

A logistics firm spent 2 million dollars on Databricks services last year. Engineers ran idle clusters during weekends and on public holidays. The team set automated shutdown rules for development workspaces. They used cheap spot instances for batch data engineering jobs. New tracking tools show daily compute costs for every project. These changes cut the total bill by 400,000 dollars in six months. Request a call, and our team will do the same.
How to Control Databricks Costs?
Databricks costs grow quickly without strict oversight of your monthly budget. Idle worker nodes and cross-region network fees waste your project's money. You stop these losses by tracking your usage system tables every day.
Prices for Databricks units
Databricks reports site usage through a metric called the Databricks Unit, or DBU. It represents the amount of processing power consumed by a single workstation node per hour. Unit prices vary depending on the product level and cloud provider you choose. You pay separate system costs for AWS or Azure compute resources. These vendors charge you directly for storing your data files on their disks. Managed serverless options simplify cluster setup but carry a higher Databricks cost per DBU consumed. All costs for these software components are included with your cloud hardware costs below.
Databricks cost drivers
Managing cloud expenses requires a clear look at your daily workspace habits.
- Large worker nodes and massive clusters consume many DBUs per hour of work, raising the Databricks cost.
- Engineers often leave development environments running long after office hours end.
- Premium and Enterprise tiers add extra Databricks costs for new security tools.
- Frequent data transfers across different cloud regions raise your egress fees.
- Serverless SQL warehouses simplify setup but charge more for each unit used.
- Heavy data volume increases your cloud storage and metadata Databricks costs every month.
How do you track the hidden expenses? You check the system tables inside your Databricks account daily.
Overlooked Databricks expenses
Cloud vendors bill you for moving data between different regions or zones. Network egress fees appear on your cloud bill from running clusters, increasing the Databricks cost. Frequent snapshots of large tables increase your monthly storage and metadata costs. Photon engine usage speeds up queries but doubles your DBU costs. Small files in your data lake slow down your data processing. Automated jobs often fail multiple times without any alerts. These wasted retries add to your bill every single day.
Streamlined Data Analytics

Their communication was great, and their ability to work within our time zone was very much appreciated.
Why Do Databricks Costs Grow So Fast?
Invisible team spending: Firms receive one massive monthly bill for all data departments. Individual engineers do not see the price of their heavy daily queries. This missing information encourages waste within every single engineering squad. Managers fail to link expenses to their own product features. The total Databricks cost increases every month without cluster ownership.
Missing FinOps rules: Data engineers prioritize code speed over the price of the cluster. They pick the largest machines for small tasks. Teams lack clear budgets for their monthly cloud experiments. Accountants struggle to read complex technical usage logs to determine the Databricks cost. No one assigns these daily costs to specific business projects.
Messy scaling: Teams add new workloads without checking the existing cluster setup. Engineers copy old code onto bigger machines for every new project. This habit creates many messy data pipelines. Clusters run at full power for simple tasks. The business adds more users, and the Databricks cost doubles.
McKinsey reviewed $3B in cloud spend and found 10–20% savings still untapped. Cost waste sits inside engineering workflows, not billing reports. FinOps must run as code inside pipelines, jobs, and cluster policies. One-time fixes fail. Cost returns when pipelines scale again.
How To Reduce Your Databricks Costs?
- Estimated value. Every dollar spent on the Databricks cost of data processing increases revenue for the company. Managers should stop investing in data projects that are not being used. Compare the monthly cluster bill to the income each worker makes. Companies end up with expensive pipelines that don't make money. This strategy turns your data center into a tangible resource.
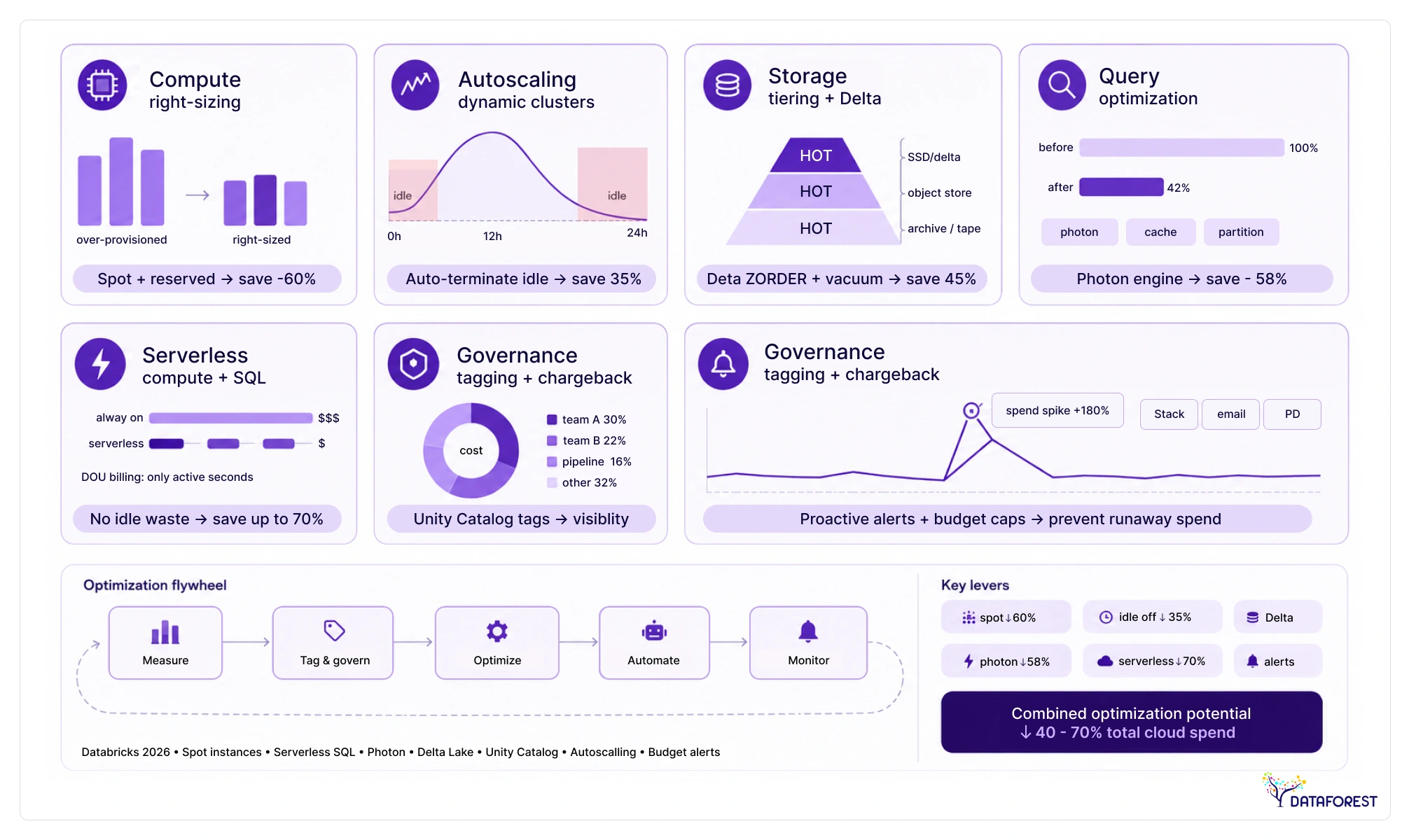
- Get the math right. Choose cluster sizes that match the actual needs of your data operations for better Databricks cost optimization. Engineers often make the mistake of choosing large machines for simple manufacturing tasks. Use autoscaling to shrink clusters when workloads are low. Spot models provide a convenient way. These solutions help your batch engineering pipelines be more consistent in capacity, lowering your bill.
- Automated Databricks cost optimization. Organizations waste a lot of time manually checking each cluster for inactive employees. You can use automated documents to close the machines ten minutes after the last operation. Cloud accounting tools organize your daily expenses into specific project types without human intervention. Smart emails send your leads for expensive jobs. These automation systems save you money and allow your engineers to focus on building new products.
Are You Tired of Wasting Money on Your Databricks Bill?
You stop this waste right now with a few simple changes. Idle clusters raise your monthly costs every single day without doing any work. Save your money and protect your profit today by tracking your usage for Databricks cost optimization.
Better cluster settings
Engineers must select the correct machine type for every data job in the workspace. Shared clusters reduce the price of development tasks by pooling hardware resources together. The Photon engine speeds up SQL queries but requires more units from your monthly budget. You should set short termination times to shut down machines during long lunch breaks. The platform adds or removes workers automatically to match the actual load of the pipeline. Check the cost logs to find which teams use the most power and increase the Databricks cost on slow projects.
Ending idle costs
Many clusters sit idle during long team meetings. These running machines drain your budget for no real business reason. A 10-minute timeout stops clusters lacking active data tasks. Monitoring tools track servers with low processing power across every single workspace. You move these small jobs to a shared resource pool. This simple cleanup reduces your monthly Databricks cost by 20%.
Compute optimization on Spark in Databricks
Poorly written code keeps clusters running longer on small datasets. Data architects should avoid Python loops when they process large tables. You must use built-in Spark functions to move your data faster. Fixing data skews stops one worker node from doing all the work. Small changes to your join logic can save 100 dollars per run. Faster scripts reduce the total hours your clusters stay awake and lower the Databricks cost.
Better data storage
Delta Lake tables use Z-Ordering to speed up data searches on disk. This layout reduces the total data your clusters must read. Frequent VACUUM commands delete old file versions from your cloud storage. You save money by removing data that your business no longer needs. Large files process faster than many small files in your data lakehouse. Merging these files into bigger blocks lowers your metadata Databricks cost.
Built-in platform tools
Databricks provides system tables to monitor every dollar spent on compute. These logs track specific users. You use cluster policies to limit machine sizes for every development team. Serverless SQL warehouses automatically scale down when analysts stop their work. Budgets and alerts send emails when spending hits 80% of your limit. These tools manage the Databricks cost without extra software.
BCG writes about cloud waste and governance failure—up to 30% of cloud spend is wasted. Main causes: poor pricing model usage, lack of FinOps discipline, excess storage, and duplication. The root issue is a lack of cost ownership per workload. Teams treat compute as infinite. Finance sees the bill later.
How to Stop Databricks Money Leaks?
Stop hidden costs by allowing each organization to pay for its own cluster usage. Clear dashboards and fixed daily limits keep your monthly Databricks cost within budget.
Track daily costs: Your team views daily usage logs in the Databricks system tables. Then you build dashboards to show how much each engineering team is spending each week. Setting up automatic notifications for the $500 daily limit will prevent the bill from growing too quickly. These tools help you see exactly where your Databricks cost is going and who is spending it.
Manage budgets: Managers set monthly limits for each data project in the workplace. Automated emails notify the company when eighty percent of the budget has been spent. You use cluster policies to prevent engineers from choosing the most expensive machines. These restrictions keep your Databricks cost within budgeted limits for the year.
Company Pricing: Each engineer pays for their own monthly cloud capacity. You use mandatory labels to associate each cluster with a named project. Company leaders review a weekly report of their current cloud spending. This rule keeps your developers focused on Databricks cost efficiency and the entire monthly budget.
What Are the Biggest Databricks Cost Mistakes?
- Engineers often select large clusters for simple data processing tasks. This choice ignores right-sizing for Databricks clusters and increases the Databricks cost on unused worker nodes, so use smaller machine sizes for Databricks cost optimization during development work.
- Teams forget to set auto-termination rules for their active workspaces. This leads to excessive idle cluster cost on Databricks all night. Set a 10-minute timeout to stop these idle machines and improve Databricks cost optimization immediately.
- Many architects ignore cheap spot instances for their long batch jobs. These Databricks instance types cost much less than standard on-demand worker instances. You save 70% on compute by switching worker types today.
- Managers allow every developer to create massive clusters without limits. Use cluster policies to control the size of new resources, and then your budget stays safe.
- Small files in the data lake slow down every Spark job. Each query must read thousands of tiny blocks from the disk. Merge these files into larger blocks for Databricks cost optimization to speed up your processing.
- Teams do not check usage logs for hidden network egress fees. Moving data between cloud regions adds costs to your monthly bill. Keep your storage and your compute in the same region.
- Teams forget to run the VACUUM command on large Delta Lake tables. They keep many old versions of your data on the cloud disks for months. You pay for this extra storage space every day, but you never use those old files. Run the cleanup tool once a week for better Databricks cost optimization.
When Is It Time to Call in The Databricks Experts?
Managing soaring Databricks costs often becomes a full-time job that pulls your engineers away from building actual product features. External specialists can quickly pinpoint DBU leaks and implement strict governance that busy internal teams might overlook. Deciding between DIY fixes and professional audits is the first step toward reclaiming your budget and scaling with confidence.
Signs for hiring cloud experts
Your monthly Databricks cost grows, but your data volume stays the same. Engineers spend ten hours a week fixing clusters and neglect their code. The CTO asks for a price report, and no one has the answer. Your team cannot explain why the bill jumped by 5,000 dollars last week. Busy developers skip cost checks to meet their tight product deadlines. The cloud budget runs out three months early. New experts find the hidden waste that your busy staff overlooks through a data modernization and cost optimization audit.
Expert optimization results
A professional partner brings deep expertise in cloud FinOps and optimizes Databricks workloads. They perform a full audit of your environment to identify every source of hidden waste. Consultants build custom dashboards that track your DBU consumption in real-time. They create strict cluster policies to stop accidental spending before it ever happens. They also support complex data migration projects, helping organizations move workloads and datasets to modern cloud architectures without disrupting operations. You get a sustainable plan that aligns your technical costs with your business value. The external perspective helps your team master the platform without the expensive trial and error.
Choosing the right path for optimization
Determining whether to handle cost management in-house or hire a specialist depends on your team's current workload and technical depth.
Choose what is important to you and order a call.
How can DATAFOREST improve your use of Databricks?
DATAFOREST starts by scanning your current location to find "hidden leaks" in your DBU usage. The company designs custom monitoring dashboards that provide a clear overview of each department's usage for Databricks cost control. Engineers refactor unnecessary Spark functions and apply Delta Lake optimization to get more performance from each cluster. We enforce control through cluster policies to ensure that expensive machines don't fail. Experts guide you through the transition to more cost-effective features such as serverless compute and automated scaling. This integration turns your Databricks workspace into a resource machine that can be a source of financial burden.
Complete the form to reduce your Databricks costs.
Questions on Databricks Cost Optimization
How can we estimate Databricks costs before scaling a new data platform?
Bills for processing power based on the Databricks pricing model are called Databricks Units. Your cloud provider bills you for server hardware and storage. Run a small test with actual data to find your average hourly unit usage. Multiply these results by your expected data amount to find a monthly total. The official Databricks calculator maps these units to local prices and includes tier updates.
What is the most cost-efficient architecture for Databricks in enterprise environments?
Start with serverless SQL warehouses to eliminate costs from idle server time. These managed tools turn on for each query and shut off as soon as the task ends to reduce Databricks spending. Select the new Standard performance mode to save up to 70% on processing bills. Store all company data in Delta Lake to optimize data storage costs on Databricks. Use spot instances for background data tests to cut hardware costs by 90%.
How does Databricks cost compared to Snowflake and BigQuery for real business workloads?
Databricks offers the lowest costs for heavy data engineering and machine learning tasks. Snowflake offers high speed for many users at the same time, but its monthly price is high. BigQuery costs only $20 per month for small organizations that run a few reports per day. Recent benchmarks show that BigQuery is three times more cost-effective during large data scans and complex table joins. Databricks prevents client lock-in by storing your data in open file formats as part of an optimized data platform architecture strategy.
What are the best practices for controlling Databricks costs in a multi-company environment?
Cloud bills are rising 20% every year due to unchecked company growth. Every company needs strict Databricks cost management policies to keep the number of employees low. Set custom labels for each project to better track costs. Move interactive SQL workloads to serverless warehouses to eliminate downtime. Catch the waste early by reading the bills every Monday morning for better cloud analytics cost reduction strategies.
How does data duplication across pipelines impact Databricks costs?
Duplicate data doubles your storage bills on cloud storage accounts. Each extra copy forces clusters to work more for every data update. To reduce data duplication, use a Delta Lake Medallion structure to keep a single source of truth. Running multiple pipelines on the same data delays results and wastes money. Moving files across different cloud regions creates high network fees. Use a Delta Lake Medallion structure to keep a single source of truth.
Can serverless computing significantly reduce Databricks costs in production environments?
Serverless computing eliminates the cost of idle servers by starting clusters only for tasks. Engineers no longer pay for the time spent waiting for a virtual machine to start or stop, effectively achieving cloud compute cost optimization. This tool scales up instantly for large jobs and turns off after the work ends. Firms using serverless SQL warehouses report 40% lower bills on average. These managed systems remove the need for manual Databricks cluster sizing and complex setup work.


.webp)







