

A regional hospital network faced delays in patient data processing. They built a Databricks data lakehouse to combine patient records and lab results from three different clinics. Doctors now find patient histories in two seconds. This change reduced medical errors by 15% a year. Book a call, and we will show you the plan for your Databricks data lakehouse.
Why Is Your Data Architecture Failing Your AI?
Old systems stall business growth and many daily engineering tasks. Corporate leaders need live facts for smart models and fast choices. Fix your messy silos for cost savings this year.
Why traditional architectures hold enterprises back
Traditional data warehouses store structured data and ignore video or audio files. Teams must move unstructured data into a separate data lake using complex ETL vs ELT pipelines. They become messy piles of files without clear labels. Engineers spend 60% of their time moving files between these systems. These silos create two versions of the same facts for company leaders. High storage fees and maintenance costs drain the annual budget. Numbers stay trapped in these old tools and stop company growth.
The growing demand for real-time data
Modern companies now need info that updates in seconds. AI agents require fresh facts to make smart choices. Old batch systems only move files every few hours. These slow pipelines keep AI models behind the fast market. Managers lose money when they train models on old data. Traditional silos stop teams from using video and audio files. CIOs will spend 3.4 trillion dollars this year to fix these gaps.
Improving Chatbot Builder with AI Agents


Improve chatbot efficiency and usability with AI Agent
How Can Databricks Data Lakehouse Benefit Your Business?
The Databricks data lakehouse reduces your annual cloud bill by a third. Organizations can deliver up to three AI projects from a single, secure repository. Security teams can detect leaks in three minutes with automated logs. You can also schedule a call with us to do the same.
Fast results for every department
Sales and marketing teams can see the same numbers in a single Databricks data lakehouse. Analysts no longer need to wait for IT staff to move large files. This shared feature helps managers understand customer behavior. District managers manage complex reports in minutes instead of days. Employees share this information with the board to quickly transfer funds. Fast responses drive sales and lower costs.
AI gets better with added data
AI models need new data to make accurate sales predictions this year. Engineers build these models on the Databricks data lakehouse for better speed. The system stores text, video, and audio files on a server. Scientists spend 80% of their coding efforts on AI. The database of the integrated info eliminates the problem of outdated or unintended visual effects. Companies deliver three times more AI projects to customers each quarter.
Low cost, easy to scale
Companies pay separately for storage and analytics in the Databricks data lakehouse. Companies only pay for the exact power they use. IT leaders are reducing cloud bills by 30% this year. The system grows with your data, avoiding complete rebuilds. Analysts scale up for busy mornings and scale down for quiet nights. You can avoid the high costs of buying multiple devices from different vendors.
Improved security rules and files
A central location for all your info will help your team track every file entry. Your analysts set clear rules for identifying the customer's personal information. Databricks data lakehouse records every change to your organization's files. Security teams detect leaks in minutes with these automated logs. This system is GDPR and HIPAA compliant for your legal team. You avoid large fees and protect the safety of your corporate brand.
Medium: Why lakehouses replace the lakes? Data lakes failed on governance and usability—teams lost track of datasets, quality degraded, and discovery became slow and manual. Lakehouse adds structure without losing flexibility—ACID transactions, metadata layers, and indexing restore control. One platform replaces fragmented tooling: Lakehouse reduces tool switching and integration overhead.
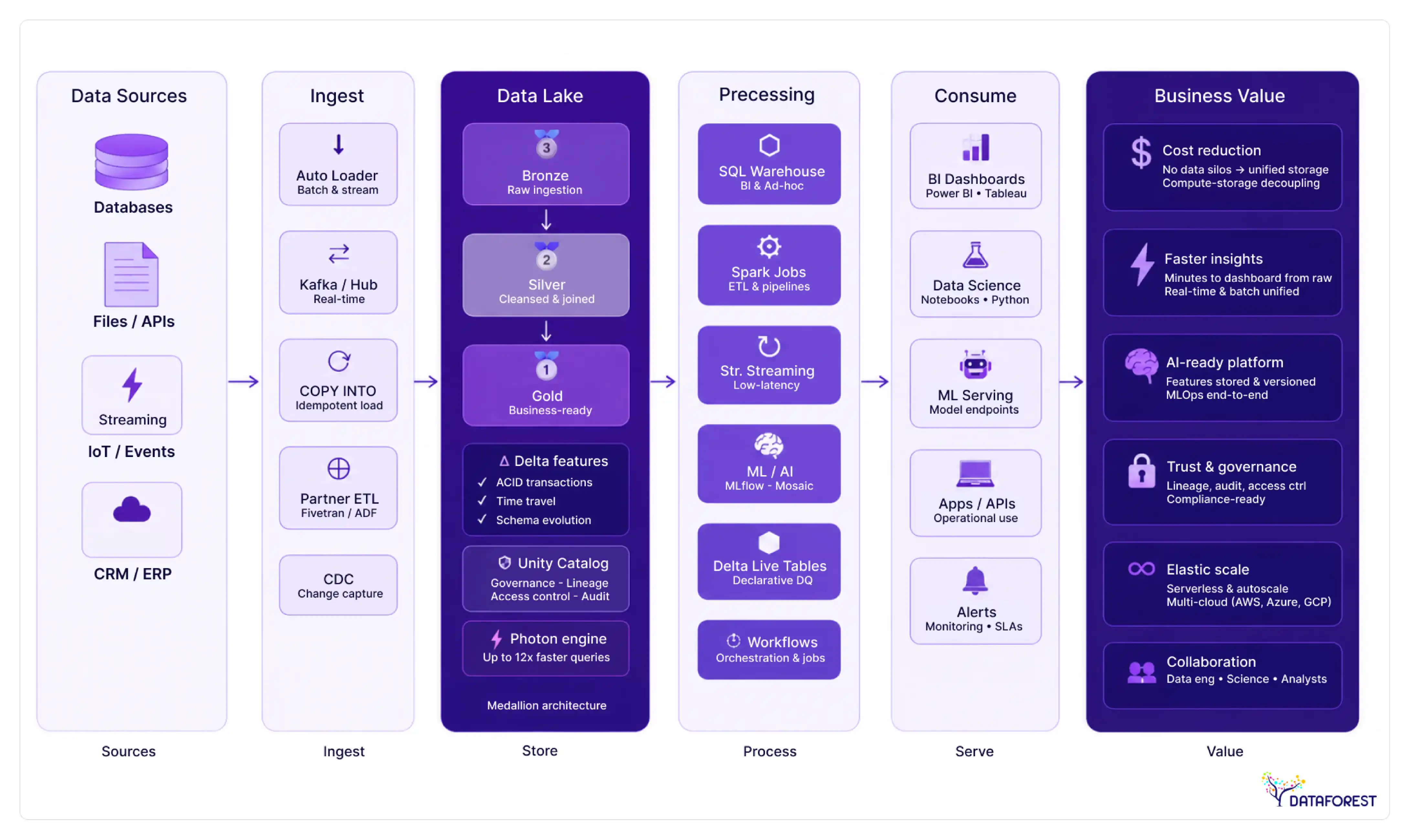
How does the Databricks Lakehouse architecture work?
The Databricks Lakehouse Architecture uses five layers to manage your organization's files and AI models. This system pulls numbers from multiple sources and stores them in a single Delta Lake server. The Unity Catalog defines security rules for hundreds of user roles and tracks every file change.
The ingestion
It transfers files from multiple sources to your cloud storage. Auto Loader pulls new files into the system without manual intervention. Your engineers build pipelines to capture info from web applications and local servers. This class cleans complex files before they reach your main warehouse. Fast Food keeps track of your sales records and inventory for the entire company.
The storage layer
Delta Lake maintains all of your organization's records in a transparent and reliable manner. This class uses ACID functions to prevent corruption during busy write cycles. Your planners use a time travel tool to view or restore old files. It integrates batch and streaming data into a central database for each user. This type of storage eliminates the high cost of maintaining two different systems.
The processing and analytics
The platform uses the Spark engine to process large datasets at high speed. The analysts query the same files using SQL or Python. This course expands on learning weight models and reduces when work is completed. Serverless computing manages back-end tasks, so your team can focus on code. Faster processing means more accurate sales forecasts and better class reports this year.
AI and machine learning
This is on top of your database. Engineers use MLflow to track and manage each step of their model code. This course helps your team train models with files directly from Delta Lake. Tools like Mosaic AI allow you to build and run your own custom LLMs. You can monitor model health and track costs from a single, convenient dashboard.
Safety and security
The Unity Catalog acts as a single tool for all your enterprise data architecture security policies. Your analysts set access limits for hundreds of unique user roles from one place. The system tracks every file source and user access event. Automated logs help your security team stop leaks in less than three minutes. This course helps your organization comply with today's strict security regulations.
How Do You Build a Databricks Lakehouse Roadmap?
- Assessment of data maturity: Your team must evaluate current storage systems and quality during this first step. The architects list every database and pipeline delay. The team identifies technical gaps and missing skill sets across the entire department. This review sets a baseline for the new Databricks data lakehouse implementation.
↓
- Define business goals: Your team identifies business goals like fraud detection or supply chain tracking. Meet with department heads and map these goals to requirements. You rank these goals by their financial value and technical difficulty. Choose one project that delivers value within a 3-month window.
↓
- Design target architecture: Architects map data flow through the bronze, silver, and gold layers. These levels organize raw information into tables for business analysts. The design includes a central system to manage user permissions and security. This setup connects your cloud storage to the main compute engine.
↓
- Build pipelines: Engineers build pipelines to move numbers from legacy systems into the lakehouse. Delta Live Tables automate the flow and help manage data quality. The system converts raw files into the Delta Lake format to increase speed. Your team monitors these jobs to keep the database fresh for every user.
↓
- Run workloads: Analysts connect their standard reporting tools like Power BI to the SQL warehouse. Data scientists build machine learning models from the gold tables. A central registry tracks every machine learning model version for the whole engineering team. These points support fast decisions across the company.
↓
- Manage secure growth: Unity Catalog manages access for every user across your cloud accounts. Administrators set rules to protect sensitive information and meet legal rules. The system tracks data origins, so your team knows the source of every record. Automatic resource adjustments keep costs low as more departments join the platform.
How to Solve Common Lakehouse Adoption Challenges?
A Databricks data lakehouse implementation requires more than a simple software purchase. Your teams will face technical blocks and human doubt throughout the transition. Use these methods to protect your budget and fix issues.
Fix quality problems
Low quality at the source causes errors in your central Databricks data lakehouse. Missing or wrong records make reports useless for your executive team. Engineers use Delta Lake features to keep transactions stable and safe. For example, schema enforcement stops incorrect file types from breaking your existing tables. Regular quality checks within the pipeline create a reliable source for every department.
Manage people barriers
Employees often fear that new technology will replace their current roles or tools. Some teams prefer old warehouses and avoid the new lakehouse. For example, you must host training sessions to build confidence in the new system. Leadership must explain the direct benefits of the daily tasks of every engineer. Rewarding the first groups to switch creates a positive mood for the data department during the Databricks data lakehouse implementation.
Connect legacy data
Old databases often use proprietary formats that do not talk to modern cloud data platform options. Your teams must build custom connectors to bridge these gaps between on-premise hardware and the Databricks data lakehouse. Change capture tools solve this by tracking every new record in real time. For example, these tools push data into the cloud without slowing down your existing production workloads. A phased migration plan allows your architects to move groups one at a time.
Manage cloud costs
Cloud costs for big data can grow fast without strict rules for computing power. The architects must set limits on auto-scaling and prevent unexpected monthly bills during the Databricks data lakehouse implementation. How do you justify this spend to the board? You show value by tracking the time saved on your most expensive analytics tasks. Link these savings to clear business wins and show the worth of the platform.
OvalEdge: Real-time analytics becomes standard. A Databricks data lakehouse supports streaming, batch, and AI workloads in one system. Operator impact: dashboards update continuously, ML models train on fresh data, and decisions shift from hours to minutes.
What Are the Top Lakehouse Industry Use Cases?
Lakehouse architectures scale across different sectors to solve unique problems. The platform manages vast amounts of information for stores, banks, and hospitals. This single system supports your expansion and handles more work during company growth.
Real-time retail strategy
Problem: Retailers lose sales from a lack of timed offers during store visits. Static systems fail to identify customer needs in the moment.
Solution: Traditional batch processing delays this info by many hours and days. A Databricks data lakehouse connects your online logs with live in-store feeds.
Result: The system runs machine learning models to find the best deal for each person. These timed promotions increase your revenue and total brand loyalty.
Financial risk and fraud strategy
Problem: Financial firms lose billions each year to sophisticated fraud schemes. Legacy rules-based systems fail to spot new patterns as they happen.
Solution: A Databricks data lakehouse platform combines historical records with live transaction streams for deep analysis. Engineers deploy machine learning models that score every transaction for risk in milliseconds.
Result: Banks reduce false alerts and stop more fraudulent payments before the money leaves. This fast response improves the security of your customers and their trust in your brand.
Unified healthcare strategy
Problem: Hospitals struggle with patient data trapped in separate, disconnected systems. Doctors make choices based on incomplete medical histories and delayed lab results.
Solution: A Databricks data lakehouse brings together electronic records, medical scans, and live monitoring feeds. This design helps your teams clean and organize features via data transformation workflows for immediate clinical use.
Result: Staff sees a full picture of each patient to provide better care. Better data access reduces administrative costs and saves lives through faster intervention.

When Should You Hire a Data Engineering Partner?
Internal teams often struggle to keep up with the fast pace of Databricks projects. As project complexity grows, many organizations choose to hire data engineers with specialized Databricks expertise to accelerate delivery and reduce operational risks. A growing backlog and staff burnout signal a clear need for outside help. Hiring a specialized vendor allows your business to launch new data products without long delays.
Help your team
- Your project backlog grows every month and never seems to shrink when building data pipelines with Databricks.
- Data engineers feel burnt out and leave for roles at other companies.
- Leaders lose trust in reports because the information is often wrong or late.
- Your current staff lacks the skills to build and manage AI models.
- The team spends all day fixing old pipelines instead of legacy system modernization and building new features.
Partner benefits
- Specialized partners bring deep knowledge of the latest tools.
- Vendors use proven patterns to launch your Databricks data lakehouse implementation in weeks.
- You avoid the high cost of hiring and training new full-time staff for cloud data migration.
- Experts identify and fix security gaps before they cause data leaks.
- Your team learns new technical skills while working with the vendor.
- External teams provide a fresh look at your existing technical problems.
- Partners add or remove engineers to match your current project budget.
DATAFOREST partnership benefits
DATAFOREST builds data ingestion pipelines for companies that need fast answers. Why do large companies choose to work with us? We provide the extra hands and skills your internal team lacks right now. The team uses the Databricks data lakehouse platform to organize messy and scattered files. We move raw data into the cloud and set up safe access rules. You get a clear view of your costs and system speed in one place. This partnership turns complex technology into a tool for your daily work.
Why Switch to a Lakehouse?
The lakehouse model combines warehouses and lakes into one simple platform. Your engineers can run business reports, AI projects, batch and streaming data feeds in the same place. This design supports GenAI tasks that need large amounts of fresh information to work well. CIOs manage fewer systems and launch new machine learning models in less time. You reduce the work for your staff and get more value from your investment. Please complete the form for the Databricks data lakehouse implementation.
Questions on Databricks Data Lakehouse Implementation
How does a lakehouse differ from a traditional warehouse in terms of ROI?
Traditional warehouses require slow and costly moves to prepare data for your AI models. A modern lakehouse stores all raw and structured records in one open system to lower these expenses. You save money by cutting the need for two separate platforms and two sets of engineers. This single setup speeds up your project starts and boosts the profit from each point. Your total return rises through fewer manual fixes and more focus on data-driven decision making.
How long does it take to implement a Databricks Data Lakehouse in an enterprise environment?
A data platform deployment takes between 3 and 9 months for most large companies. The initial proof of concept phase lasts 4 to 8 weeks to validate your primary use cases. Architects spend 2 months on the core production foundation and security layers after the pilot. Expanding this platform to support all company departments and advanced predictive analytics solutions takes another 3 to 6 months. Partner with specialized teams to cut this timeline with an enterprise data migration strategy.
Is Databricks suitable for real-time analytics and AI-driven use cases?
Databricks processes through its Apache Spark data processing engine. Engineers build real-time data processing dashboards that refresh every few seconds for your store managers. The platform includes Mosaic AI to train and deploy your machine learning models on a scalable data platform. You manage all these workloads from one central Databricks data lakehouse workspace without moving files around. This unified setup provides the speed your team needs for fraud detection and stock updates.
Can a data lakehouse support both BI reporting and advanced machine learning workloads?
A unified data platform runs your BI reports and ML models on one platform. Analysts write SQL queries to build dashboards for your finance teams. Your scientists train machine learning models using the same Databricks data lakehouse source files and feature engineering workflows. This design stops the costly move of info between separate storage tools. One system gives you clear reports and smart predictions at the same time.
What industries benefit the most from implementing a Databricks Data Lakehouse?
Retail companies use a modern data lakehouse to track inventory and sales across thousands of stores in real time. Banks and insurers protect assets by identifying fraud patterns within milliseconds via real-time processing. Healthcare providers speed up medical research by managing vast amounts of genomic and patient information in an AI-ready data platform. Manufacturers reduce expensive downtime by using sensor data to predict when machines need repairs. These sectors gain a competitive edge by making faster choices based on fresh and reliable information through their data lakehouse platform.


.webp)







