

How to Build Real-Time Data Pipelines to Fuel AI and Analytics in the Modern Enterprise: The key architectures, core technologies, designs, and best practices
The Imperative of Instant Insight
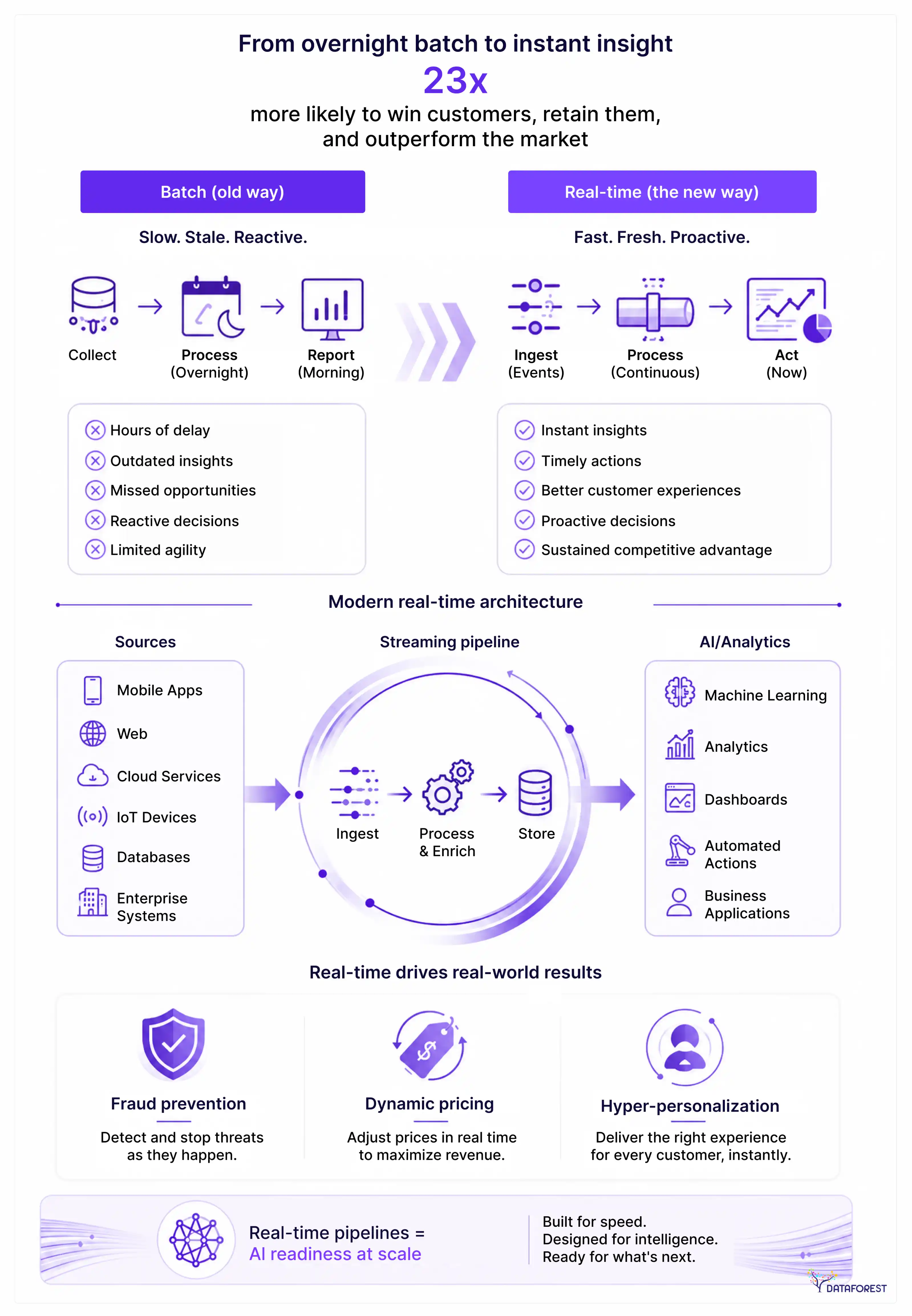
The speed at which decisions are made is key to market leadership in the modern enterprise. Gone are the days when it was acceptable to wait for overnight batch processing to reconcile operational reality. In today's rapidly changing business environment, actionable intelligence is required the instant an event transpires. Real-time data pipelines underpin the infrastructure necessary for success, be it preventing fraud, dynamic pricing in supply chain logistics, or hyper-personalizing customer experiences.
Research carried out by McKinsey & Company found that data-driven organisations that process, analyse, and access data in near real-time are 23 times more likely to obtain customers, retain them, and drive above-market profitability. But building the infrastructure for these capabilities necessitates big architectural changes. Creating real-time data pipelines has evolved from a technical enhancement to an essential strategic priority for Chief Information Officers (CIOs) and Chief Data Officers (CDOs) attempting to operationalize AI and advanced analytics on a large scale. For many CIOs and CDOs, building real time data pipelines is now the practical foundation for AI readiness at scale.
Enterprises seeking to chart a path through this transition will have to place their faith not in simple ingestion tools alone, but in broader, enterprise-level streaming architectures. Collaborating with experts like DATAFOREST can speed up the transition, guaranteeing that the data ecosystems are adaptive, scalable, and aligned with core business objectives.
Demystifying the Instantaneous Data Flow
Definition and Core Components
Real-time pipelines are an automated sequence of processes that extract the data from operational systems when it is generated, transform it on the fly, and load it into target repositories or applications with millisecond to sub-second latency. While legacy systems fetch data after scheduled intervals, streaming data pipelines operate on a push-based, continuous flow mechanism. In practice, real time data pipelines rely on data ingestion in real time and distributed data processing to keep decisions aligned with live events.
By and large, these are the constituents of that infrastructure:
Producers: Data generators (e.g., IoT sensors, transactional databases through Change Data Capture, microservices)
Ingestion Automation: Tech for real-time data ingestion is obtaining high-speed streams without dropping packets.
Stream Processing Engine: The computational aspect, where filtering, aggregation, windowing, and enrichment take place.
Serving Layer/Sink: This is usually where that processed data ends up, whether it be in a real-time analytics database, a feature store for machine learning, or even an alerting application.
It is based on an event-driven architecture, in which business processes respond to changes of state (events) in real time, and the producer and the consumer are decoupled, allowing many functions at a large scale.
Real-Time vs Batch Processing
To realize the extent of this paradigm shift, executives need to recognize what sets an outdated model apart from a modern streaming approach. Real Time ETL vs Batch Processing Discussion Marker: What do we mean — in Theory and In Practice? This is the point where real-time ETL vs batch processing becomes a business design choice, not just an engineering preference.
Primary Use Cases
Used for compliance, monthly reporting, historical model training, and payroll.
For example, fraud detection, live dashboards, dynamic pricing, and recommendation engines.
Modern Data Architecture — Where Real-Time Pipelines Have a Place
In the modern real-time analytics architecture, these pipelines can be thought of as the nervous system. They do not completely replace batch processes; they complement them. They sit between a layer of operational source systems (such as ERPs and CRMs) and downstream analytical platforms (like Data Warehouses or Data Lakes). With this ability to pass ongoing flow, they allow downstream dashboards and AI models to be fed reality in real time instead of the past. Practical data warehousing cases bring a better context for how this fits into an overall data strategy.
Architecture of Real-Time Data Pipelines in the modern world
Key Architectural Patterns
Building low-latency data pipelines requires picking the right conceptual model. Probably, Organizations usually opt for one of the widely adopted architectural patterns, choosing either the Lambda or Kappa architecture based on their operational maturity/latency needs.
Lambda vs Kappa Architecture
This pattern employs two paths running in parallel: a batch layer for large-scale, high-accuracy processing of historical data, and a speed (or streaming) layer for low-latency insights. This gives a layered view, with a serving layer that merges both views. Although Lambda architecture improves accuracy and fault tolerance, it also forces you to maintain two different codebases/infrastructures.
Kappa Architecture: To simplify the Lambda model, Kappa operates all data as a stream. Even processing historical data is actually treated as stream replay. This all-in-one approach dramatically reduces code base and infra management complexity, emerging as the de facto pattern for new-age real-time data pipelines.
Core Technology Stack
Such architectures rely on fault-resistant data streaming platforms and compute engines capable of handling distributed datasets. The same stack decisions shape data pipeline scalability and long-term data pipeline optimization as traffic grows, and as sources and downstream consumers multiply.
Message Brokers: Apache Kafka — the gold standard of high-throughput, fault-tolerant message queuing outside the usual Amazon Kinesis or Google Cloud Pub/Sub.
Processing Engines: Apache Flink and Spark Streaming are leading the battleground for processing engines, enabling sophisticated stateful operations across a wide cluster.
Data Orchestration: You need a reliable tool for managing dependencies and monitoring the flow, like Apache Airflow or Prefect.
Real-time databases: The sinks have to be able to deal with high concurrent write/read loads, often using ClickHouse, Apache Druid, or a dedicated feature store.
For enterprises that want to modernize their stack, consulting specialized teams in data engineering allows organizations to choose the tools appropriate for throughput compliance.
Cloud vs Hybrid Deployment Models
Cloud-native architectures (AWS, GCP, Azure) offer elastic scaling and managed services, but for many of the Fortune 500 companies working in super-regulated areas (banking or healthcare), that has to be hybrid. By having hybrid deployments, data streams with sensitive information can be processed on-prem for compliance, and less sensitive analytical workloads can be scaled in the cloud.
Ingestion Pipeline for Real-Time Data to AI and Machine Learning
Why AI Requires Real-Time Data
Artificial Intelligence is as smart as the data coming in. AI models trained solely on historical data are prone to "concept drift," in which predictive accuracy declines with changing real-world conditions and in volatile markets. Real-time continuous ingestion of data ensures AI models are working with the freshest possible data, deriving context from the current second instead of last quarter.
Key AI/ML Use Cases
Fraud detection
For example, in financial services, discovering a fraudulent transaction is an operational failure after the money has moved. With real-time data processing, banks can intercept and funnel transactions through an ML inference engine to block them in milliseconds. This requires exceptional pipeline stability. Find out how DATAFOREST employs these systems in the finance domain.
Other critical use cases include:
Predictive Maintenance: Predicting machine downtime before it happens by analyzing machine event data from IoT sensors deployed in manufacturing.
Dynamic Pricing: Implementing real-time dynamic pricing for e-commerce platforms and logistics services where price points vary with live supply, demand, and competitor analytics.
Hyper-Personalization: Adapting UIs and product recommendations on the fly based on real-time clickstream data. View Client Identification solutions.
Real-Time Feature Engineering
Feature engineering—the process of transforming data in its raw form into formats that machine learning (ML) models can read effectively—has to take place in transit for machine learning to run at the speed of light. Streaming ETL computes sliding window (e.g., "number of transactions by this user in the last 10 minutes") aggregations and writes them to a low-latency Feature Store for it to be available at inference time.
Combining Pipelines with AI Systems and LLM
Large Language Models (LLMs) have opened the gates for streaming pipelines supporting Retrieval-Augmented Generation (RAG). Integrating live operational data streams into vector databases enables enterprises to give LLMs context almost in real time. This allows generative AI applications to be extremely accurate and hallucination-free. Discover how this case connects to AI chatbots or broader generative AI services for reporting analysis automation.

Building Real-Time Data Pipelines — Key Challenges
Technical Challenges
Engineering fault-tolerant data pipelines for real-time workloads introduces challenges that offline batch processing does not.
State Management: If a node goes down, how would aggregations continue over time?
Exactly-Once Semantics: Maintains data consistency in streaming, which means that a transaction is neither lost nor processed twice, even during network partitions.
Data latency optimization: Identifying and eliminating the bottlenecks at every hop in the network, thus ensuring 99.999% of deliveries occur in under a second.
Organizational Challenges
Moving to event-driven architectures is a cultural change. Data teams that are in silos have to become cross-functional domains. Yet again, the upskilling gap is large — ask a traditional SQL developer with 10 years of experience to meet the needs of distributed streaming systems like Flink, and the retraining process can become difficult before a data engineer can operate with confidence.
Compliance and Data Governance
PII (Personally Identifiable Information) is often found in streaming data. For GDPR and CCPA compliance, sending data in such a way that by the time it lands within a wider analytical environment, it is anonymised or masked will always be the top priority. This is particularly relevant for industries, such as health care, which are heavily regulated with respect to data privacy.
How to Build Scalable Real-Time Pipelines
Design Principles
To comply with modern design principles and achieve high scalability of the pipeline together with successful real-time data integration, enterprises need to follow several core practices:
For example, using Kafka to decouple producers from consumers so that traffic spikes in the source system do not impact the downstream analysis database.
Example: Earliest stage of evolution — We have schema registries (say Confluent Schema Registry) in place, which avoids failure of all the pipelines when, at some point in time, the source system will change the structure of data.
Example: Dead-letter queues (DLQs) can be used to quarantine and preserve garbage records for later analysis without interrupting the primary real-time data stream.
Performance Optimization
Optimizing data pipelines is an ongoing process. Engineers need to tune partition keys carefully so that data can be evenly distributed across cluster nodes (not some "data skew" stuff). Additionally, selecting the appropriate serialization formats (for example, Apache Avro or Protobuf [or both] instead of JSON) drastically reduces payload and serialization/deserialization CPU overhead.
Reliability and Monitoring
You cannot repair what you are unable to see. In other words, to maintain the reliability of the data pipeline, proactive monitoring of pipelines is required. So enterprises need to use powerful observability stacks (e.g., Prometheus, Grafana, Datadog, etc) that track critical metrics such as consumer lag rates, throughput rates, and error spikes. Automation alerting allows engineering teams to fix latency degradation before it affects business functions.
Cost Optimization Strategies
If not managed well, the real-time infrastructure can be very expensive in terms of cost. A well-designed architecture using auto-scaling cloud compute, and Spot Instances for stateless processing nodes, along with appropriate tiered storage on streaming platforms, can dramatically reduce Total Cost of Ownership (TCO). Auditing and optimizing these costs can be achieved by engaging experts in DevOps and Cloud Solutions.
Build vs. Buy: Which Do You Choose?
As the hunger for real-time analytics grows bigger by the day, enterprise IT leaders are confronted with a dilemma: build out from open-source primitives or buy a managed, off-the-shelf solution.
When to Build In-House
Custom, bespoke systems built on open-source tools (Kafka, Flink, Spark) are well-suited for tech-forward enterprises that need maximum customization (and no vendor lock-in), and have a very high level of specific security or deployment requirements. But establishing this requires a fairly sizable, expert in-house data engineering group to bear the operational burden of cluster upkeep and tuning.
When to Partner with Experts
The business of managing infrastructure is not the core business for most Fortune 500 organizations.Companies are able to focus on business logic and reduce time-to-market by leveraging managed platforms (e.g., Confluent Cloud or Databricks) or engaging a dedicated data pipeline service provider with proven streaming expertise. Working together with a consultancy that knows the full technical stack and business use case minimises implementation risk.
Tech Partner: What to Consider When Choosing One
Select a vendor or implementation partner with a proven track record in your particular vertical and deep experience with cloud-native and hybrid deployment scenarios, as well as integration with subsequent AIs. For example, a company such as DATAFOREST provides end-to-end capabilities, starting from the ground up with custom software development and extending to deploying sophisticated AI models. We explain how we operate.
Implementation Roadmap for Enterprises
A phased, actionable transition plan that mitigates potential risks is important for businesses looking to change from legacy batch systems to a real-time paradigm.
Step 1 — Evaluate Current Data Maturity
Question 2: Consider Existing Data Silos, Data Quality Issues and Internal Technical Competencies Before Approaching Streaming Technologies. Streaming data at high volumes needs good data governance in place before an organization attempts a waterfall of streaming.
Step 2: Define Business Objectives
Know the business metrics that latency reduction will help you improve. Are you trying to guard against fraud losses, increase conversion rates through personalization, or optimize logistics routes? A thorough review of business intelligence use cases provides clarity of the ROI (high return on investment) for certain projects.
Step 3: Design Architecture
Chart out the entire data flow from end to end. Choose the right ingestion tools, processing engines, and serving layers. The architecture is, therefore, designed to be decoupled and scalable so that tomorrow you can easily plug in different AI components into the data streams.
Step 4: Pilot Project
Avoid the "big bang" approach. Begin with a low-risk, high-value pilot project. Example: This could be creating a real-time Dashboard specific to an operational unit. This allows the engineering teams to have these test beds for these data streaming platforms and help set up best practices for deployment and monitoring of these streams.
Fifth Step: Scale Across Organization
After the pilot is successful, migrate the other batch processes to streaming ETL — where they fit. Set up data contracts between domain teams, and create a Center of Excellence to govern the growing real-time processing ecosystem.
Real-time data pipeline trends ahead (2026 and Beyond)
As we move through 2026, data engineering is becoming a fast-transforming space because of growing appetites for AI.
Rise of AI-Native Data Pipelines
Pipelines are not merely passive conduits anymore; they have become smart. We are beginning to see lightweight ML models deployed at the edge or ingestion layer, which will ensure real-time data quality checks, anomaly detection, and automated schema inference with no human engagement.
Streaming-First Architectures
The batch vs. streaming mind space war is largely over. Modern data lakehouse platforms, such as Apache Iceberg and Apache Hudi, are making it easier to unify by allowing enterprises to run high-performance batch analytics directly on streaming data lakes and make streaming the ingestion pattern of choice.
Automation and Self-Healing Pipelines
Next-gen pipelines use AI for self-healing and offer advanced data pipeline monitoring. Intelligent orchestration layers afford autonomous control of dynamic traffic routing, scale-up and scale-out capabilities, and automated data bottleneck resolution, which drives a massive increase in data pipeline reliability when one of its nodes fails or if there is an unanticipated spike in the volume of active requests.
At the intersection between Data Engineering and AI engineering
These walls are falling as the silos of data engineers (who build the pipes) and AI engineers (who build the models, etc.) begin to crumble. MLOps and feature engineering are evolving toward a unified lifecycle that treats feature engineering, model training, and real-time inference as continuous, event-driven processes. Insights into AI Foundation Models for Big Business Innovation.
The Path Forward in the Age of Immediate Intelligence
Being able to process data and act on it instantly is the real competitive advantage of the digital economy today. Moving data and building real-time data pipelines is a complex architectural challenge, but the business value — possibly better customer experiences, reduced risk & harmonious operations far exceeds the envelope that needs to be pushed for implementation.
With raw events handled via solid event-driven architectures, data freshness prioritized, and streaming infrastructure shaped around AI initiatives, organizations move from being reactive to being out in front of the market. And to start architecting a data ecosystem that can enable your next-gen AI and analytics, get a consultation call with our senior architects today.
Frequently Asked Questions (FAQ)
Real-time data pipelines solve the following business problems really well:
This is a use case that will benefit from real-time data pipelines, where the value of information becomes less useful over time. These applications are particularly effective at modeling anomaly detection and fraud in finance, predictive maintenance in manufacturing, dynamic pricing and inventory management in retail, and expanding to hyper-personalization of customer recommendations. Through real-time data processing, businesses move from looking back at what happened yesterday to responding to what happens right now. Visit Big Data Analytics Use Cases for common examples in different industries.
When is a company better off building real-time data pipelines than batch processing?
Real-time pipelines are ideal for firms where latency touches revenue, customer experience, or operational safety. As a rule of thumb, you need real-time infrastructure if, due to an event, action is needed right away (e.g. blocking a transaction, adjusting the thermostat or alerting a driver). On the other hand, if your data is only for end-of-month financial reconciliation or long-term strategic reporting, traditional batch processing will still be the most simplistic and cost efficient.
What Are The Main Components Of A Scalable Real Time Data Pipeline Architecture?
A strong, scalable architecture has four key pillars:
Tools for ingestion in real time, to capture events (Debezium as CDC)
Asynchronous distributed message brokers (e.g., Apache Kafka) to decouple producers from consumers and buffer real-time streams with high velocity;
Streaming ETL: Stream processing engines (for example, Apache Flink) for continuous transformations and in-flight streaming
Low-latency Serving Layers (e.g., you might see vector databases or feature stores) to instantly serve data into prospective analytical tools or AI models. It requires some expertise in DevOps & Cloud Solutions to implement this.
What are the challenges faced when Personal Data is addressed with respect to AI and machine learning initiatives?
Just like humans, without the proper context (and in this case, a substantial amount of accurate and timely data), AI models simply cannot make valid predictions. Streaming pipelines feed live operational data to ML feature stores so that the models are always using the freshest available data (data freshness). Additionally, they allow for real-time inference that can support generative AI applications (like RAG systems) to deliver answers in real time. Check out our 50 Gen AI Use Cases for a wider scop e of different ways we can deploy AI.
What is the difference between real-time and batch data processing?
The key difference is the way data gets grouped and timed. Batch processing gathers data for a period of time and processes it as a large, bounded dataset, which introduces high latency. On the other hand, real-time data integration continuously processes data as unbound streams in response to individual events. The engineering needs are quite different between traditional batch systems and real-time systems, leading to the fact that real-time systems can be much faster but at the additional cost of needing careful design for managing data pipeline scaling and statefulness.
Benefits of Real-time data pipelining for an enterprise:
The most important advantage is operational agility. This empowers enterprises to make instantaneous data-driven decisions. Real-time data pipelines provide personalized customer engagement, immediate interception of fraudulent transactions, which can prevent financial losses, automation in the supply chain for operational efficiencies, and the very backbone technology required to enable modern Data Science and predictive AI models at scale. If you are ready to experience these advantages, get in touch via our Contact Form.


.webp)







