipelines quickly. It also includes an API and a Terraform Provider for teams that prefer to use code.
Problems
- Miscellaneous Additions: The list is extensive. However, the types of supplements produced by the community vary. Some of the features are missing from the main add-ons.
- Great savings for self-hosting: It takes work to run the software on your own servers. Your DevOps team must manage the hardware to ensure system reliability.
- Focusing on data migration: Airbyte moves data within your warehouse. It does not change the data in the process. You need a second tool, like dbt, for conversion.
Pricing
Open-source software is free. You only pay for the servers you run. Airbyte Cloud uses a credit system. You pay as you go. The free level helps you try out a few programs without paying a fee.
Google Cloud Dataflow

Google Cloud Dataflow manages data processing operations. It uses the Apache Beam model to handle batch and streaming data.
Benefits
- One codebase for all data: Developers use the same code for both real-time and batch jobs. The construction of pipelines is faster.
- Automatic Scaling: The service is not centralized. It manages its own hardware and scales up or down depending on your workload.
- Built-in AI Tools: The platform integrates BigQuery and Vertex AI. These links help you quickly build BI dashboards and predictive analytics workflows.
Problems
- Google Cloud Lock-in is built in: Moving your pipelines to another provider can be difficult.
- Exchange Rates: You pay for what you use. High data rates can lead to high bills if you don't monitor your usage.
- Technical skills required: Your team should know Java or Python. This tool is for developers, not for general users.
Price
Google charges you every second for CPU, memory, and storage usage. There is a free level for small businesses. Business pipelines will become more expensive as they grow.
ETL in Azure Data Factory

Azure Data Factory (ADF) is Microsoft's cloud-based, serverless data integration service. It orchestrates and automates data movement and transformation at scale within the Azure ecosystem.
Advantages
- Deep Azure Integration: Provides native connectivity to the entire suite of Azure data services, including Synapse Analytics and Blob Storage.
- Hybrid Data Movement: A Self-Hosted Integration Runtime allows secure data movement between on-premises sources and the cloud.
- Visual and Code-Based Options: Offers both a code-freeinterface and the ability to execute custom code, catering to different skill sets.
Challenges
- Primarily an Orchestrator: Its core strength is orchestration. Complex transformations are often offloaded to services like Azure Databricks.
- Complex UI: The interface can be overwhelming for new users due to its many options.
- Debugging Can Be Clunky: Identifying the root cause of pipeline failures can sometimes be non-intuitive.
Pricing
ADF has a consumption-based model that charges for pipeline orchestration, data flow execution, activity runs, and data movement. A free tier is offered.
Portable

Portable is a newer ETL tool focused on long-tail connectors. It provides connectors for niche SaaS applications and APIs that are often unsupported by larger platforms.
Advantages
- Vast Connector Library: Specializes in building and maintaining connectors for less common data sources.
- Predictable Pricing: Most plans offer unlimited connectors and volume for a flat fee.
- Fully Managed Service: The Portable team handles connector development and maintenance, freeing up engineering resources.
Challenges
- Limited Transformation: Primarily an "EL" (Extract, Load) tool. Transformations are handled downstream in the data warehouse.
- No Database Sources: Focuses exclusively on SaaS and API sources, not traditional databases like Oracle or PostgreSQL.
- Newer Player: Lacks the long track record and enterprise governance features of established players.
Pricing
Portable offers flat-rate pricing. A free plan with manual refreshes is available. Paid plans are based on support and refresh frequency.
Stitch

Stitch is a cloud-based tool for data migration. The company is owned by Talend. It helps analysts to enter data into data warehouses without writing code.
Advantages
- The web interface is easy to navigate. You can build data pipelines in minutes without writing code.
- Pricing is clear. You pay for the number of rows you sync each month. This makes it easy to plan your budget.
- The platform uses the Singer protocol. This open-source standard lets people build and share new connectors.
Problems
- No Data Transformation: Stitch only moves raw data. You must use other tools to clean or change the data after it arrives in your warehouse.
- Missing Enterprise Features: The platform lacks advanced security and governance controls. Large corporations may find the management options too basic for their needs.
- Scaling Costs: Row-based pricing is expensive for large datasets. Your bills will rise quickly as your data volume grows.
Price
Stitch uses tiered pricing plans. Your bill depends on the number of rows you sync each month. The Standard plan starts at $100 for 5 million rows. Costs rise as your data volume grows. You can test the platform with a 14-day free trial. This trial includes unlimited data syncs.
AWS Data Pipeline

AWS Data Pipeline is a web service for processing and moving data between AWS services and on-premises sources. It's an older AWS data orchestration service.
Advantages
- Reliable Orchestration: Provides a straightforward way to schedule recurring data movement and processing tasks.
- Cost-Effective: Its pricing can be very inexpensive for low-frequency activities.
- Integrates with On-Premise Data: Can be configured to access data stored within a corporate firewall.
Limitations
- Outdated Technology: AWS Glue is now the standard for most new projects. Data Pipeline lacks a data catalog and cannot scale automatically like serverless tools.
- Difficult Interface: Building pipelines is a slow process. Modern tools like Airflow offer a much better experience for developers.
- Basic Orchestration: This tool only moves data. It cannot transform files on its own. You must use other services, like Amazon EMR, to clean or change your data.
Pricing
AWS Data Pipeline uses a pay-as-you-go model. Your bill depends on how often you run tasks and where they execute. A free tier is available for small workloads.
AWS Glue

As a fully managed, serverless ETL service, AWS Glue is a lynchpin in many AWS data architectures, designed to automate the work of data discovery, prep, and integration.
Advantages
- Serverless Architecture: No servers to manage. Glue automatically handles and scales the underlying infrastructure.
- Integrated Data Catalog: Its crawlers automatically scan data sources, identify schemas, and populate a central metadata repository.
- Spark and Python-based: ETL jobs run on a managed Apache Spark or Python shell environment, providing power and flexibility.
Challenges
- Cold Start Latency: Serverless jobs can sometimes experience a "cold start" delay, which may be an issue for time-sensitive workloads.
- Complex for Beginners: Unlocking its full potential requires coding in Python/Scala and an understanding of Spark.
- Unpredictable Cost: The DPU-hour (Data Processing Unit) pricing requires careful job optimization to control costs.
Pricing
AWS Glue charges per DPU-hour consumed, with separate charges for the Data Catalog and crawlers.

Oracle Data Integrator (ODI)

Oracle Data Integrator is Oracle's strategic data integration platform. Its ELT architecture leverages the target database for transformations.
Advantages
- High-Performance ELT: Pushes data transformations down to the target database, using native SQL Server for high-speed processing.
- Heterogeneous System Support: Provides excellent support for a wide range of non-Oracle databases and big data technologies.
- Knowledge Modules: Its modular design allows for extensibility and applies best practices for specific source/target combinations.
Challenges
- Complex and Expensive: ODI is a powerful tool with a steep learning curve and a high price tag, suitable for large organizations in the Oracle ecosystem.
- On-Premise Focus: Its architecture is rooted in on-premise deployments, though a cloud service exists.
- Declining Mindshare: Often seen as a legacy tool compared to more agile, cloud-first alternatives.
Pricing
Oracle Data Integrator is licensed per processor. Pricing is quote-based for enterprise deployments.
Informatica

Informatica moves data between business systems. This process creates a single source of truth for your organization.
Benefits
- High speed for large data sets: The platform processes a lot of data quickly. This speed helps companies meet tight reporting deadlines.
- Visual mapping tools: Drag-and-drop interfaces reduce the need for manual code. This method helps developers build pipelines faster.
- Broad integration: The program includes hundreds of cloud and local sources. It works with large databases and business applications.
Problems
- High price: Annual subscriptions usually start at $50,000. Business licenses can cost more than $1,000,000, depending on your scale.
- Special skills: Developers need advanced training to manage the platform. This requirement increases your tuition and fees.
- Major hardware requirements: The system needs at least 16 GB of RAM and 4 CPU cores. You need to provide a dedicated server or a cloud model.
Price
Informatica uses an annual subscription model. Prices depend on the amount of your data and the number of connections. They also offer payment plans for the specific sectors you are working on.
Talend Open Studio

Talend Open Studio is a popular open-source ETL tool. Its graphical, Eclipse-based environment builds data integration jobs using code generation.
Advantages
- Free and Open-Source: The core tool is free, making it accessible to developers and small businesses.
- Vast Component Library: Offers over 1,000 pre-built connectors and components to build complex pipelines.
- Code Generation: Generates native Java code that can be exported and run on any machine with a JVM.
Challenges
- Commercial Version Up-sell: Advanced features like collaboration and scheduling are reserved for the paid version, Talend Data Fabric.
- Resource Intensive: The Eclipse-based IDE can be slow and consume significant memory.
- Community Support Model: Support for the free version relies on community forums, which may be insufficient for enterprise issues.
Pricing
Talend Open Studio is free. The commercial platform, Talend Data Fabric, is subscription-based, with pricing upon request.
Skyvia

Skyvia is a 100% cloud data platform offering ETL, ELT, backup, and API management. It targets business analysts and IT professionals needing quick, no-code data solutions.
Advantages
- No-Code Simplicity: The platform is wizard-driven, allowing users to set up integrations without coding.
- Predictable, Freemium Pricing: Offers a generous free tier and clear, record-based pricing for paid plans.
- All-in-One Platform: Combines ETL, backup, and data access in a single subscription.
Challenges
- Limited Customization: The no-code approach offers less flexibility for highly complex transformation logic.
- Performance on Very Large Datasets: May not match the raw performance of distributed tools for petabyte-scale jobs.
- Connector Focus: Primarily focused on popular cloud applications and databases.
Pricing
Skyvia has a freemium model. The free plan includes 10,000 records/month. Paid plans are tiered based on record count and features.
Matillion

Matillion is a cloud-native ELT platform built specifically to leverage the power of modern cloud data warehouses like Snowflake, Amazon Redshift, Google BigQuery, and Databricks. It uses a "push-down" ELT approach, transforming data directly within the target warehouse for maximum efficiency.
Advantages
- Optimized for Cloud Warehouses: Its architecture is designed to get the most performance out of your cloud data platform by converting its graphical workflows into native SQL for execution.
- Intuitive, Low-Code Interface: Features a polished, browser-based UI that empowers a broad range of users to visually design, schedule, and monitor complex data transformation pipelines.
- Predictable Pricing: The instance-based pricing model (charging per hour based on VM size) is transparent and easy to forecast, avoiding the potential for unexpected costs common with consumption-based models.
Challenges
- Tightly Coupled to Warehouse: The platform is licensed per data warehouse. If your organization uses both Snowflake and BigQuery, for example, you would need separate Matillion instances.
- Requires Infrastructure Management: Unlike fully serverless tools, the customer is responsible for managing the cloud virtual machine that Matillion runs on, adding some operational overhead.
- Primarily ELT (Not ETL): Its strength is in post-load transformation. Use cases that require heavy in-flight transformations before loading data into the warehouse are not a natural fit for its architecture.
Pricing
Matillion offers straightforward, hourly pricing through the AWS, Azure, and Google Cloud marketplaces, with costs determined by the size of the underlying virtual machine instance. A 14-day free trial is available.
Fivetran

Fivetran is a dominant force in the modern data stack, championing the ELT paradigm. It provides fully managed, zero-maintenance data pipelines that are easy to set up.
Advantages
- Automated and Maintenance-Free: Fivetran handles schema migrations, API changes, and failures automatically.
- Extensive Connector Library: Offers a massive and growing list of reliable, pre-engineered connectors.
- Transformation Integration: Seamlessly integrates with dbt (Data Build Tool) for handling transformations within the data warehouse.
Challenges
- Strictly ELT: It does not perform transformations in-flight, which may not suit all use cases.
- Consumption-Based Pricing: The model is based on "Monthly Active Rows" (MAR), which can be difficult to predict.
- "Black Box" Nature: Its automated nature means less control and visibility compared to tools like AWS Glue.
Pricing
Fivetran uses a consumption-based pricing model. A 14-day free trial paid plan is available.
Hevo Data

Hevo Data moves data from many sources to cloud warehouses and provides teams with current facts.
Advantages
- Fast setup through a visual no-code interface.
- Access to more than 150 pre-built data sources.
- Automated tracking of changes in data structures.
Challenges
- High data volumes increase the total cost.
- Fixed batch intervals cause data delays.
- Users find few options for complex logic.
Pricing
A free tier allows 1 million monthly events, and paid plans start at $239 per month.
Streamlined Data Analytics

Their communication was great, and their ability to work within our time zone was very much appreciated.
How DATAFOREST Uses Top ETL Technologies to Automate the Full Data Journey
Choosing a tool is just the start. The real value of the best ETL tools emerges through expert implementation—resilient, scalable, and cost-efficient pipelines built for long-term growth. At DATAFOREST, we combine the best ETL tools with deep architectural expertise to turn fragmented data into a strategic asset. Our focus is on constructing complete data solutions that produce tangible results, whether that’s through warehouse automation or sophisticated advanced planning systems.
Our approach begins by analyzing your specific business context to select and integrate the optimal technologies, ensuring your data infrastructure becomes a competitive advantage. The success of our clients, such as our work in streamlining data analytics, demonstrates the power of this tailored approach.
Technologies We Work With (Reviewed in This Article)
Our philosophy is to use the right tool for the right job, frequently architecting a hybrid technology stack to achieve the best possible performance. Our hands-on experience includes many of the leading platforms reviewed here:
Technologies we use that are also featured in this review include:
- AWS Glue: For building scalable, serverless ETL workflows.
- Apache Hadoop: For architecting and optimizing massive big data solutions, often with Amazon EMR.
- Google BigQuery: For building lightning-fast, real-time analytics platforms.
- Airflow / Cloud Composer: For orchestrating complex and reliable data pipelines.
- Amazon Kinesis: For engineering real-time data streaming solutions.
- Snowflake: For modernizing data warehousing with its unique cloud-native architecture.
- MongoDB: For flexible, document-oriented data management.
- Cassandra: For high-availability, distributed data infrastructure.

Charting Your Course for Data-Driven Leadership
Navigating the best ETL tools market can feel overwhelming. The path from scattered data points to clear, actionable intelligence is a complex one, filled with high-stakes decisions on architecture and future-proofing. The platforms we've detailed represent the top tier of what's available in 2026, each with distinct advantages for different business scenarios. Choosing correctly demands clarity on your business goals and a cohesive technology strategy.
But always keep in mind that tools alone don’t create transformation. The best ETL tools, paired with expert implementation, become the foundation for intelligent, automated data ecosystems.
Ready to make your data your most powerful asset? Contact the experts at DATAFOREST for a frank discussion about how the best ETL tools can accelerate your growth strategy.
Questions on the Best ETL Tools
How do AI and automation enhance ETL workflows today?
They are fundamentally reshaping the landscape through "augmented data management." AI-driven automation now handles critical, repetitive tasks like schema detection, metadata discovery, and data quality anomaly flagging. Advanced algorithms can also dynamically optimize pipeline performance by reallocating resources or predicting failures before they occur. This evolution is foundational for building the responsive generative AI data infrastructure modern enterprises require.
Can low-code or no-code ETL tools scale for enterprise-level needs?
Absolutely. Leading platforms like Integrate.io and Dell Boomi are built on highly scalable cloud infrastructure and are fully capable of processing enterprise-level data volumes. Their primary business advantage is accelerating development and empowering more users, making organizations more agile. However, for hyper-specific, performance-critical workloads, a code-first platform like AWS Glue often provides superior granular control. The decision represents a strategic trade-off between development velocity and deep customization, a core topic in our data integration consulting.
How do we choose between cloud-native and on-premise ETL solutions?
The choice hinges on a balance of scalability, security, and cost. Cloud-native tools offer elastic scalability, pay-as-you-go pricing, and reduced maintenance, making them ideal for modern, cloud-centric businesses. On-premise solutions provide maximum control over data security and compliance, which can be non-negotiable for highly regulated industries like finance or healthcare. A hybrid approach is often the most practical path for established enterprises looking to modernize without abandoning legacy systems.
How do the best ETL tools integrate with our existing BI systems and analytics platforms?
Seamless integration is a primary design goal for the best ETL tools. They feature optimized, pre-built connectors that load analysis-ready data directly into major data warehouses (Snowflake, BigQuery, Redshift) and data lakes. Your Business Intelligence platform (like Tableau, Power BI, or Looker) then connects to this centralized, clean data source. The ETL process ensures that the data fueling your BI and data analytics dashboards is timely, consistent, and reliable.
What should we do if our current data volumes exceed our chosen ETL tool's capabilities?
First, attempt to optimize. This involves refactoring transformation logic, improving indexing, and scaling the underlying resources if the platform allows (e.g., increasing DPU count in AWS Glue). If optimization is insufficient, the tool's architecture may be the bottleneck. This necessitates a strategic migration to a more powerful platform designed for big data. This is a complex undertaking where an experienced partner can help de-risk the process and ensure a smooth transition, as seen in cases like our streamlined data analytics project.
How do emerging trends like real-time processing and ML impact ETL tool selection?
These trends are pushing the market beyond traditional batch processing. Real-time processing demands tools with robust streaming capabilities (e.g., Google Cloud Dataflow, tools integrating with Amazon Kinesis) for use cases like fraud detection. Machine Learning requires platforms that can seamlessly prepare and operationalize data for ML models. This means your tool must not only move data but also be part of a larger intelligent data automation ecosystem. Selecting a tool today means anticipating these future needs.


.webp)







