

Shifting from hypothetical artificial intelligence to production, scaled AI is a zero-sum game for today’s enterprise technology in terms of Chief Data Officers and Chief Information Officers (CIOs). Gone are the days when a data scientist used Jupyter notebooks on his/her machine and created a few eye-catching prototypes. The real differentiator for Fortune 500 companies today is the strength, durability, and scalability of their underlying infrastructure that is feeding those algorithms. An important part of this operational maturity is the machine learning data pipeline.
For any enterprise AI initiative, a machine learning data pipeline is the central nervous system. It is the automated, intricately coordinated chain of processes that enables the secure extraction of unstructured, messy data from disparate data sources into consumable forms, training predictive models to yield real business value when the right decisions need to be made and reliably deploying them in production. This architectural foundation is the first roadblock for many organizations: without it, you will be in "the land of shadow AI," a zoo of individual models that will never scale, become impossible to maintain, and be prone to silent failure.
The latest State of AI report by McKinsey & Company suggests that firms that make big capital investments in automated machine learning operations and data infrastructure quality obtain an ROI that is almost 9 times higher from their AI initiatives than peers whose deployments depend entirely on manual intervention. This demonstrates a principle captured in a well-known quote: the model is just part of the entire solution. That means creating a huge amount of supporting infrastructure around it.
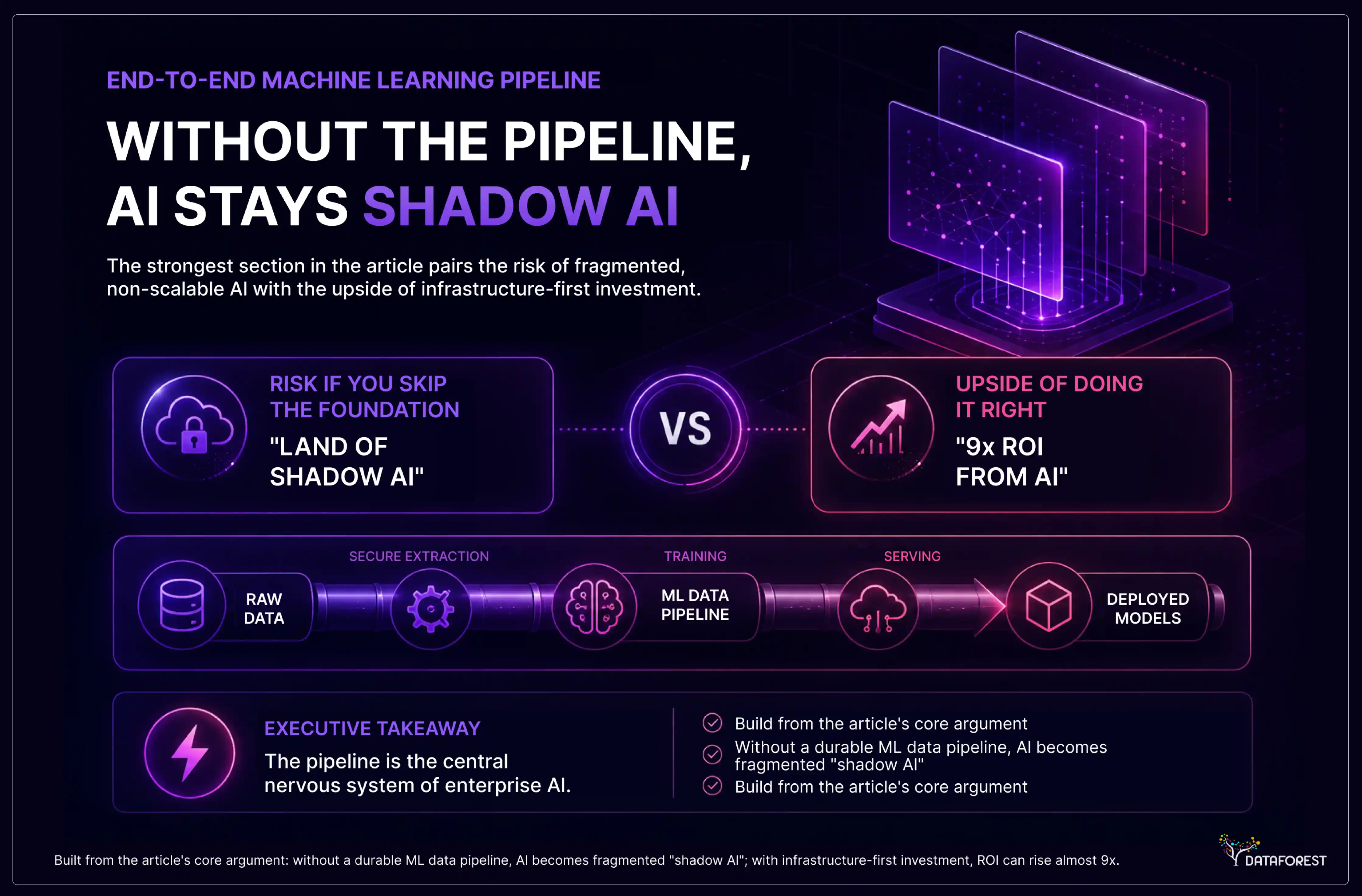
For enterprises that are building this foundational layer, a solid knowledge of the nuances around a machine learning pipeline is indispensable. Whether it involves terabytes of financial transaction logs, real-time manufacturing sensor data, or complicated health care records, the path from raw data to a model that makes business sense is the same. As organizations grow, they turn to partners that have experience in building these complex systems, such as DATAFOREST, which orchestrates data flows and maintains the performance of models.
Key Stages in an End-to-End ML Pipeline
To appreciate the true value of an end-to-end ML pipeline, it is useful to break it down into its core stages that require different tools and architectural patterns from other data pipelines.
Data Ingestion Pipeline
The first stop on this journey is the data ingestion pipeline. This is an imperative step that pulls unprocessed data from sources like SQL/NoSQL databases, SaaS APIs, and real-time event streams (i.e., Kafka). The ingestion layer needs to be fault-tolerant and able to absorb spikes in volume without losing records.
Batch and streaming are the two types of ingestion in enterprise environments. Batch ingestion pulls data in batches at scheduled intervals to train the model in an offline fashion. At the same time, processing data continuously as part of the streaming ingestion process is a must-have for dynamic pricing or real-time fraud detection. This architecture involves best practices in data integration so that the data will be safely moved to a central data lake without affecting source systems.
Data Processing and Transformation Pipeline
Most of the time, raw data coming from multiple sources is never machine learning-ready. The data processing pipeline steps in to clean, normalize, and enrich that messy unstructured data. This includes imputing missing values, treating outliers, and normalizing data types.
The data transformation pipeline — a lot of this phase is about preparing data to be consumed by algorithms. This is known as feature engineering; the science of defining new variables to better solve the business problem. For instance, converting a raw timestamp to "day of the week" can significantly improve the predictive power of your model. This is often managed by a modern architecture via an ELT pipeline (Extract, Load, Transform) processing transformations using the immense compute power of a cloud data warehouse. You can dive into these architectures in this breakdown of what an ETL pipeline is.
Model Training and Evaluation
The workflow then switches to model training mode with engineered features built and ready to use. This is where historical data is fed into machine learning algorithms to identify patterns, a process that needs heavy computational power, such as GPUs.
Training is highly iterative. Data scientists experiment with algorithms while tuning hyperparameters to get the best configuration. Most importantly, models need to be tested on a holdout dataset so that we can measure how well they will generalize to unseen tests — metrics such as precision or RMSE are tracked, depending on the task. Such experiments are logged in a central model registry in an automated ML data workflow, facilitating exhaustive reproducibility.
Model Deployment and Serving
There is zero business value in a notebook if that model is isolated there! The model deployment process is responsible for taking a validated model and making its predictions available to downstream applications or automated systems.
So we have different strategies here based on the latency needs. Batch inference is used for monthly churn predictions as a process that can go offline. On the other hand, applications that need real-time responses — e.g., e-commerce product recommendations in which you build and deploy the model as an API endpoint (containerized through Docker/Kubernetes) to generate responses in real time—need a very strong low-latency serving infrastructure.
Monitoring and Continuous Improvement
Deployment is only the start of machine learning workflow operational lifecycle solutions. This happens because production models encounter shifting data distributions (data drift) that erodes accuracy over time.
ML pipelines in production enter their most critical phase, which is continuous monitoring. Ensuring system health is critical. Engineering teams also watch system health and statistical model metrics. The pipeline must raise alerts around the drift or start automated retraining on new data if drift is detected. Organizations looking to use these feedback loops rely on MLOps services that ensure models stay performant.
Machine Learning Workflow vs the Data Engineering Pipeline
The primary confusion results from not being able to distinguish traditional data engineering from modern machine learning operations. They are interrelated, but they serve different purposes.
Where Data Engineering Stops and ML Starts
An ordinary data pipeline neatly transports and prepares data for descriptive analytics—data on what happened. The main consumers are BI dashboards and analysts.
A machine learning data pipeline, on the other hand, is designed for predictive analytics: "what will happen". The consumer is an algorithm. As a result, engineering has to enable advanced feature engineering and point-in-time correctness. Data engineers build the feature delivery infrastructure, while ML engineers consume those features to train and deploy models – with the model registry often serving as that boundary.
Breaking Data Engineering Workflows on ML Systems
Regardless of the distinction, strong data engineering workflows are at the core of any ML system. Without trusted pipelines, even the best-of-breed neural network collapses in 'garbage-in-garbage-out.'
A modern ML ecosystem that operates in an «AI-ready» fashion requires data engineering to embrace real-time streaming, automatic quality checks (think systems with some serious built-in guards), and governance. Data lineage is indispensable for compliance and debugging. Leading organizations commit significant resources to building an AI-ready data infrastructure that can support both BI reporting and advanced predictive modeling continuously side by side.
A Typical Architecture for a Production ML Pipeline
Enterprise-level ML pipeline architecture design is also a balancing act between what data scientists want and what IT operations teams need.
Typical Enterprise ML Pipeline Architecture
A mature architecture usually centers around an enterprise Data Lakehouse — some concepts of a data lake combined with concepts of governance for a data warehouse. On top of that, it meshes the compute layer — often comprising distributed clusters like Apache Spark— along with an enterprise-strength feature store to house standardized machine learning features.
The architecture also has a model registry, a deployment serving layer, and a centralized orchestration engine. By deploying pre-architected Databricks solutions, organizations can greatly improve their time-to-market when using this complex stack.
Batch vs Real-Time ML Pipelines
Architectural decisions are guided by the speed required for insight. Batch pipelines handle data in scheduled batches, which is extremely cheap for scenarios when some delay is acceptable, e.g., daily forecasts.
These real-time streaming pipelines represent another level of complexity that requires even the ingestion, processing, and prediction to happen in milliseconds. Thus, the presence of the message brokers (like Kafka) and stream processing engines (like Flink) is needed. A latency of a few seconds makes predictions useless in use cases like real-time credit card fraud detection.
Scalability and Performance Considerations
Infrastructure must scale elastically. Increased traffic should not crash recommendation engines, and training a new model should not disrupt running ETL jobs day and night.
This will require adopting a cloud-native approach, separating the storage and compute components from one another, and deploying everything in containers using something like Kubernetes. Leveraging infrastructure-as-code ensures reliable scaling. It needs a lot of work to develop this strong environment and experience in the development of data platforms.

What Are the Common Challenges in ML Data Pipelines
Converting an AI project to a robust production system presents significant challenges.
Data Quality and Consistency Issues
The leading challenge of an ML data engineering pipeline is maintaining clean data quality. ML models are highly sensitive to shifting data, unlike static software code. For example, a bit flip in the key schema or failure of an IoT sensor can taint a downstream model with no bells and whistles. Automated data contracts and anomaly detection at the ingestion layer are necessary.
Pipeline Complexity and Maintenance
When AI efforts scale, organizations accrue technical debt, creating what Eric Schmidt and Jonathan Rosenberg termed "spaghetti pipelines". Keeping these undocumented systems running is a nightmare in which a simple update brings endless failures. Pipelines should be treated as production software and implemented with modularity and well-tested components.
Lack of Orchestration and Automation
Trial and implementation for early-stage ML initiatives can be hampered by disjointed manual processes with no data orchestration or workflow orchestration. This creates deployment bottlenecks. Pipelines today rely on orchestration engines with good support for defining workflows in the form of directed acyclic graphs (DAGs) that ensure proper execution ordering and retries.
Deployment Bottlenecks
Deployment bottlenecks are caused by the gap between data science teams and IT operations. The only way to bridge that gap is to standardize MLOps processes, which can create a paved road through which data scientists can deploy models in an automated and safe manner.
Security and Compliance
GDPR, CCPA: If you want to design an enterprise pipeline in 2026, you'll have to be a privacy hawk. Pipelines need to have strong role-based access control and end-to-end data encryption, as well as PII data masking (and automation). There is a well-documented legal requirement for models in finance to be auditable and interpretable.
ML Pipeline: Tools and Techniques
How you handle the fragmented ecosystem of ML infrastructure tools depends on how those tools align with your cloud strategies.
Data Ingestion and Processing Tools
Apache Kafka continues to be the de facto solution for high-throughput streaming. In the batch ELT world, you would combine a cloud data warehouse like Snowflake or BigQuery with database transformation tools, dbt. Apache Spark borrows the concept of massive parallel computing power for heavy distributed data processing.
Workflow Orchestration Platforms
Traditional workflow orchestration is ruled by Apache Airflow, but newer alternatives like Prefect and Dagster are gaining traction as they allow users to infuse dynamic, data-aware paradigms in their workflows that cater well to the iterative machine learning process.
ML Pipeline Frameworks
MLflow is a popular open-source platform for managing the machine learning lifecycle and model registry. It offers a very scalable framework for containerized workflows. This is a very critical partner that can help you build a complete end-to-end ML pipeline.
Cloud Platforms for ML Pipelines
Countless enterprises are using fully managed platforms from the big three hyperscalers: AWS SageMaker, GCP Vertex AI, and Azure Machine Learning. They provide end-to-end solutions from data labeling to model deployment, but architects still need to manage the risk of vendor lock-in.
Submit Best Practices of an End-to-End ML Pipeline
Successful deployment leans more on architectural best practices than on using the perfect tool.
From Day 1 — Design for Scalability
To cope with the predicted future growth of data, architects should enable cloud-native architectures, deploy serverless or automatically scaling containerized environments, and select distributed processing frameworks from day one.
Automate Everything (Data + ML Work Flow)
CI/CD pipelines should automate the entire journey, starting from data extraction to model build and deployment. When a data scientist commits a new feature script, the pipeline should automatically run unit tests, initiate a training run, and provide canary deployment capabilities to be monitored for real-world performance prior to actual roll-out.
Implement Strong Data Validation
The pipeline must halt if the data is corrupted. Data quality contracts must be enforced by enterprises. The pipeline needs to assert these expectations on every incoming batch; if any assertion is violated, the pipeline will fail and should discard the poisoned data before it even reaches the model.
Use Modular Pipeline Design
Upgrading monolithic pipelines is a painful process. A highly modular design (as described here) similarly splits the pipeline into discrete microservices, allowing different teams to work on multiple pieces in parallel and subsequently simplify swapping related components as they change.
Monitor Models Continuously
Model decay is inevitable. A best-in-class pipeline would also include extensive monitoring of models post-deployment, looking for signs of data and/or concept drift, with threshold violations triggering an automated retraining and redeployment process. Full-on resources on AI and MLOps are recommended for executives to tackle such feedback loops.
How To Determine When Is the Right Time For A Business to Invest in a Production ML Pipeline
An enterprise-grade ML pipeline is a big commitment. Choosing when to act is in itself a key strategic question.
Warning Signs That Your Current ML Workflow Is A Flop
You are losing a competitive advantage when it takes months to deploy a model. Models with the "works on my machine" syndrome indicate that reproducible environments do not exist. Also, if stakeholders catch degrading predictions before engineering does, it means that you are lacking a monitoring infrastructure.
The ROI of a Well-Designed ML Data Pipeline
A mature pipeline compresses time-to-market for new AI features with less operational overhead, allowing data science talent to focus on innovation. For instance, the U.S. manufacturer that unifies enterprise data can accomplish millions of operational efficiencies by simply creating an automated data pipeline. The ROI results in areas that truly matter, like when an AI platform transforms the nature of insights available to healthcare.
Answering The Build vs Buy Question of an ML Pipeline Strategy
Upon investing, organizations must either innovate internally or work with niche consultancies.
In-House Development Challenges
Creating a resilient pipeline from scratch is an extremely challenging task that needs a multidisciplinary team of data engineers, MLOps, and cloud architects. It is costly to recruit all this talent, and it often distracts the company from its key proprietary algorithms, which offer a competitive edge.
When to Work with ML and Data Experts
Engaging a specialized data pipeline service to deploy foundational infrastructure is the strategic call for the majority of Fortune 500 enterprises. They provide time-tested frameworks that accelerate the AI roadmap and sidestep technical debt.
Partners build custom MLOps automations around the cloud-native architectures designed together. Organizations can refer to the expertise mentioned on the consulting about us pages in order to get an understanding of these methodologies.
Strategic Imperatives for the Future
2026: The New Minimum for Enterprise Survival is AI Integration; algorithms, however, don't yield ROI on their own. The real machine is the data pipeline that handles extraction and transformation—the extensively automated framework connecting messy data to order-creating knowledge.
This calls for architecting in an MLOps paradigm driven by software engineering practices, and requires durable ingestion layers, automated engineering, and continuous deployment. The C-level executives need to concentrate on developing scalable, governable data workflows. When organizations collaborate with domain experts for fast-track adoption, dormant data is reinvigorated into dynamic engines of predictive intelligence.
Set up a consultation with our world-class engineers to get started on architecting an optimized ML data pipeline for your business.
Frequently Asked Questions
An ML pipeline is a sequence of data processing steps with the goal of learning from the data.
A standard data pipeline collects, transforms, and loads (ETL), with a specific architecture for business intelligence and human visibility. ML pipeline stretches way beyond this, as it can be further optimized to put data into algorithms. This involves extensive feature engineering, model training, validation, deployment, and constant monitoring of any drift. An ML pipeline is not a human analyst; people are the final consumers of an ML pipeline, but only under certain conditions.
Machine learning pipelines create models, but which tools are used to do so?
The tools are divided by stage. Streaming ingestion is done using Apache Kafka, and distributed processing is commonly performed by Apache Spark (via Databricks). Workflow orchestration tools such as Apache Airflow or Dagster, and workflows such as MLflow or Kubeflow, manage the ML lifecycle. Integrated environments include AWS SageMaker on a cloud-native platform. Study more about how one can combine these complicated toolsets through intelligence companies for information pipeline ETL.
How does data orchestration work in ML workflows?
Think of data orchestration as the central "air traffic controller." Because of the nature of dependent tasks in an ML pipeline, such as extracting data, cleaning a job, training the model, and deploying an endpoint, orchestration tools define these workflows as Directed Acyclic Graphs (DAGs) [3] (see Fig 1). They guarantee order in how tasks get executed, retry on failure, and orchestrate complex dependency graphs between distributed computing jobs.
What is the purpose behind data engineering in ML pipelines?
Machine learning in practice starts with data engineering as a basic prerequisite. Data engineers create a secure architecture to intake raw data, cleanse anomalies, and process it until it is "AI-ready". Imagine if you had no good data engineering built on your frameworks to deliver timely, quality data, that would only lead all of your data scientists to spend time quenching Infrastructure fires and not modelling? Get a more in-depth view of these techniques through our article that explains how data engineering techniques allow the intelligent automation of data processes.
The first option is whether to build or outsource ML pipeline development.
So for the majority of enterprises, AI insight is their business differentiator, and the infrastructure code is not. Creating a strong ML pipeline from the ground up requires an internal army of niche data and cloud engineers that takes years to build. Quick time-to-market by capitalizing on best-in-class architectural patterns, i.e., outsourcing of initial development to specialized consulting partners. Internal teams can then be 100% focused on proprietary business logic, with partners handling all of the underlying machine learning in data science infrastructure.


.webp)







