

Your data warehouse is loaded. Your transformation layer is running. Your BI dashboards are live. And your AI model is still ingesting last Tuesday's data.
This is the coordination problem—and it's more common than most data teams admit. Individual tools in the modern stack do their jobs well in isolation. What they don't do is talk to each other in the right order, at the right time, with the right dependencies enforced. That gap is where pipelines break silently, where ML models train on stale features, and where a single upstream schema changes cascades into three broken dashboards and one very unhappy product team.
Data orchestration coordinates, sequences, and monitors every pipeline in your stack—from raw ingestion through transformation to serving. It is not ETL, not a data warehouse feature, and —despite what some vendor documentation implies—Snowflake and Kafka do not replace it.
This guide covers what data orchestration is, how it differs from adjacent tools, why it has become critical infrastructure for AI pipelines, and how to evaluate whether to buy a dedicated platform or build your own coordination layer. If you are deciding whether your stack needs this layer—or which tool should own it—this guide covers the decision framework directly.
Key Takeaways
- A Forrester TEI study found 438% ROI within six months and 75% less infrastructure management effort after adopting a dedicated orchestration layer (see 'The Business Case for Data Orchestration' below)
- Cron scripts are not a free solution: without orchestration, coordination logic lives in undocumented glue code that compounds cost with every new data source added (see 'The Business Case for Data Orchestration' below)
- UK logistics company HIVED achieved 99.9% pipeline reliability with Dagster, showing orchestration is a revenue-protecting investment, not just an infrastructure line item (see 'The Business Case for Data Orchestration' below)
- Agentic AI systems require deterministic data contracts enforced by the orchestration layer—without them, agents operate on incoherent snapshots and produce unpredictable, unauditable outputs (see 'Data Orchestration and AI Pipelines' below)
- Teams starting greenfield projects in 2025 that default to Airflow often spend the first six months building observability and lineage scaffolding that Dagster or Prefect ship out of the box (see 'Data Orchestration Tools' below)
- 71% of AI teams spend more than 25% of their time on data integration and pipeline work.
What Is Data Orchestration? (A Definition That Actually Holds Up)
Data orchestration is the coordination layer that manages how data moves, transforms, and activates across every system in your stack. It sequences pipeline steps in the right order, enforces dependencies, handles retries on failure, and surfaces observability so engineers can debug what went wrong and when. Without it, you have scripts—not a system.
The core job: coordinate, sequence, and monitor
Orchestration is not a single tool. It is a discipline: defining what runs, in what order, under what conditions, and what happens when something breaks. A well-orchestrated pipeline knows that a downstream transformation cannot start until upstream ingestion succeeds. It knows to retry a flaky API call before alerting. It logs every step so you can trace a data quality issue back to its source without guessing.
This is what separates orchestration from simple scheduling. A cron job fires at a fixed time. An orchestrator fires when conditions are met, monitors the result, and responds intelligently to failure.
Why the average enterprise stack needs a control plane
The scale of the problem is not abstract. The average enterprise data stack in 2026 has more than ten tools working together: a warehouse, an ingestion tool, a transformation framework, a BI layer, a streaming platform, multiple cloud services, and a handful of custom scripts nobody wants to touch. According to an IDC survey of IT and line-of-business leaders, operational data is sourced from 35 systems and integrated into 18 analytical data repositories, on average.
Each of those systems has its own failure modes, latency characteristics, and access controls. Without a control plane sitting above them, the coordination logic lives inside individual scripts, Slack messages, and tribal knowledge. That is not a pipeline—it is a liability—especially in environments where scalable data architecture practices are required to support AI, analytics, and real-time workflows.
Three-stage process: Organize → Transform → Activate
The cleanest mental model for data orchestration is a three-stage process: Organize → Transform → Activate.
- Organize: Collect and ingest raw data from source systems, applying governance rules and access controls at the point of entry.
- Transform: Clean, join, aggregate, and enrich data into the shape downstream consumers need - whether that is a BI dashboard, a machine learning feature store, or a real-time application.
- Activate: Deliver the prepared data to the right destination at the right time, whether that means loading a warehouse, triggering an API, or feeding an AI inference pipeline.
The orchestration layer does not transform itself. It coordinates the tools that do—and ensures the whole sequence runs reliably, repeatedly, and with full visibility into what happened at each stage.
Data Orchestration vs. ETL: What Actually Differs
ETL (Extract, Transform, Load) moves data from a source to a destination through a defined transformation step. Data orchestration coordinates the entire pipeline ecosystem—scheduling jobs, managing dependencies between systems, handling retries, and surfacing failures—regardless of whether ETL is one of those jobs. ETL is a process; orchestration is the control layer above it.
Where ETL ends, and orchestration begins
ETL tools are purpose-built for data movement and transformation. They extract records from a source, reshape them, and load them into a target store. That's the full scope. When the job finishes, ETL's job is done.
Orchestration picks up where ETL stops. It answers questions ETL cannot: What runs after this job completes? What happens if the upstream API is slow? Which downstream models depend on this table being up to date? An orchestrator maintains the dependency graph for your entire stack, not just a single pipeline.
Overlap zones: transformation, scheduling, and lineage
The confusion is understandable. Modern ETL platforms have added scheduling UIs. Some orchestrators include lightweight transformation steps. Both categories produce logs. But the overlap is surface-level. ETL scheduling is designed for a single tool's jobs; orchestration scheduling coordinates jobs across multiple tools simultaneously. Lineage in ETL tracks column-level transformations; orchestration lineage tracks which upstream jobs fed which downstream jobs across your entire stack.
When you need both—and when ETL alone is enough
A single-source, single-destination pipeline refreshed nightly? ETL alone handles it. The moment you have more than two dependent jobs, multiple data sources feeding a shared model, or any real-time trigger requirement, you need an orchestration layer on top.
In practice, most teams run ETL tools inside an orchestrator—Fivetran or Airbyte handles ingestion, dbt handles transformation, and Apache Airflow or Dagster sequences the whole workflow.
Data Orchestration Tool Comparison
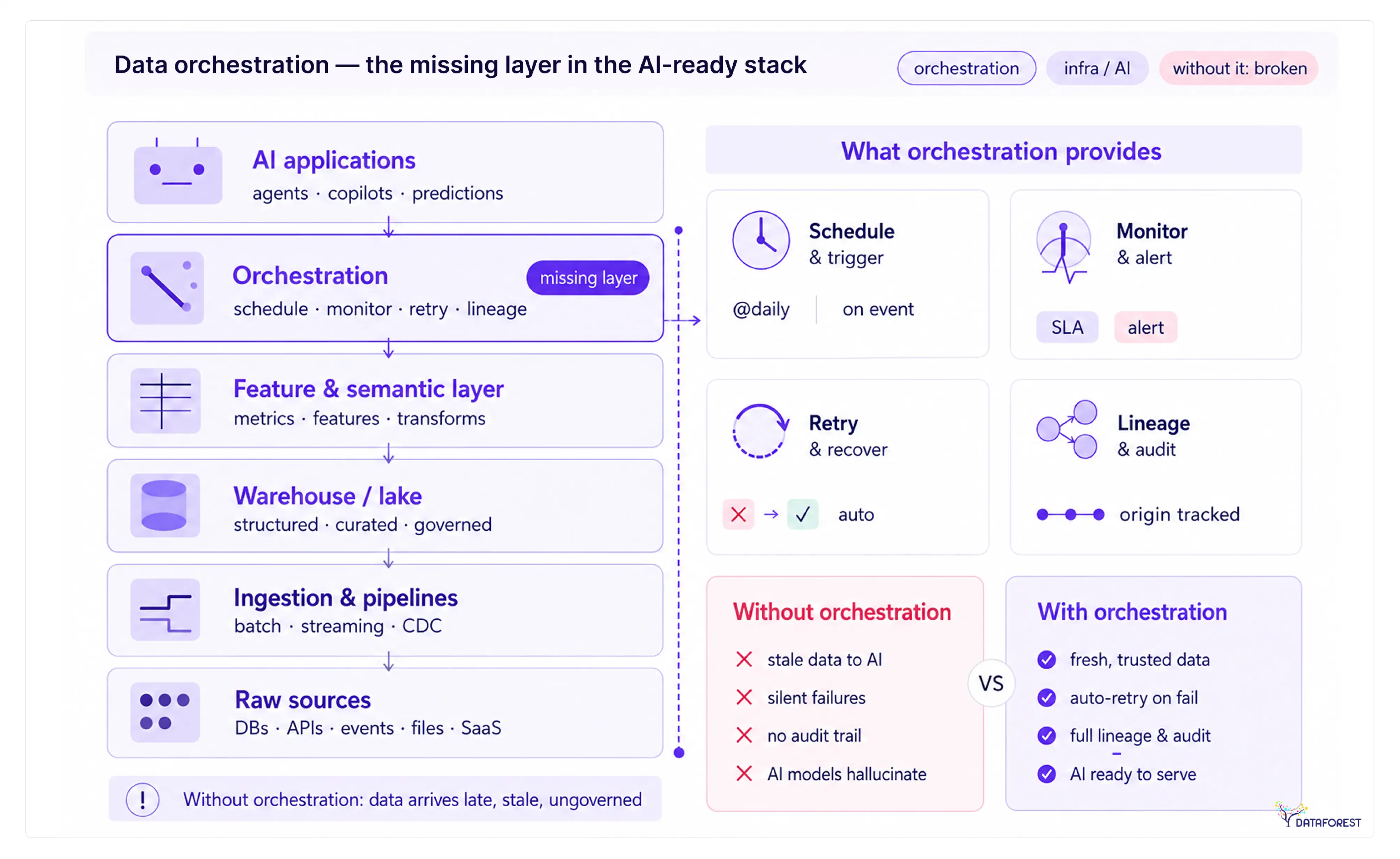
Data Orchestration and AI Pipelines: Why This Layer Can't Be Skipped
Every AI initiative eventually hits the same wall: the models are ready, the infrastructure is provisioned, and the data is a mess. Without an orchestration layer, an AI system is just a collection of scripts that occasionally produce the right output.
To understand why, consider where orchestration sits in a modern AI-ready stack:

Orchestration is the control plane that makes every layer below the model reliable enough to trust—not a peripheral add-on.In practice, orchestration becomes the operational backbone of an AI-Ready Data Infrastructure, ensuring that ingestion, transformation, feature engineering, and model-serving layers remain synchronized, observable, and resilient under production workloads.
LLM pipelines depend on data arriving in the right shape at the right time
Large language models are sensitive to the quality of context. A retrieval-augmented generation (RAG) pipeline, for example, requires that document embeddings are up-to-date, consistently chunked, and indexed before a query arrives. If the embedding job runs late or the chunking logic changes without updating downstream dependencies, the model answers from a stale or malformed context, and the failure is silent.
Orchestration enforces the sequencing: embeddings refresh only after source documents are validated; the vector index rebuilds only after embeddings complete. Without those dependency contracts, you are relying on coincidental timing rather than a guaranteed order.
Feature engineering and model retraining workflows
Feature pipelines are among the most dependency-heavy workloads in any ML system. A single feature—say, a 30-day rolling average of user activity—may depend on raw event data, a deduplication job, a join against a user dimension table, and a quality check before it is safe to write to the feature store.
Orchestration handles that dependency graph explicitly - including retraining schedules. A model retrain fires when upstream feature distributions drift, not on a fixed cron that ignores data state. Teams that skip this layer typically discover the problem when a model degrades in production, and no one can trace back to the upstream job that produced the bad features.
Agentic AI: why autonomous agents need deterministic data contracts
Agentic AI systems—where models plan, call tools, and act across multiple steps—raise the stakes considerably. An agent that queries a customer database, writes a summary, and triggers a downstream action needs to know that the data it reads is consistent and current. If the underlying tables are partially updated mid-run, the agent operates on an incoherent snapshot.
Deterministic data contracts, enforced by the orchestration layer, define what state data must be in before an agent is allowed to consume it. This is not optional for production agentic systems. It is the difference between an agent that is auditable and one that is unpredictable.
What breaks without orchestration in an AI stack
The failure modes are predictable:
- Silent staleness. Models consume outdated data because no system enforces a freshness check before serving.
- Partial updates. A downstream job reads a table mid-write, producing results that are neither the old state nor the new one.
- Untraceable errors. When a model produces a bad output, there is no lineage to identify which upstream job introduced the problem.
- Brittle scheduling. Cron jobs run on fixed intervals regardless of whether dependencies have completed, causing race conditions under load.
None of these failures announces itself loudly. They surface as model drift, inconsistent outputs, or user complaints—long after the root cause has been overwritten. Orchestration makes these failure modes visible and preventable before they reach the model layer.

The Business Case for Data Orchestration: What the Numbers Say
Most infrastructure investments get sold on efficiency. Data orchestration is different—the business case is about preventing the kind of silent failures that corrupt analytics, delay model retraining, and surface bad data to decision-makers before anyone notices.
Forrester TEI findings: ROI, infrastructure savings, and downtime reduction
A Forrester Total Economic Impact study commissioned by Astronomer found a 438% ROI within six months, 75% less infrastructure management effort, and a 70% reduction in critical services downtime. Those three numbers tell a coherent story: engineering teams spend less time keeping pipelines alive, and the pipelines that do run are far less likely to take production services down with them.
The 75% infrastructure reduction is the figure that surprises most engineering leaders. It reflects what happens when you replace a patchwork of cron jobs, custom retry logic, and ad-hoc monitoring scripts with a single orchestration layer that handles it all natively. The work doesn't disappear—it shifts from reactive firefighting to deliberate pipeline design.
The hidden cost of DIY orchestration and cron-script sprawl
Cron scripts are not a free solution. They are deferred costs that compound with every new data source you add.
The pattern is predictable: a team writes a shell script to move data between two systems. It works. Six months later, there are forty scripts, no shared retry logic, no dependency tracking, and no one person who understands the full execution graph. When a pipeline fails at 2 a.m., the on-call engineer spends an hour reconstructing what ran, in what order, and why it stopped—instead of reading a structured failure log.
This is technical debt with a direct operational cost. Every hour spent debugging undocumented glue code is an hour not spent on feature work or model improvements. The Forrester findings quantify what practitioners already know: the DIY approach is expensive once you account for incident response, maintenance overhead, and the engineering time lost to coordination work.
Real-world outcomes: smava and HIVED
Two named case studies ground the Forrester numbers in specific outcomes.
German fintech smava achieved zero downtime and automated generation of over 1,000 dbt models after migrating to Dagster. Maintenance overhead dropped, and developer onboarding fell from weeks to 15 minutes. The onboarding reduction alone has compounding value: every new data engineer reaches full productivity in a single afternoon instead of spending weeks reverse-engineering undocumented pipelines.
UK logistics company HIVED achieved 99.9% pipeline reliability with Dagster. For a logistics operation where route optimization and delivery tracking depend on fresh data, that reliability threshold is the difference between a functional data product and one that requires constant manual intervention.
Both cases show a return within months: reliability improvements that protect revenue, and onboarding reductions that compound as teams grow.
Key Components of a Data Orchestration Platform
Most teams discover what a data orchestration platform actually does by watching what breaks when one component is missing. A scheduler fires a job before its upstream dependency finishes. A failed task retries silently and corrupts a feature store. A governance gap lets raw PII flow into a model training set. Each failure traces back to a specific platform layer—and understanding those layers tells you exactly what to evaluate before you buy or build.
The five components below map directly to the three-stage orchestration process: Organize → Transform → Activate. The scheduler and dependency graph handle Organize. Transformation logic and error handling cover Transform. Monitoring and governance close the loop at Activate.
Scheduler and trigger engine
The scheduler determines when work runs. Mature platforms support cron-based schedules, event-driven triggers (a file lands in S3, a Kafka topic crosses a threshold), and sensor-based polling. For AI pipelines specifically, event-driven triggers matter more than fixed schedules—model retraining should fire when data drift is detected, not at midnight on Sundays, regardless of the data state.
Dependency graph and DAG execution
A directed acyclic graph (DAG) encodes the order in which tasks must run and which tasks can run in parallel. Without explicit dependency modeling, you are back to cron scripts with no awareness of upstream failures. For LLM pipelines and feature-engineering workflows, DAG execution enforces the data contracts that agentic AI systems depend on—a downstream task cannot start if its inputs are incomplete or stale.
Monitoring, alerting, and observability
Observability goes beyond "did the job succeed?" It answers: how long each task took, how much data passed through, and where in the DAG the latency spiked. Teams running real-time pipelines need task-level metrics, not just pipeline-level pass/fail. Alerting should route to the team that owns the failing task—not a generic inbox that everyone ignores.
Error handling and retry logic
Retry logic without backoff is a denial-of-service attack on your own infrastructure. Production-grade platforms let you configure per-task retry counts, exponential backoff intervals, and dead-letter queues for tasks that exhaust retries. Ownership boundaries matter here: the platform handles mechanical retries; a human engineer owns the escalation path when retries are exhausted.
Governance, data quality checks, and access controls
This is the component most teams bolt on after a compliance incident rather than building in from the start. Building governance from the start is cheaper than retrofitting it after a compliance incident. Governance hooks embedded in the orchestration layer—schema validation before a task runs, row-count assertions after a load, column-level access controls on sensitive fields—catch data quality failures before they reach a model or a dashboard.
Component evaluation checklist—use this when assessing any platform:
- Scheduler and trigger engine: supports event-driven and sensor-based triggers, not just cron
- Dependency graph and DAG execution: explicit upstream/downstream dependency modeling with parallel execution support
- Monitoring and alerting: task-level observability with routable alerts by the ownership team
- Error handling and retry logic: configurable per-task retries with backoff and dead-letter handling
- Data quality and governance hooks: inline schema validation, assertions, and column-level access controls
A platform that covers all five handles production workloads. One that covers two or three is a scheduler.

Data Orchestration Tools: A Structured Comparison
Choosing the wrong orchestration tool has consequences beyond onboarding friction—it constrains your architecture for years. The table below maps each major platform to the scenario where it fits best, along with the limitation that most vendors won't document.
Apache Airflow: the incumbent with maintenance overhead
Airflow is the most widely deployed orchestration tool in production today, and that installed base is both its strength and its trap. The DAG-centric model—where you define workflows as directed acyclic graphs of tasks—works well for stable, predictable pipelines. It breaks down when pipelines multiply, teams grow, and you need to understand not just what ran but what data was produced and whether it's trustworthy. Airflow has no native concept of a data asset. Every observability and lineage feature has to be bolted on.
Dagster: asset-centric orchestration for modern stacks
Dagster flips the model. Instead of scheduling tasks, you define software-defined assets—the actual data objects your pipeline produces—and Dagster infers the execution graph from their dependencies. This makes lineage, data quality checks, and partial re-execution first-class features rather than afterthoughts. Teams running dbt, Spark, and ML training jobs in the same pipeline find Dagster's asset model significantly easier to reason about than Airflow's task graph.
Prefect: developer-friendly with a low barrier to entry
Prefect's pitch is simple: take any Python function, add a decorator, and it becomes an observable, retriable workflow. For teams that need orchestration quickly without restructuring their codebase, that's a genuine advantage. Prefect 3 introduced worker-based execution and improved scheduling flexibility. The trade-off is that Prefect's dependency model is less expressive than Dagster's for large, cross-team asset graphs.
Kestra: event-driven and language-agnostic
Kestra is the tool to reach for when your team isn't Python-first. Workflows are defined in YAML and can trigger scripts in any language via Docker containers or plugins. Its event-driven architecture handles real-time triggers—webhooks, message queues, file arrivals—more naturally than Airflow's scheduler-centric design. For organizations running mixed engineering stacks, Kestra removes the Python bottleneck entirely.
Cloud-native options: AWS Step Functions, Google Cloud Composer, Azure Data Factory
Cloud-native tools trade flexibility for operational simplicity. Step Functions excels at serverless, event-driven microservice coordination inside AWS. Cloud Composer gives GCP teams managed Airflow without the infrastructure burden—but you still inherit Airflow's DAG complexity. Azure Data Factory suits enterprise teams that want a low-code interface and tight Azure integration, though code-first teams often find its abstraction layer limiting for sophisticated pipeline logic.
The contrarian case against defaulting to Airflow
Airflow is not the safe default it once was. It became the standard when the alternatives were immature, and that inertia persists long after the tooling changed. In practice, teams that start with Airflow for a greenfield project in 2025 often spend the first six months building the observability, lineage, and data-quality scaffolding that Dagster or Prefect ships out of the box. The maintenance overhead compounds: every new DAG adds complexity to a graph that Airflow has no semantic understanding of. If your team is starting fresh and your pipelines involve ML workflows, customer data orchestration, or real-time triggers, evaluate Dagster and Kestra before defaulting to the incumbent.
Tool evaluation scorecard: When comparing platforms internally, score each tool across five criteria - dependency modeling, observability depth, deployment flexibility, language support, and community maturity. Weigh the criteria by your team's actual constraints, not vendor marketing priorities.

How to Choose a Data Orchestration Platform: Buy vs. Build Decision Framework
Most teams that build their own orchestration layer regret it within eighteen months. The custom scheduler works fine for three pipelines. At thirty, it becomes the thing nobody wants to touch. The buy-vs-build question deserves a structured answer, not a gut call.
When building in-house makes sense (and when it doesn't)
Building makes sense in a narrow set of conditions: your pipelines have genuinely unusual runtime requirements that no existing tool supports, your team has dedicated platform engineers with orchestration experience, and you can commit to ongoing maintenance as a first-class product. That last condition eliminates most teams.
The more common failure mode is building because it feels faster at the start. A few cron jobs and a shared Slack channel for alerts looks like orchestration. It isn't. When a pipeline fails silently at 2 a.m., and nobody notices until a dashboard goes stale, the cost of that shortcut becomes apparent.
Buy vs. build decision matrix: scored criteria
Score each dimension for your situation. Three or more "Build Signals" suggest a custom layer is worth evaluating. Three or more "Buy Signals" mean that a managed or open-source platform will serve you faster and more cheaply.
Managed service vs. self-hosted open-source trade-offs
This is a separate decision from the build-vs-buy one. Even when you choose an established tool like Apache Airflow or Dagster, you still decide whether to run it yourself or use a managed offering such as Astronomer or Dagster Cloud.
Self-hosted open-source gives you full control over infrastructure, data residency, and cost at scale - but you own upgrades, security patches, and incident response. Managed services remove that operational burden and typically include SLAs, but they add vendor dependency and recurring cost.
The practical rule: if your team spends more than a few hours per week keeping the orchestrator itself healthy, the managed service pays for itself in recovered engineering time.
For teams evaluating readiness before committing to either path, the next section provides a structured pre-implementation checklist.
Pre-implementation readiness: 12 checks before you pick a tool
Do this before the vendor demos.
A data orchestration tool will not fix unclear ownership, missing SLAs, messy source inventories, or a team that cannot support the platform it chooses. Those problems follow you into the new tool. Sometimes they get louder there.
Use this checklist to find the boring issues early, while they are still cheap to fix.
If items 3, 6, or 7 are shaky, pause the tool search. Skill fit, monitoring, and alert ownership are not vendor features. They are operating decisions.
Once those are clear, the choice of platform gets much easier. You are no longer asking, "Which tool looks best?" You are asking, "Which tool matches the way our pipelines actually fail?"
Conclusion
What matters is whether anything coordinates your pipelines when an upstream source changes, a model retraining job fires at 2 a.m., or a compliance audit demands a full lineage trace. Without a dedicated orchestration layer, the answer is usually: nobody does, until something breaks.
As AI pipelines chain ingestion, feature engineering, model serving, and activation across multiple systems, uncoordinated data becomes progressively more expensive to fix—and harder to detect before it reaches a model. Teams that skip orchestration typically encounter it again under worse conditions—a failed audit, a degraded model, or a night incident with no lineage to trace.
The available tooling is mature enough that there is no good reason to manage this with cron jobs and custom scripts. Whether you start with a self-hosted open-source scheduler or a managed cloud-native service depends on your team's Python depth, your SLA requirements, and your tolerance for operational overhead—all criteria the buy-vs-build framework in this guide covers directly.
Start there: run your current pipeline inventory against that decision matrix this week, and pick a tool that fits your actual constraints—not the one with the most GitHub stars.
FAQ: Common Questions About Data Orchestration
These questions come up constantly in engineering discussions - often because vendors blur category lines in their marketing.
Is Snowflake a data orchestration tool?
No. Snowflake is a cloud data warehouse built to store and query structured and semi-structured data at scale. It does not schedule pipelines, manage cross-system dependencies, or handle retries across external services. Snowflake's Tasks feature can trigger simple SQL-based workflows inside the warehouse, but that is not orchestration—it is scheduling within a single system. You still need a dedicated orchestration layer to coordinate what flows into and out of Snowflake.
Is Kafka a data orchestration tool?
No. Apache Kafka is a distributed event streaming platform designed to move high-throughput data between systems in real time. It handles message delivery reliably, but it does not model dependencies between pipeline steps, manage retries across heterogeneous systems, or provide workflow-level observability. Kafka is a transport layer. Orchestration sits above it, deciding what to do with the data once it arrives—and what to do when something fails.
What is the difference between data orchestration and data integration?
Data integration is the process of combining data from multiple sources into a unified view—typically through connectors, APIs, or ETL pipelines. Data orchestration is the coordination layer that governs when and how those integration steps run, in what order, with what dependencies, and with what fallback behavior when they fail. Integration moves data; orchestration manages the workflow that makes the movement reliable and repeatable.
How does data orchestration relate to customer data platforms?
Customer data orchestration refers to coordinating the flow of customer data—from CRM, marketing automation, support tools, and behavioral event streams—into a unified profile that downstream systems can act on. A customer data platform (CDP) handles identity resolution and audience segmentation, but it depends on clean, timely data arriving from upstream sources. Data orchestration is what ensures those upstream pipelines run on schedule, handle schema changes gracefully, and alert your team when a source goes silent.


.webp)







