

Your pipeline ran last night. Your dashboard shows stale numbers this morning. Somewhere between the source database and the warehouse, a schema change in an upstream system silently dropped a column—and nothing alerted you.
That is the real problem with ETL pipelines: not the theory, but the gap between a pipeline that works in development and one that holds up in production. Most teams understand the three letters—extract, transform, load—but underestimate how much architectural judgment lives between them. When do you transform before loading versus after? When does a managed connector replace custom code? When does AI assistance help, and when does it introduce new failure modes you haven't planned for?
This guide covers all of it. You will find a clear definition of what an ETL pipeline is and how it differs from a data pipeline; a decision framework for choosing among ETL, ELT, and Zero-ETL; a neutral tool comparison; a runnable Python starting point; and a breakdown of the six failure modes that take down production pipelines. The architecture and tooling landscape shifted meaningfully in 2026, particularly around AI-augmented pipelines, and that context shapes every recommendation here.
If you are building your first pipeline or rethinking one that keeps breaking, start at the beginning. If you already know the mechanics, jump to the architecture decision section.
Key Takeaways
- Treat ETL as a data contract, not plumbing: define the agreement upstream, validate before data lands, and keep schema drift from breaking downstream consumers.
- AI is accelerating the need for cleaner, more connected, and better-governed data pipelines, and the payoff only shows up when data quality and validation are built into the pipeline itself.
- Schema drift is the most frequent production failure mode and the hardest to catch — pipelines that pass every pre-deployment test still break when upstream sources change without warning (see 'ETL Pipeline Failure Modes' above)
- For regulated industries, pre-load transformation is not a preference. It is part of compliance design because validation, governance, and data protection need to happen at ingestion, before downstream consumers rely on the pipeline.
- Low setup complexity trades directly against transformation flexibility — teams needing complex business logic in transit should choose Airflow or dbt, not Fivetran or Airbyte (see 'ETL Pipeline Tools' above)
What Is an ETL Pipeline? (Quick Answer)
An ETL pipeline is a structured sequence of processes that extracts raw data from one or more source systems, transforms it into a consistent, usable format, and loads it into a destination — typically a data warehouse or analytics platform. It is the foundational mechanism that turns scattered, inconsistent source data into something analysts and machine learning models can actually use.
> Quick Answer
> An ETL pipeline extracts data from source systems (databases, APIs, files), applies transformation rules to clean and reshape it, and then loads the result into a target system such as a data warehouse. The three phases run in sequence and are usually automated. As data volumes keep climbing, organizations need pipelines that simplify ingestion, reduce custom maintenance, and validate data before it lands, so downstream systems do not inherit avoidable complexity.
ETL pipeline vs. data pipeline: where the terms diverge
A data pipeline is the broader category — any automated movement of data from point A to point B qualifies. An ETL pipeline is a specific type of data pipeline in which data is transformed before it reaches its destination. The distinction matters in practice: a streaming pipeline that moves raw clickstream events into a data lake is a data pipeline, but not an ETL pipeline unless it applies schema enforcement and business logic in transit.
Why ETL is better understood as a data contract than as plumbing
Most teams treat ETL as infrastructure — pipes and pumps. A more useful frame is a data contract: a formal agreement between data producers (source systems) and data consumers (analysts, dashboards, ML models) about what the data will look like, when it will arrive, and what quality guarantees it carries.
This reframe has real consequences. When an ETL pipeline breaks, the root cause is almost always a violated contract — a source schema changed without notice, a null value appeared where the transform assumed a non-null field, or a load window shifted. Teams that document their ETL pipelines as contracts — specifying expected schemas, acceptable null rates, and SLA windows — catch these failures before downstream consumers do.
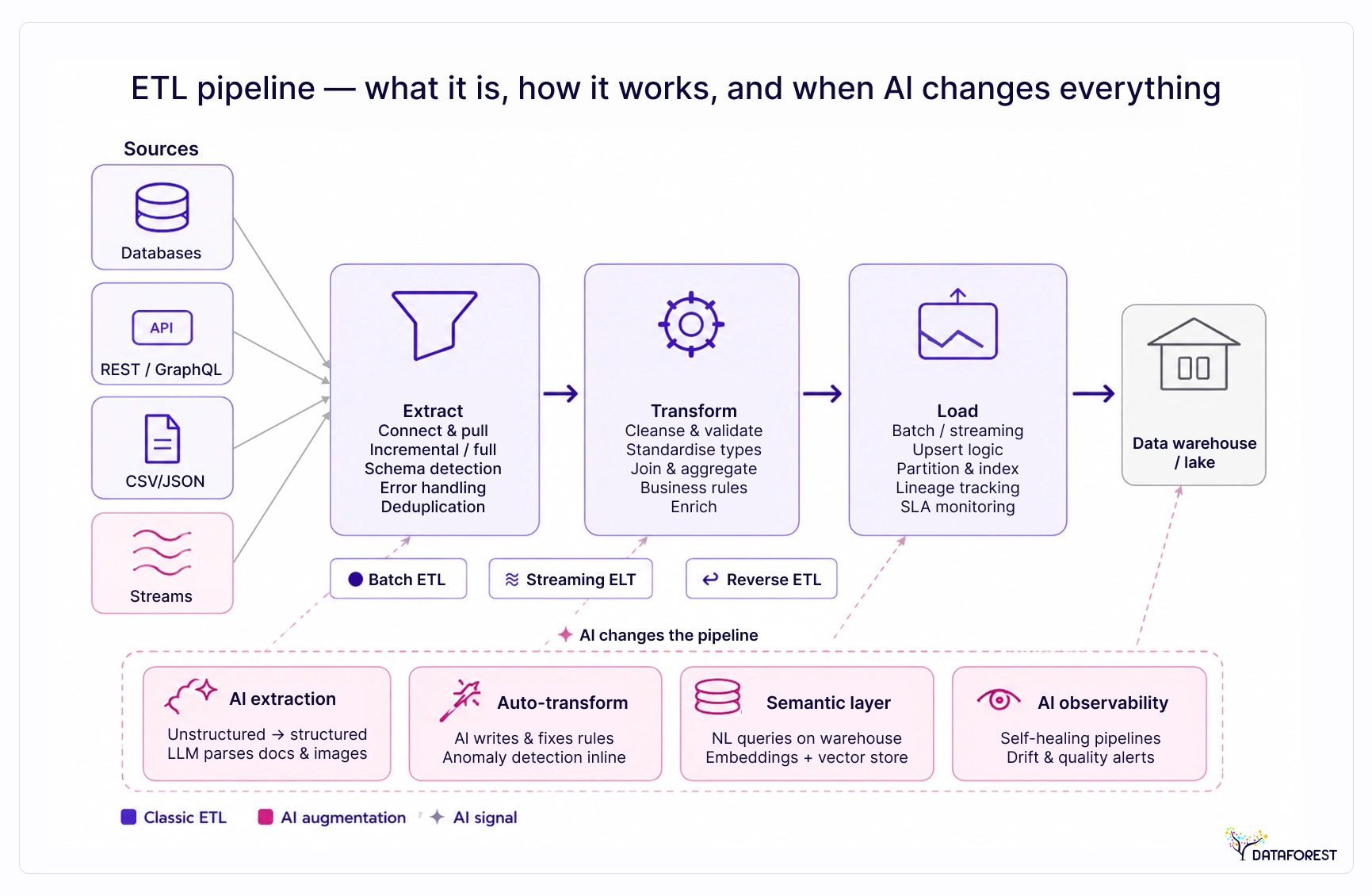
How an ETL Pipeline Works: Extract, Transform, Load
The global data integration market — which includes ETL tools and platforms — was valued at $7.63 billion and is projected to reach $29 billion, according to Integrate.io. That trajectory reflects how central pipeline architecture decisions have become to enterprise data strategy. Getting the three phases right is not a technical nicety; it determines whether downstream analytics, ML models, and reporting are trustworthy.
The ETL Phase Breakdown below maps each phase to its sub-steps, typical inputs and outputs, and the contract obligation each phase must honor.
Extract: connecting to sources and pulling raw data
Extraction is where most pipelines first fail. The source system rarely cooperates: APIs enforce rate limits, databases lock rows during peak hours, and flat-file exports arrive with inconsistent delimiters. A robust extract phase authenticates, queries, paginates, and logs — treating every extraction as potentially incomplete until a row count or checksum confirms otherwise. Incremental extraction (pulling only records that have changed since the last run) reduces the load on source systems and shortens pipeline runtime, but it requires a reliable change-data-capture mechanism or a trustworthy updated_at timestamp.
Transform: cleaning, reshaping, and validating in transit
Transformation is the process by which raw data becomes usable data. This phase handles deduplication, type casting, null handling, and the application of business rules — for example, converting regional currency codes to a standard, or mapping product SKUs across two legacy systems that use different identifiers. Schema validation belongs here, not at the load step. Catching a malformed record before it reaches the warehouse is far cheaper than reprocessing a corrupted table after the fact. Teams that skip inline validation typically discover data quality problems weeks later, when an analyst flags an anomaly in a dashboard.
Load: writing to the destination without breaking downstream consumers
The load phase has one non-negotiable rule: downstream consumers must not break. That means choosing the right write mode — append for event logs, upsert for slowly changing dimensions, full replace only when the dataset is small and the target has no dependencies. If your destination is a legacy on-premises data warehouse, a regulated database with strict schema enforcement, or a system undergoing data migration, ETL is still the right call. Transformation happens before the data touches the target so that sensitive fields can be masked, dropped, or tokenized in transit.
Batch vs. streaming: how timing changes each phase
Batch pipelines run on a schedule — hourly, nightly, or weekly — and process accumulated records in bulk. Streaming pipelines process records continuously, often within seconds of generation. The choice changes each phase: streaming extraction requires a message broker like Kafka or Kinesis rather than a database query; streaming transformation must handle out-of-order events and late arrivals; streaming loads must write to targets that support high-frequency, low-latency writes. Batch works well for reporting and historical analysis. Streaming is necessary when decisions depend on the current state — fraud detection, real-time personalization, or operational dashboards. Most production environments run both, with batch pipelines handling historical backfills and streaming pipelines handling live data.
ETL vs. ELT vs. Zero-ETL: Choosing the Right Architecture
ETL transforms data before it reaches the destination; ELT loads raw data first and transforms it inside the target system using its native compute. The practical difference is where the transformation logic lives and who pays for the compute. ETL suits constrained or regulated targets; ELT suits cloud warehouses with abundant, elastic processing power. Zero-ETL eliminates the pipeline layer entirely by replicating data directly between platforms.
ETL and ELT remain core data-integration patterns for handling large, diverse datasets and building scalable pipelines. That growth reflects how many teams are actively re-evaluating which architecture fits their stack — and getting the choice wrong is expensive.
When ETL still wins: compliance, legacy systems, and constrained targets
If your destination is a legacy on-premises data warehouse, a regulated database with strict schema enforcement, or a system that prohibits loading raw PII, ETL is still the right call. Transformation happens before the data touches the target so that sensitive fields can be masked, dropped, or tokenized in transit. Regulated industries — healthcare, financial services, government — often have no choice here. The target system simply cannot accept unstructured or semi-structured data, and compliance auditors want proof that the transformation occurred before storage.
When ELT makes more sense: cloud warehouses with compute to spare
Cloud platforms like Snowflake, BigQuery, and Redshift are designed to run heavy SQL transformations at scale. Loading raw data first and transforming it in-place with tools like dbt is faster to iterate on, easier to debug, and cheaper when warehouse compute is already provisioned. ELT also preserves the raw source record, which matters when business logic changes and you need to re-derive historical outputs without re-extracting from the source.
The trade-off is real: ELT pushes complexity into the warehouse. Teams without strong SQL discipline accumulate transformation debt quickly.
Zero-ETL and serverless ETL: what they are and when to reach for them
Zero-ETL is a native integration pattern in which two platforms share data without a separate pipeline. Snowflake's data sharing, Amazon Aurora's zero-ETL integration with Redshift, and similar features replicate data at the storage layer rather than moving it through an intermediary. Latency drops to near real-time, and operational overhead shrinks sharply.
Serverless ETL — AWS Glue, Google Dataflow, Azure Data Factory in serverless mode — sits between traditional ETL and Zero-ETL. You write transformation logic, but the platform manages infrastructure. It works well for variable or unpredictable workloads where provisioning a dedicated cluster is wasteful.
Zero-ETL is not a universal replacement. It works only when the source and destination are within the same vendor ecosystem, and it offers limited transformation capability. Complex business logic still needs a pipeline.
Decision tree: matching your constraints to the right pattern
Use this table as the starting point. Answer each criterion honestly — the column with the most matches is your architecture.
ETL vs. ELT vs. Zero-ETL Decision Table
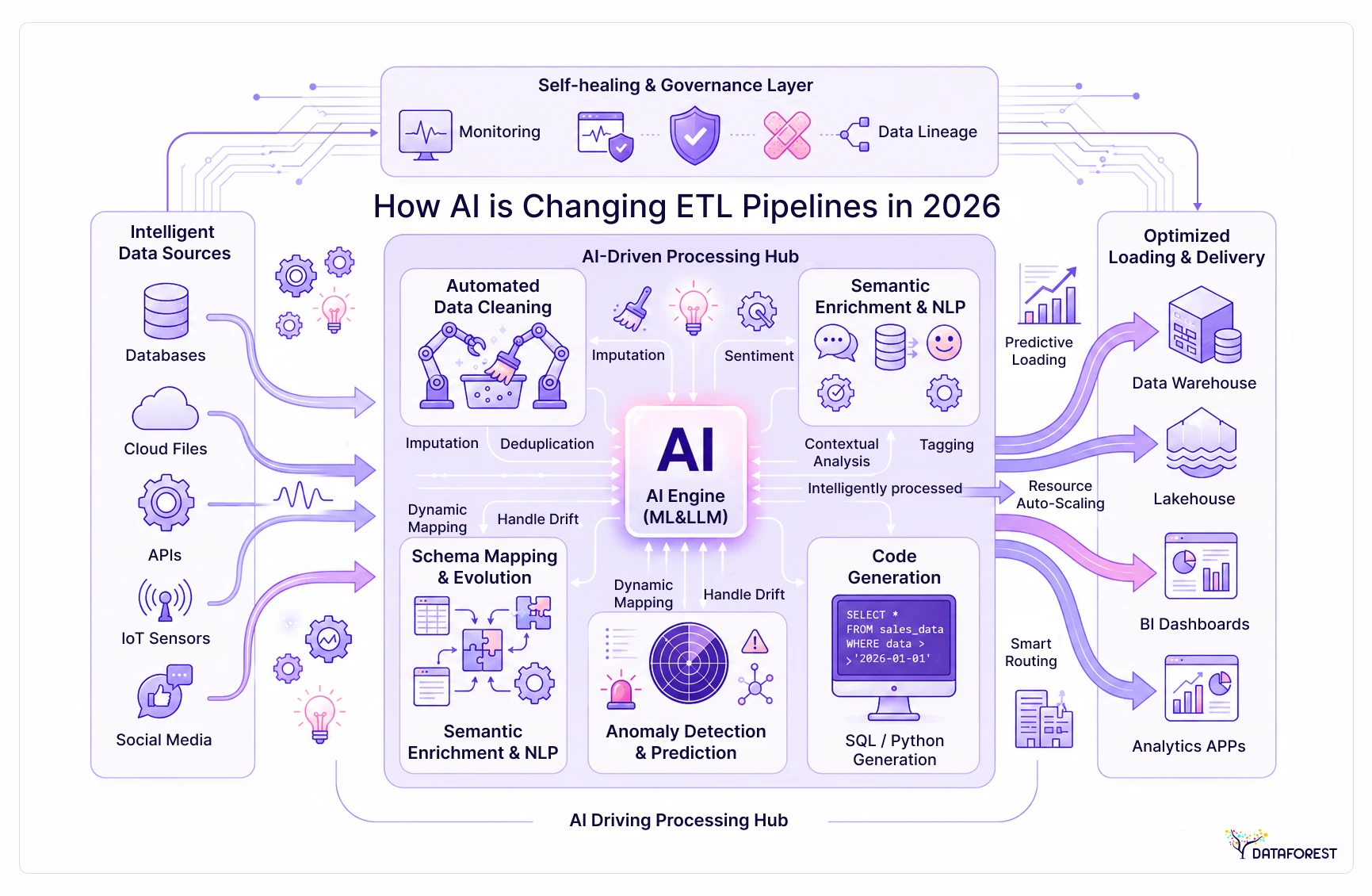
AI Impact Layer Framework
AI is beginning to alter each phase of the ETL pipeline independently. This framework maps where automation is already practical versus where human judgment remains essential.
The AI Impact Layer does not replace the pipeline — it reduces the manual surface area at each phase. Teams still own the business logic, the compliance rules, and the failure recovery playbook. What changes is how much of the scaffolding work gets automated.
How AI Is Changing ETL Pipelines
AI is accelerating the need for cleaner, connected, governed data pipelines, and the payoff only shows up when data quality and validation are built into the pipeline itself.
Traditional ETL pipelines required engineers to hand-code schema definitions, write transformation rules, and manually tune load schedules. AI is replacing or augmenting each of those steps, and the distinction matters for how you architect a pipeline today.
The framework below — the AI Impact Layer Framework — maps AI's role across all three ETL phases. Each phase gets a different kind of AI assist, and conflating them leads to poor tool choices.
AI at the Extract phase: schema inference and anomaly detection
Schema drift — when a source system silently changes a column name or data type — is one of the most common causes of pipeline failure. Historically, catching it required either rigid schema contracts or a human reviewing logs. AI-augmented extract layers now infer schema from sample data at ingestion time and flag statistical anomalies before bad records propagate downstream. Tools like AWS Glue crawlers and Fivetran's schema change detection do this automatically. The practical result is fewer silent failures and faster incident detection.
AI at the Transform phase: LLM-assisted mapping and data quality rules
Field mapping between source and target schemas is tedious and error-prone when done manually. LLMs can now suggest mappings based on column names, sample values, and semantic similarity — cutting the time to configure a new source from hours to minutes in many implementations. Informatica's CLAIRE engine and Matillion's AI-assisted transformation layer both follow this pattern. Beyond mapping, LLMs can generate data quality rules from natural-language descriptions: "flag any order where revenue is negative, or customer ID is null" becomes an executable rule without a developer having to write SQL. This works well for standard business logic but breaks down for domain-specific edge cases that require subject-matter expertise to define.
AI at the Load phase: intelligent routing and adaptive scheduling
Most load configurations are static: run at 2 a.m., write to this table, retry three times on failure. Adaptive scheduling uses historical load patterns and downstream query activity to shift batch windows dynamically — avoiding peak warehouse compute hours and reducing costs. Intelligent routing goes further, directing records to different destinations based on content classification. A pipeline ingesting customer support tickets might route PII-flagged records to a masked table while sending clean records to the analytics layer. Databricks Auto Loader handles volume-adaptive ingestion; purpose-built orchestration tools like Prefect and Dagster are adding similar AI-driven scheduling capabilities.
AI-native vs. AI-augmented pipelines: what the distinction means in practice
Stop treating "AI-powered ETL" as a single category. The difference matters operationally.
AI-augmented pipelines bolt AI capabilities onto an existing ETL architecture — schema inference here, an LLM mapping suggestion there. Most enterprise teams are here today. The underlying pipeline logic remains deterministic; AI assists humans rather than replacing pipeline code.
AI-native pipelines are designed from the ground up around model inference. The transformation layer may itself be a model call — for example, extracting structured data from unstructured documents using a vision or language model. These pipelines introduce non-determinism by design, which creates new governance challenges: the same input can produce different outputs across runs, making lineage tracking and audit trails harder to maintain.
For most teams, AI-augmented is the right starting point. AI-native architectures make sense when the source data is inherently unstructured — documents, images, audio — and no deterministic parsing approach is viable.
ETL Pipeline Failure Modes and How to Recover from Them
Think of an ETL pipeline as a contract between the data producer and the data consumer. Every failure mode is a contract violation — and the damage compounds the longer it goes undetected.
Why production pipelines fail differently from test pipelines
Test environments use clean, stable, small datasets. Production does not. Sources change their schemas without warning. Upstream systems go down at 2 a.m. A marketing campaign drives ten times the normal event volume. None of these conditions appear in a test suite, which is why pipelines that pass every pre-deployment check still break in production. The failure patterns are predictable, though. Naming them precisely is the first step toward catching them early.
The six failure modes: taxonomy and detection signals
The Pipeline Failure Taxonomy below covers the six most common ways ETL pipelines break in production. Each failure mode is distinct — they have different causes, different signals, and different recovery paths.
Recovery steps and prevention practices per failure mode
Two principles cut across all six failure modes. First, idempotency: every pipeline stage should produce the same output when run twice on the same input. Without it, retries create duplicates or partial overwrites that are harder to debug than the original failure. Second, observability at the record level, not just the job level. A job that completes with status "success" can still deliver corrupted data — silent data corruption is the most dangerous failure mode precisely because standard monitoring misses it.
For teams building recovery playbooks, prioritize schema drift and silent data corruption first. Schema drift is the most frequent failure in pipelines that connect to third-party APIs or SaaS sources. Silent data corruption is the costliest because it often goes undetected until a business decision has already been made on bad numbers.
ETL Pipeline Governance: Data Quality, Lineage, and Observability
Bad data loaded cleanly is still bad data — and downstream consumers rarely discover the problem until it has already corrupted a report, a model, or a compliance audit. Governance is the layer that prevents that. It covers three distinct concerns: quality controls that catch problems at ingestion, lineage tracking that records where every record originated, and observability tooling that tells you when something is wrong before a stakeholder does.
Data quality controls: validation rules, null checks, and referential integrity
Quality checks belong at the transform stage, not after load. The practical pattern is a three-tier gate:
- Null checks — reject or quarantine rows where required fields are empty. Define "required" per destination table, not globally.
- Validation rules — range checks, regex patterns, and enum constraints applied per column. A customer age of 400 or a country code of "XX" should fail immediately.
- Referential integrity — confirm that foreign keys resolve before writing. Loading an order record whose customer_id doesn't exist in the customers table creates orphaned rows that silently break joins.
Teams that skip these pipeline-level gates push the problem into the warehouse, where fixing it requires reprocessing historical data — a far more expensive operation.
Schema drift detection and schema evolution strategies
Schema drift is one of the most common silent failure modes in production ETL. An upstream team renames a column, adds a nullable field, or changes a data type — and your pipeline either breaks loudly or, worse, continues loading with nulls where values should be.
The two practical responses are detection and evolution. Detection means comparing the incoming schema against a stored contract on every run and alerting when they diverge. Evolution means deciding in advance which changes are backward-compatible (e.g., adding a nullable column) versus breaking changes (e.g., renaming or removing a column). Tools like dbt and Great Expectations natively support schema contract testing. The key discipline is treating schema changes as a deployment event, not an operational surprise.
Data lineage tracking: knowing where every record came from
Lineage answers the question regulators and data teams both ask: where did this number come from? A complete lineage graph maps each field in the destination back through every transformation to its source system, including timestamps and pipeline version. In regulated industries — BFSI, healthcare — lineage is not optional. For regulated industries, pre-load transformation is not a preference. It is part of compliance design because validation, governance, and data protection need to happen at ingestion, before downstream consumers rely on the pipeline. Apache Atlas, OpenLineage, and Marquez are the most widely adopted open standards for capturing lineage metadata across heterogeneous pipelines.
SLA monitoring and alerting for pipeline health
An ETL pipeline without SLA monitoring is a pipeline you learn about from angry users. Define three observable thresholds for every pipeline: expected completion time, acceptable row-count variance from the previous run, and maximum tolerable error rate. Alert on all three.
Observability platforms like Monte Carlo, Bigeye, and Metaplane sit between the pipeline and the warehouse, running automated anomaly detection on freshness, volume, and distribution. The pattern we see in mature data teams is a tiered alert structure: a missed completion window pages on-call; a row count drop below the threshold creates a ticket; a distribution shift triggers a data quality incident review.
Governance is not a feature you add later. Build the quality gates, schema contracts, lineage hooks, and SLA monitors before the pipeline reaches production — retrofitting them onto a live pipeline is significantly harder than designing them in from the start.

ETL Pipeline Tools: How to Choose Without the Vendor Bias
Common ETL pipeline examples include pulling CRM records into a data warehouse nightly, syncing e-commerce transactions into a reporting database, moving IoT sensor readings into a time-series store, and replicating ERP data into a cloud analytics platform. Each represents a distinct pattern — batch vs. streaming, structured vs. semi-structured — and the right tool depends on which pattern you're running.
Most tool comparisons are written by vendors or by analysts with vendor relationships. The scoring criteria below are explicit so that you can weight them differently for your context.
Scoring criteria: what actually matters when selecting a tool
Five criteria drive most tool selection decisions in practice:
- Setup Complexity — how long before a pipeline runs in production, including connector configuration and infrastructure provisioning
- Scalability — whether the tool handles volume growth without re-architecture
- Cost Model — fixed license, consumption-based, or open-source with infrastructure costs
- Transformation Flexibility — whether you can express complex business logic, not just column mapping
- Observability Support — native alerting, lineage, and failure visibility without bolting on a third tool
Cloud-based data integration and ETL are becoming the default pattern for modern hybrid and multicloud environments, with services such as Azure Data Factory and AWS Glue positioned as managed cloud platforms for ETL, ELT, and broader data integration. That shift matters for cost model evaluation: consumption-based pricing is increasingly the default, and Informatica's cloud annual recurring revenue rose 37% after it shifted to pay-as-you-go, consumption-based billing tiers — a signal that teams are moving away from fixed-seat licenses.
Open-source tools: Apache Airflow, dbt, Singer
Apache Airflow orchestrates pipelines as directed acyclic graphs. It gives you full control but requires infrastructure management and Python knowledge. dbt specifically handles the transform layer — it runs SQL-based transformations in your warehouse and has become the standard for analytics engineering teams. Singer is a lightweight open protocol for building connectors; it's useful when you need a custom source that no managed tool supports.
Cloud-native tools: AWS Glue, Google Dataflow, Azure Data Factory
These tools are tightly integrated with their respective cloud ecosystems. AWS Glue handles serverless Spark jobs and works well when your data already lives in S3. Google Dataflow runs Apache Beam pipelines and natively supports both batch and streaming. Azure Data Factory is the orchestration layer for Microsoft-stack shops, with strong connectors to Dynamics 365 and SQL Server — making it a natural fit for teams building an ETL pipeline from Dynamics 365 to Snowflake.
Enterprise tools: Informatica, Talend, IBM DataStage
These platforms target regulated industries and large-scale environments where governance, lineage, and support SLAs matter more than cost. Informatica's CLAIRE AI layer adds metadata-driven automation. IBM DataStage is common in BFSI environments where mainframe source systems remain in use. The trade-off is setup complexity and licensing cost — both are high.
No-code and low-code tools: Fivetran, Airbyte, Stitch
Fivetran and Airbyte focus on the extract-and-load portion of the pipeline, leaving transformation to dbt or warehouse-native SQL. Fivetran is fully managed with minimal configuration; Airbyte is open-source with a cloud option, giving you more control over connector customization. Stitch (now part of Talend) is simpler still, suited to smaller teams that need fast connector coverage without engineering overhead.
Tool selection decision table: matching tool category to your context
The pattern here is clear: low setup complexity trades against transformation flexibility. Teams that need complex business logic in transit should lean toward Airflow or dbt. Teams that need fast connector coverage and are comfortable performing transformations within the warehouse should start with Fivetran or Airbyte.
ETL Pipeline Implementation Checklist
- Set up a virtual environment and pin dependency versions
- Store credentials in environment variables, not source code
- Implement connection retry logic with exponential backoff
- Log row counts at Extract, Transform, and Load boundaries
- Validate schema on ingest before transformation begins
- Write idempotent Load functions (upsert, not blind insert)
- Add a dry-run mode that validates without writing to the target
- Unit-test each phase function independently
- Run integration tests against a staging replica of the target
- Set up pipeline run alerts for failures and SLA breaches
- Document source-to-target field mappings in a data dictionary
- Schedule a quarterly review of transformation logic against upstream schema changes
ETL Pipeline Governance Checklist
- Define schema contracts at ingestion
- Implement null and type validation at Extract
- Set up schema drift alerts before Transform
- Log row counts and checksums at each phase boundary
- Track data lineage from source to destination
- Configure SLA breach alerts with on-call routing
- Test transformation logic against production-representative samples
- Document data ownership and stewardship per pipeline
- Run idempotency checks before each Load
- Schedule quarterly pipeline audits
12 ETL Pipeline Best Practices
- Design every Load operation to be idempotent
- Version control all transformation logic alongside application code
- Treat schema changes as breaking changes requiring a migration plan
- Implement data lineage tracking from source to destination
- Set row-count and checksum assertions at each phase boundary
- Use schema drift detection alerts before transformation runs
- Build retry logic with exponential backoff into every connector
- Define and monitor SLA thresholds for each pipeline run
- Partition large datasets to limit the blast radius on failure
- Isolate transformation environments from production sources
- Document data ownership and stewardship for every pipeline
- Audit transformation logic quarterly against upstream schema changes
The Business Case for ETL Investment
Pipeline infrastructure is becoming a strategic investment rather than a discretionary IT item, as cloud data platforms and managed integration services reduce pipeline complexity, support hybrid environments, and improve governance and data accessibility. AI is accelerating the need for cleaner, more connected, and better-governed data pipelines, and the payoff only shows up when data quality and validation are built into the pipeline itself. That trajectory reflects a straightforward reality: organizations that cannot reliably move clean data cannot compete in analytics, AI, or operational efficiency.
Market context: where the data integration industry is heading
Cloud-based ETL and data integration are now the default pattern for modern analytics platforms, with managed services such as Azure Data Factory, Microsoft Fabric, AWS Glue, and AWS zero-ETL reducing pipeline complexity and supporting end-to-end data workflows across hybrid environments. The shift toward managed cloud ETL reduces the upfront infrastructure burden, but it does not eliminate the need for deliberate pipeline design — it just moves the complexity from servers to configuration and governance.
Cloud data integration is becoming the default for ETL because managed services automate movement and transformation, reduce pipeline complexity, and support hybrid environments.This shift is also driving investment in scalable AI data infrastructure, where organizations increasingly rely on data platform development service to build environments that support both traditional analytics workloads and AI-driven applications with strict requirements for quality, latency, and governance. Smaller organizations are entering the market faster, often through low-code tools, which lower the barrier to entry but raise the risk of poorly governed pipelines at scale.
Cost of bad data vs. cost of pipeline infrastructure
The cost argument for ETL is not about the pipeline itself — it is about what happens without one. Downstream analytics built on unvalidated data produce decisions that are confidently wrong. The cost of fixing a poorly trained model on corrupted data dwarfs the cost of the validation logic that would have caught the problem at load time.
ETL ROI for regulated industries
In regulated industries, the real ROI comes from auditability: cloud data platforms increasingly pair ETL with audit logs, data-loss prevention, and unified observability to support compliance, while healthcare and financial services continue to push harder on digital transformation and data modernization.
Compliance-first ETL: why GDPR, HIPAA, and SOC 2 favor pre-load transformation
GDPR, HIPAA, and SOC 2 share a structural requirement: sensitive data must be handled correctly before it reaches a queryable store, not after. ELT loads raw data first and transforms later, which means PII can sit in a warehouse in unmasked form while the transformation jobs queue. ETL's pre-load transformation model eliminates that window.
That growth reflects how central pipeline infrastructure has become to every data-driven organization. The question is no longer whether to invest in ETL, but which architecture fits your constraints.

ETL Pipeline Best Practices: 12 Rules for Production Reliability
Most ETL pipelines fail not because the logic is wrong but because the engineering assumptions don't survive contact with production. These 12 rules address the failure patterns that appear repeatedly once a pipeline moves beyond a controlled test environment.
Design for idempotency from day one
Rule 1: Every pipeline run must produce the same result if re-run on the same input. Use upsert semantics (INSERT ... ON CONFLICT DO UPDATE) rather than plain inserts. If a run fails halfway through, re-running it should not duplicate records or corrupt aggregates.
Rule 2: Use surrogate keys or content hashes to detect duplicate records at the load stage. Relying on source-system IDs alone is not enough — sources change ID schemes, merge records, and backfill historical data.
Rule 3: Parameterize every run by a time window or batch ID. A pipeline that processes "yesterday's data" implicitly is harder to replay than one that accepts --start 2025-06-01 --end 2025-06-02 as explicit arguments.
Treat schema changes as breaking changes
Rule 4: Version your schemas alongside your pipeline code. Renaming a column in the source is a breaking change for every downstream consumer. Track schema versions in a registry and gate deployments on schema compatibility checks.
Rule 5: Fail loudly on unexpected schema drift rather than silently coercing types. Silent coercion — casting a string "N/A" to NULL without alerting anyone — is how bad data reaches dashboards undetected for weeks.
Rule 6: Maintain a schema changelog. When an analyst asks why a metric changed last Tuesday, the changelog is the first place to look.
Build observability in, not on
Rule 7: Emit structured logs at every phase boundary — extract complete, transform complete, load complete — with row counts and timing. Bolting on monitoring after the fact means you instrument what's easy, not what matters.
Rule 8: Define SLA thresholds before go-live and alert on breach, not on failure alone. A pipeline that completes but takes four times longer than expected is a leading indicator of upstream volume changes or infrastructure degradation.
Rule 9: Track data freshness as a first-class metric. The row count and error rate indicate whether the pipeline ran. Freshness tells you whether the data is actually usable.
Plan for failure recovery before the first deployment
Rule 10: Document the recovery procedure for each failure mode before the pipeline goes live. Teams that write runbooks after an incident write them under pressure and miss edge cases. Write them during design.
Rule 11: Test your recovery path, not just your happy path. Kill the pipeline mid-run in a staging environment and verify that re-running it produces a clean result. If you have never tested recovery, you do not have a recovery plan — you have a hypothesis.
Additional practices: lineage, partitioning, and cost controls
Rule 12: Partition large datasets by date or natural key, isolate pipeline environments, and track lineage from source to destination. Partitioning limits the blast radius of a failed run to a single time slice. Environment isolation prevents a development pipeline from touching production data. Lineage tracking — even a simple source-to-target map — cuts mean time to diagnosis when something breaks.
The growth means more teams are building pipelines for the first time. Getting these 12 rules right from the start is far cheaper than retrofitting them after your first production incident.
Frequently Asked Questions About ETL Pipelines
What is an ETL pipeline in simple terms?
An ETL pipeline moves data from where it lives to where it needs to be — cleaning and reshaping it along the way. You pull raw records from a source (a database, an API, or a file), apply rules to make the data consistent and trustworthy, and then write it to a destination system, such as a data warehouse. The result is structured, reliable data that analysts and applications can actually use.
What is the difference between an ETL pipeline and a data pipeline?
A data pipeline is the broader category — any automated process that moves data from point A to point B. An ETL pipeline is a specific type of data pipeline that follows the extract-transform-load sequence, meaning transformation happens before the data reaches its destination. Some data pipelines skip transformation entirely, or defer it until after loading (ELT). Every ETL pipeline is a data pipeline, but not every data pipeline is an ETL pipeline.
What are examples of ETL pipelines?
Common real-world examples include: pulling nightly sales transactions from a PostgreSQL database, standardizing currency and date formats, then loading the result into Snowflake for reporting; ingesting clickstream events from a web application via Kafka, filtering bot traffic, and writing clean sessions to a data lake; and extracting patient records from multiple hospital systems, applying HIPAA-compliant masking rules, then loading into a centralized analytics platform. Each follows the same three-phase logic, even though the tools and cadence differ.
Is ETL still relevant when most warehouses support ELT?
Yes — and the answer depends on your constraints, not the trend. ETL remains the right choice when you must mask or drop sensitive fields before data ever reaches the warehouse, when your target system has limited compute for in-warehouse transformation, or when you're integrating with legacy systems that require strict schema conformance on arrival. ELT wins when your warehouse has abundant compute, and your team is fluent in SQL-based transformation. The two patterns coexist in most mature data stacks.
How long does it take to build an ETL pipeline?
It depends heavily on the source's complexity and the team's experience. A simple pipeline connecting one well-documented API to a cloud warehouse can be production-ready in a few days. A pipeline integrating multiple legacy systems with inconsistent schemas, custom transformation logic, and compliance requirements typically takes several weeks. The build time is rarely the bottleneck — schema drift, access permissions, and stakeholder alignment on data definitions usually are.
What is the hardest part of maintaining an ETL pipeline in production?
Schema drift. Upstream sources change without warning — a vendor renames a field, a new column appears, a data type shifts from integer to string. Your pipeline either breaks loudly or, worse, silently passes malformed data downstream. Teams that have deployed robust pipelines treat schema validation as a first-class concern: they define expected schemas explicitly, alert on any deviation, and version their transformation logic so rollbacks are possible. Monitoring for silent data quality failures is harder than monitoring for crashes, and it causes more business damage when missed.
Conclusion
ETL pipelines were never just plumbing. The real challenge is treating them as a contract between your data sources and every downstream system that depends on them — and that contract breaks in predictable ways when you ignore schema drift, skip idempotency, or bolt observability on after the fact.
The architecture choices ahead are getting sharper, not simpler. AI-augmented tooling is moving schema inference and anomaly detection out of manual engineering work and into the pipeline itself. Zero-ETL connectors are collapsing latency for specific source-destination pairs. But neither trend eliminates the need for deliberate design — they just raise the cost of getting the fundamentals wrong.
For regulated industries, especially, pre-load transformation remains the safer default. The compliance constraints that make ETL feel slow are the same ones that protect you when an auditor asks where a record came from.
Start with one pipeline. Pick a source you already understand, implement the idempotent load pattern from the Python skeleton in this guide, add row-count and freshness alerts from day one, and treat the first schema change as a drill for your recovery process.


.webp)







