

BCG writes that most companies are still failing to realize meaningful returns from AI because they have not redesigned end-to-end processes or built strong data foundations. Its 2026 pieces push the same message: treat data as a strategic asset, focus on a few high-impact workflows, and redesign operating models around AI rather than layering tools onto old ones.
Building and maintaining a production-grade data platform requires specialized engineers, months of setup, and continuous operational investment, especially when organizations approach data platform development as a fully in-house initiative. For most organizations, data infrastructure has been a capital project that competes for the same engineering resources needed to build the actual product.
Data platform as a service (DPaaS) changes this equation. DPaaS shifts data infrastructure from a capital-intensive engineering project to a managed service. The question for most organizations is no longer whether to adopt it, but how to evaluate and migrate to it.
This guide covers three things you can act on:
- How to evaluate DPaaS providers across 10 dimensions, with a comparison matrix covering 8 leading vendors
- What DPaaS actually costs vs. self-managed alternatives, with a total cost of ownership model
- A 4-phase migration playbook with timelines, checklists, and common pitfalls
Whether you're a VP of Data Engineering weighing a platform migration or a CDO building a business case for the CFO, you'll leave with frameworks and numbers, not generic advice.
Key takeaways
- The global Platform as a Service market was valued at USD 167.93B in 2025 and is projected to reach USD 196.65B in 2026
- A 5-person data engineering team costs $750K per year in labor alone, before infrastructure, tooling, or overhead, making DPaaS cost-competitive at mid-market scale and above.
- The difference between 99.9% and 99.99% uptime SLAs translates to 8.7 hours vs. 52 minutes of annual downtime. Verify vendor SLA tiers before signing.
- A large GitHub study of 36,464 projects found that 89.65% experienced core-developer detachment, 70% of those detachment events happened within 3 years, and only 27.07% of detached projects regained momentum through new core developers.
- Typical data migration and modernization to DPaaS takes 6 to 12 months for a mid-size organization using a 4-phase approach: assess, pilot, migrate, optimize.
What is a data platform as a service, and why does it matter now?
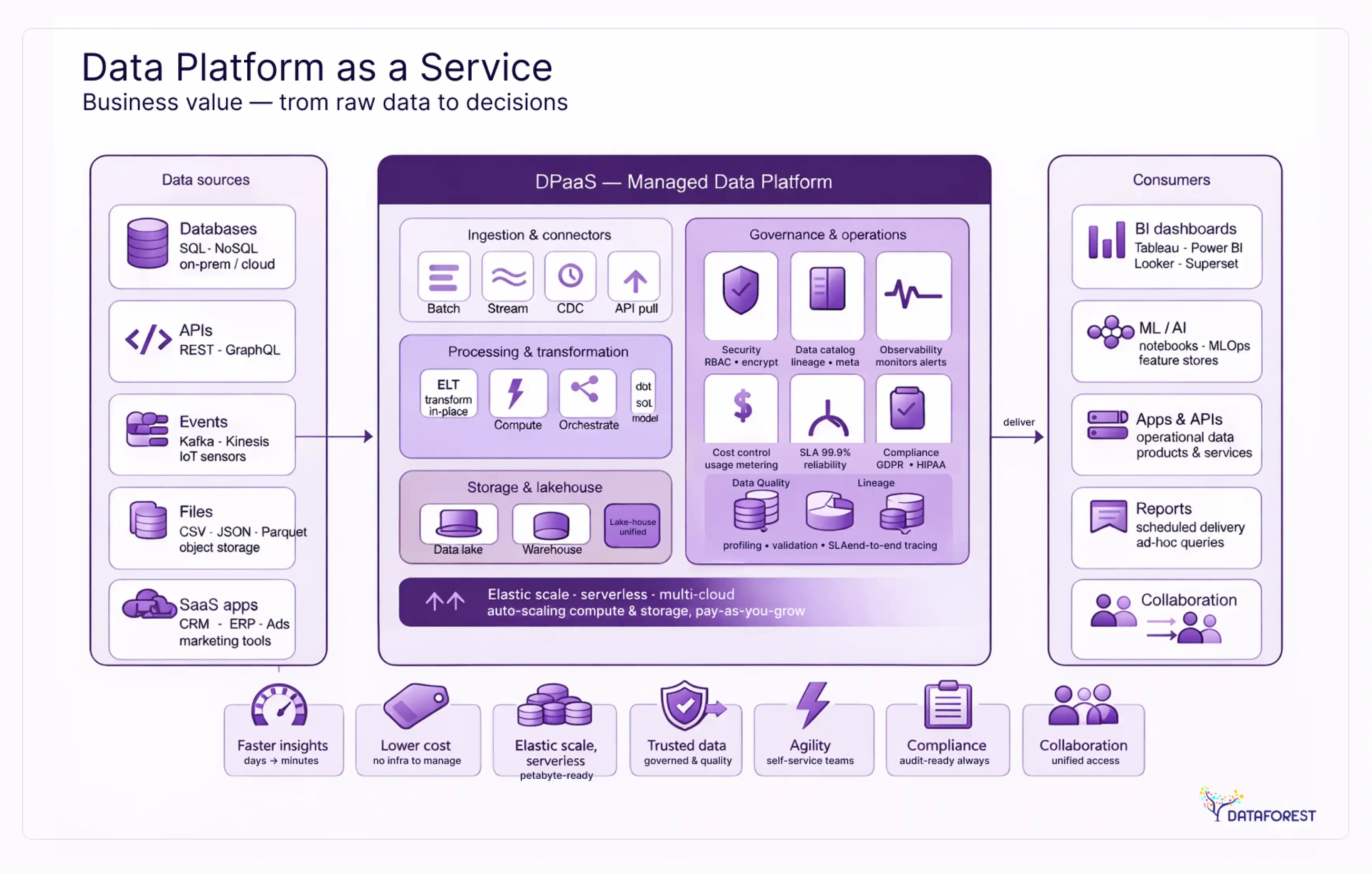
A data platform as a service (DPaaS) is a managed cloud offering that bundles storage, ingestion, transformation, analytics, and governance into a single integrated service. Unlike building a platform from scratch on raw cloud infrastructure, DPaaS shifts responsibility for provisioning, scaling, patching, and uptime to the vendor. You focus on data models, business logic, and governance policies. The vendor handles everything underneath.
The market reflects serious adoption momentum. The global Platform as a Service market was valued at USD 167.93B in 2025 and is projected to reach USD 196.65B in 2026, reflecting strong cloud-driven expansion across enterprise platforms and AI workloads. This estimate comes from Fortune Business Insights and is widely used as a baseline proxy for DPaaS-scale platform infrastructure in consulting.
The DPaaS model: what your vendor manages vs. what you own
Understanding DPaaS requires drawing a clear line between vendor-managed and customer-managed responsibilities.
Your vendor manages:
- Physical and virtual infrastructure (compute, storage, networking)
- Platform scaling (auto-scaling based on workload)
- Security patches, firmware updates, and OS maintenance
- High availability, failover, and disaster recovery
- Performance optimization at the infrastructure level
- Compliance certifications (SOC 2, ISO 27001, etc.)
You manage:
- Data modeling and schema design
- Governance policies and access controls
- Business logic and transformation rules
- Data quality standards and monitoring
- Query optimization and cost management
- Regulatory compliance specific to your industry
This split is what separates DPaaS from lower-level cloud services. With IaaS, you manage everything above the virtual machine. With PaaS, you manage the application layer. With DPaaS, you manage the data layer. The vendor handles the rest.
DPaaS vs. IaaS, PaaS, SaaS, and DaaS: where it fits
DPaaS sits between PaaS and SaaS. You get more control than SaaS (you own your data models and transformations) but less operational burden than PaaS (you don't manage the data platform software itself).
Core architecture of a modern data platform: 6 layers that drive results
Whether you build or buy, every functional data platform includes six layers. Understanding these layers is essential for designing scalable data architecture and evaluating what DPaaS vendors actually deliver versus where operational or governance gaps may still exist.
Storage: warehouse, lake, or lakehouse?
The storage layer defines how data is organized and accessed. Three architectural patterns dominate:
- Data warehouse stores structured data in optimized columnar formats for fast analytical queries. Snowflake, BigQuery, and Redshift are the primary managed options.
- Data lake stores raw data in any format (structured, semi-structured, unstructured) at low cost. S3 and Azure Data Lake Storage are common implementations.
- Data lakehouse combines both: structured query performance on top of lake-scale raw storage. Databricks Delta Lake and Apache Iceberg pioneered this approach.
Most DPaaS vendors now support lakehouse architectures, which avoids the old trade-off between analytical speed and storage flexibility.
Ingestion: batch vs. streaming pipelines
Data enters your platform through batch or streaming pipelines. Batch processing (Fivetran, Airbyte, Stitch) loads data on a schedule. Streaming (Kafka, Kinesis, Pub/Sub) delivers data continuously for real-time applications.
The choice depends on latency requirements. Fraud detection needs streaming. Monthly financial reporting works fine with batch. Most organizations run both, starting with batch and adding streaming for specific use cases.
Transformation and orchestration
Raw data isn't useful until it's cleaned, joined, and modeled. dbt has become the de facto standard for SQL-based transformations, applying software engineering practices (version control, testing, documentation) to data modeling.
Orchestration coordinates when and in what order transformations run. Airflow, Dagster, and Prefect manage pipeline dependencies, retry logic, and scheduling. In DPaaS environments, some vendors bundle orchestration natively. Databricks Workflows and BigQuery scheduled queries both reduce the need for separate orchestration tools.
Analytics, BI, and the semantic layer
The analytics layer is where business users interact with data. BI tools like Looker, Tableau, Power BI, Mode, and Sigma provide dashboards, reports, and self-service exploration.
The semantic layer sits between raw data and BI tools, defining business metrics in one place. Instead of every analyst writing their own SQL for "monthly recurring revenue," the semantic layer provides a single authoritative definition. dbt Semantic Layer, Cube.dev, and AtScale each approach this differently, but the goal is consistent metrics regardless of which tool queries them.
Data observability and governance
Observability tells you whether your data is trustworthy. Five dimensions matter: freshness (is data arriving on time?), volume (are expected row counts met?), schema (have column names or types changed unexpectedly?), distribution (are values within expected ranges?), and lineage (where did this data come from, and what depends on it?).
Governance determines who can access what data and under what conditions. This includes access policies, data classification, retention rules, and audit logging. At scale, governance operates through automated data contracts between producer teams (who create data) and consumer teams (who use it).
Both layers are non-negotiable for production data platforms. Without observability, you discover data quality issues when a dashboard shows wrong numbers to your CEO. Without governance, you discover compliance problems when regulators come asking questions.

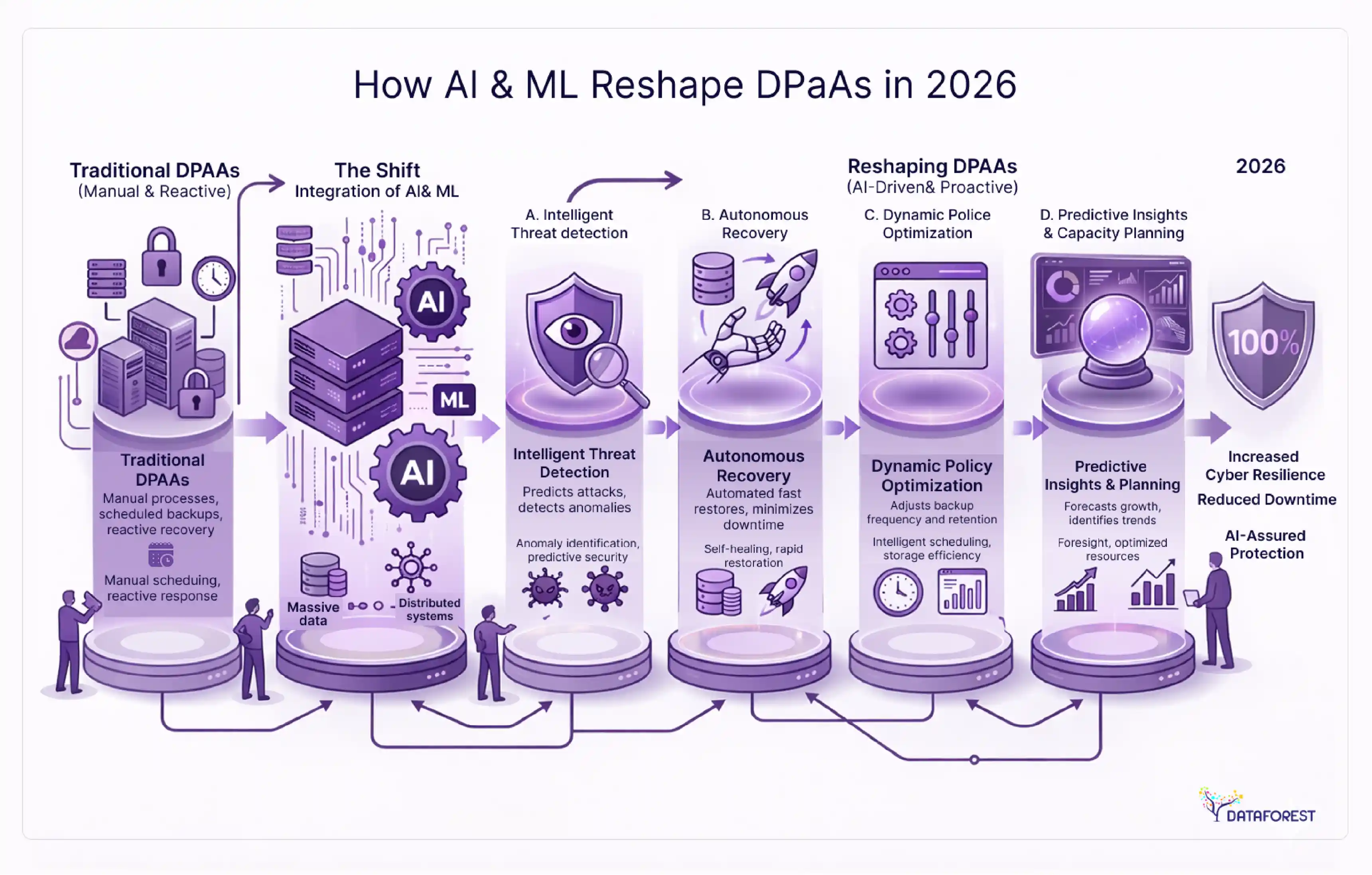
How AI and ML integration are reshaping DPaaS in 2026
The convergence of generative AI and data platforms has moved past the hype phase into production workloads. DPaaS vendors now embed AI capabilities directly into their platforms, removing the need to export data to separate ML infrastructure.
In-platform AI: Snowflake Cortex, Databricks Mosaic AI, and BigQuery ML
The leading DPaaS vendors have shipped AI features that run inside the platform:
- Snowflake Cortex provides LLM-powered functions (summarization, classification, extraction) that operate directly on warehouse data using SQL commands. No data movement required.
- Databricks Mosaic AI offers model training, fine-tuning, and serving on the same platform where your data lives. It supports both open-source models and proprietary APIs.
- BigQuery ML lets analysts train and deploy ML models using SQL syntax. For teams without dedicated ML engineers, this lowers the barrier significantly.
These native integrations matter because data movement is where AI projects fail. When teams need to extract data from a warehouse, transform it for a separate ML platform, train a model, and then push predictions back, every handoff introduces latency, cost, and failure points.
RAG pipelines and vector database integration
Retrieval-augmented generation (RAG) is the dominant pattern for grounding LLMs in enterprise data. A RAG pipeline stores document embeddings in a vector database, retrieves relevant context at query time, and passes it to an LLM for response generation.
DPaaS platforms are integrating vector search natively. Snowflake supports vector similarity search within Cortex. Databricks includes vector search through its Feature Store. For teams that need dedicated vector databases, Pinecone, PGVector (PostgreSQL extension), and MongoDB Atlas Vector Search are common choices that connect to existing DPaaS infrastructure.
The data mesh concept, which treats data as a product with clear ownership, quality guarantees, and discoverability, connects naturally to DPaaS. When the platform handles infrastructure, teams can focus on packaging data as well-defined data products that other teams can discover and consume through a data catalog. Modern AI data infrastructure also depends on governed pipelines, scalable storage layers, and real-time access patterns that support both analytics and production AI workloads.
Top DPaaS providers compared: 2026 vendor evaluation matrix
Choosing a DPaaS provider is a multi-dimensional decision. Price matters, but so does ecosystem fit, compliance coverage, and multi-cloud flexibility.
Evaluation criteria: 10 dimensions that matter
Not every criterion carries equal weight for every organization. A healthcare company will prioritize compliance differently from a media startup. Use these 10 dimensions as a starting framework, then weight them based on your context:
- Pricing model — consumption-based vs. committed capacity vs. per-seat
- Multi-cloud support — single cloud, multi-cloud, or cloud-agnostic
- Native AI/ML features — SQL-based ML, vector search, LLM integration
- Governance and compliance — SOC 2, HIPAA, GDPR, FedRAMP coverage
- Scalability — auto-scaling behavior, concurrency limits, storage limits
- Ecosystem integration — connectors, API support, partner tools
- Performance — query latency, concurrent user handling, caching
- Data sharing — cross-organization data exchange capabilities
- Developer experience — IDE support, CI/CD integration, documentation quality
- Vendor lock-in risk — open formats, data portability, standard SQL support
Vendor comparison: 8 leading DPaaS platforms
SLA and performance benchmarks across vendors
Uptime guarantees vary by vendor and service tier:
The difference between 99.9% and 99.99% translates to roughly 8.7 hours vs. 52 minutes of downtime per year. For organizations running real-time operations or regulatory reporting, that distinction matters.
Industry-specific DPaaS applications: requirements by vertical
Generic platform advice breaks down when you consider the specific requirements of regulated industries. What a financial services firm needs from DPaaS looks nothing like what a retail company needs.
Financial services: real-time compliance and regulatory lineage
Financial institutions face unique data challenges. Regulatory requirements (Basel III, MiFID II, Dodd-Frank) demand complete data lineage, the ability to trace any reported number back to its source. Anti-money laundering systems require real-time transaction monitoring across millions of events per second.
A mid-size bank that migrates from on-premises Hadoop to a cloud DPaaS typically sees significant improvements: compliance reporting shifts from batch-processed overnight cycles to near-real-time dashboards, and data infrastructure costs drop substantially. Organizations that have made this transition report cost reductions of 60% or more alongside sub-second query performance for regulatory reporting.
DPaaS platforms with built-in lineage tracking (Databricks Unity Catalog, Snowflake Horizon) reduce audit preparation effort from weeks to days.
Key DPaaS requirements for financial services: FedRAMP authorization, data residency controls, column-level encryption, and real-time streaming ingestion.
Healthcare: HIPAA-compliant data platforms
Healthcare organizations deal with protected health information (PHI) under HIPAA regulations. DPaaS adoption requires Business Associate Agreements (BAAs) with the vendor, encryption at rest and in transit, and audit logging for all data access.
The opportunity is real. Healthcare systems that consolidate clinical, claims, and operational data onto a unified DPaaS can reduce time-to-insight for population health analytics from months to days. Predictive models for patient readmission risk, for example, depend on combining electronic health records, claims data, and social determinants that typically live in separate silos.
Key DPaaS requirements for healthcare: HIPAA BAA, de-identification tools, consent management, and HL7/FHIR data connector support.
Retail and e-commerce: customer 360 and real-time inventory
Retail companies often operate with fragmented data: point-of-sale, e-commerce, loyalty programs, supply chain, and marketing platforms all generating data in isolation. A unified DPaaS enables the "customer 360" view, a single, real-time profile combining purchase history, browsing behavior, loyalty status, and service interactions.
A mid-market retailer that consolidated 12 data silos onto a unified DPaaS can achieve real-time customer visibility that enables personalized marketing and measurably improves campaign ROI. Real-time inventory visibility across stores and warehouses also reduces stockout rates and overstock costs.
Key DPaaS requirements for retail: real-time streaming ingestion, customer identity resolution, low-latency query performance, and integration with CDPs and marketing platforms.
Manufacturing: IoT data streams and predictive maintenance
Manufacturing generates massive volumes of sensor data from equipment, production lines, and quality control systems. DPaaS platforms that handle time-series data at scale enable predictive maintenance, identifying equipment failures before they cause unplanned downtime.
According to Gartner, IT systems downtime costs an average of $5,600 per minute. For manufacturing lines, costs can be significantly higher when production losses are factored in. DPaaS platforms with streaming ingestion and native ML capabilities let manufacturers deploy anomaly detection models that flag potential failures hours or days in advance.
A mid-size manufacturer that moves sensor analytics to a DPaaS with native ML can cut data infrastructure costs significantly while reducing time-to-insight from weeks to hours, enabling proactive maintenance that was previously impractical.
Key DPaaS requirements for manufacturing: time-series data support, edge computing integration, high-throughput ingestion, and ML model serving for real-time inference.
Building the business case: TCO, ROI, and the build vs. buy decision
Justifying a DPaaS investment requires concrete numbers. Abstract arguments about "data democratization" don't survive a CFO's scrutiny. Here's how to build a defensible business case.
Total cost of ownership: DPaaS vs. self-managed platforms
The total cost of a self-managed data platform extends well beyond infrastructure. Consider the full picture:
Self-managed platform costs (annual estimate, mid-market company):
- Cloud infrastructure (compute, storage, networking): $200K–500K
- Data engineering team (5 engineers at $130K–170K average per level. fyi, 2025): $650K–850K
- Data tooling licenses (ETL, BI, orchestration, monitoring): $100K–300K
- Maintenance and on-call burden: 20–30% of engineering time
- Opportunity cost: engineers maintaining infrastructure instead of building data products
A 5-person data engineering team at $150K average salary costs $750K per year in labor alone, before infrastructure, tooling, or management overhead.
DPaaS costs (annual estimate, comparable workload):
- Platform consumption (compute + storage): $150K–400K
- Reduced engineering team (3 engineers focused on data products): $390K–510K
- Remaining tooling (BI, specific connectors): $50K–150K
For reference, DPaaS pricing varies by vendor and usage pattern. Snowflake charges consumption-based credits at roughly $2–4 per credit, while BigQuery charges approximately $6.25 per TB queried.
The total cost comparison depends heavily on scale and workload complexity. At a small scale (under $100K in annual data infrastructure spend), self-managed can be cheaper. At mid-market scale and above, the labor savings from DPaaS typically outweigh the platform premium.
The build vs. buy decision framework
The build-or-buy question isn't binary. Most organizations land somewhere on a spectrum. This framework helps identify where:
DPaaS shifts data infrastructure from a capital-intensive engineering project to a managed service. For the majority of organizations, the question is no longer whether to adopt it, but how to evaluate and migrate to it.
When self-managed still wins
DPaaS isn't the right choice for every organization. Self-managed platforms make more sense when:
- You operate in a classified or air-gapped environment where cloud services are prohibited
- Your workloads require hardware-specific optimization (custom FPGAs, specialized GPUs)
- You have a large, experienced platform engineering team with low turnover
- Your data volumes and query patterns are predictable enough that reserved capacity is cheaper than consumption-based pricing
- You need full control over the software stack for regulatory or IP reasons
Also worth noting: according to TechRepublic, only about 2 percent of open-source projects see growth after their first few years. If your self-managed platform depends on niche open-source components, long-term maintenance risk is something to account for.
Data platform maturity model: 5 stages from ad-hoc to AI-native
Not every organization needs a full DPaaS implementation immediately. This maturity model helps you assess where you are and identify the right next step.
Stage 1: Ad-hoc (spreadsheets and manual processes)
Data lives in spreadsheets, email attachments, and individual databases. Reporting requires manual data collection. No single source of truth exists. Analysis depends on whoever happens to have the right file.
DPaaS readiness: Not ready. Start with basic data literacy training and identifying high-value use cases.
Stage 2: Foundational (basic warehouse + BI)
A central data warehouse exists, often a single database or basic cloud warehouse. Some BI dashboards are in place. ETL processes run, but are fragile and poorly documented. One or two people understand how the data pipeline works.
DPaaS readiness: Emerging. A DPaaS can replace fragile DIY infrastructure, but start with a pilot project to prove value.
Stage 3: Integrated (governed platform with automation)
Multiple data sources feed into a managed platform. Data governance policies exist and are enforced. Automated testing validates data quality. A data catalog provides discoverability. Multiple teams consume data through self-service tools.
DPaaS readiness: Strong. This is where DPaaS delivers the most value, extending capabilities without proportional headcount growth.
Stage 4: Self-service (federated data mesh)
Domain teams own their data products. A central platform team provides shared infrastructure and standards. Data contracts define quality guarantees between producer and consumer teams. Self-service analytics is the norm.
DPaaS readiness: Advanced. DPaaS at this stage focuses on federation, data sharing, and cross-domain analytics.
Stage 5: AI-native (predictive and generative workflows)
AI and ML are embedded throughout the data lifecycle. Predictive models run in production. Generative AI assists with data discovery, documentation, and quality monitoring. The platform optimizes itself based on usage patterns.
DPaaS readiness: Mature. At this stage, evaluate DPaaS vendors based on native AI capabilities (Cortex, Mosaic AI, BigQuery ML) and their ability to support production ML pipelines.
Maturity assessment: Score your organization on these eight dimensions on a 1–5 scale: data governance, data quality, self-service access, automation, team skills, tool standardization, executive sponsorship, and data literacy. Your average score maps to the stages above.

Migration playbook: from legacy infrastructure to DPaaS in 4 phases
Migration isn't a flip-the-switch event. It's a phased process that typically takes 6 to 12 months for a mid-size organization. Rushing increases risk. Going too slowly burns the budget, and running parallel systems.
Phase 1: Assess (weeks 1–4)
Catalog your current data assets, pipelines, and dependencies. Document every data source, transformation job, and downstream consumer. Identify quick wins (standalone workloads with few dependencies) and high-risk areas (mission-critical pipelines with complex dependencies).
Key activities:
- Inventory all data sources, pipelines, and consumers
- Map dependencies between systems
- Estimate current infrastructure costs for baseline comparison
- Select a DPaaS provider based on evaluation criteria
- Define success metrics for the migration
Phase 2: Pilot (weeks 5–10)
Migrate a single, low-risk workload to the DPaaS platform. Choose something visible enough to demonstrate value but isolated enough that failures don't affect production. Validate performance, cost, and operational workflows on the new platform.
Key activities:
- Select pilot workload (1–2 data pipelines and associated dashboards)
- Set up DPaaS environment, networking, and security
- Migrate pilot data and validate accuracy
- Run parallel operations (old and new) for 2–4 weeks
- Measure performance against baseline metrics
Phase 3: Migrate (months 3–9)
Move remaining workloads in priority order, starting with the highest-value pipelines. Use a wave-based approach: groups of related pipelines migrated together. Maintain backward compatibility during each wave so downstream systems aren't disrupted.
Key activities:
- Group pipelines into migration waves (3–6 waves typical)
- Execute each wave: migrate, validate, cutover
- Decommission legacy systems after each successful wave
- Train end users on new platform features
- Adjust DPaaS configuration based on actual usage patterns
Phase 4: Optimize (ongoing)
Migration is not the finish line. Post-migration optimization focuses on reducing costs (right-sizing compute, implementing auto-suspend), improving performance (query optimization, caching strategies), and expanding capabilities (adding AI/ML features, enabling data sharing).
Key activities:
- Review and optimize compute spending monthly
- Implement automated resource management (auto-suspend, auto-scaling rules)
- Enable new platform features (vector search, semantic layer, data sharing)
- Establish an ongoing training program for the data team
Migration readiness checklist
Before starting Phase 1, confirm these prerequisites:
- [✓] Executive sponsor identified and budget approved
- [✓] Current data inventory documented (sources, pipelines, consumers)
- [✓] Target DPaaS vendor selected and contract negotiated
- [✓] Network connectivity and security requirements defined
- [✓] Data governance policies documented and ready to implement
- [✓] Rollback plan defined for each migration wave
- [✓] Success metrics agreed upon with stakeholders
- [✓] Training plan created for data engineering and analyst teams
- [✓] Compliance requirements mapped to DPaaS vendor capabilities
- [✓] Legacy system decommission timeline planned
- [✓] Data validation framework established (automated comparison between old and new)
- [✓] On-call procedures defined for the DPaaS environment
DPaaS security, compliance, and governance at scale
Security is the area where vendor claims diverge most from reality. "Enterprise-grade security" appears in every vendor's marketing. What matters is specific implementation.
Compliance framework coverage: SOC 2, HIPAA, GDPR, FedRAMP
Different industries require different compliance frameworks. Before selecting a DPaaS vendor, map your requirements:
Most leading DPaaS vendors (Snowflake, Databricks, BigQuery, Redshift) cover SOC 2, HIPAA, and GDPR. FedRAMP coverage is less universal and should be verified for government workloads.
Data governance operating models: centralized vs. federated
Governance at scale requires choosing an operating model:
Centralized governance concentrates all policy decisions in a single team. It works well for smaller organizations or heavily regulated industries where consistency matters more than speed.
Federated governance distributes policy ownership to domain teams while maintaining central standards. Each domain team owns its data quality and access rules, but within guardrails from a central governance board. This model scales better but requires mature data teams.
Hybrid governance (most common in practice) centralizes security and compliance policies while domain teams own data quality, documentation, and stewardship. A Chief Data Officer or Head of Data Governance sets the standards; domain teams implement them.
8 red flags when evaluating DPaaS security
Watch for these during vendor evaluation:
- No SOC 2 Type II report available. Type I is a point-in-time snapshot. Type II demonstrates sustained controls over 6–12 months. Insist on Type II.
- Shared encryption keys. Your encryption keys should be under your control (Bring Your Own Key or Customer-Managed Keys). Vendor-managed keys mean the vendor can theoretically access your data.
- No data residency options. If you operate in the EU, data must stay in the EU. Verify that the vendor offers region-specific deployment, not just a promise.
- Vague audit logging. Ask to see a sample audit log if the vendor can't show who accessed what data and when; their logging isn't production-ready.
- No network isolation. Private Link or VPC peering should be available to keep traffic off the public internet. If network isolation is "coming soon," it's not ready.
- Single-tenant only at a steep premium. Multi-tenancy is fine for most workloads, but the option to isolate sensitive workloads should exist without a 5x price multiplier.
- No incident response SLA. Ask: "What's your committed response time for a security incident affecting my data?" If they hesitate, that's your answer.
- Compliance certifications have been "in progress" for years. FedRAMP authorization takes time, but if a vendor has been "in progress" for more than two years, it may never arrive.
Conclusion
The data platform market is in the middle of a structural shift from build-it-yourself to as-a-service. With Precedence Research projecting the DPaaS market to grow from $11.2 billion in 2025 to $54.3 billion by 2034, the adoption trajectory is clear.
DPaaS shifts data infrastructure from a capital-intensive engineering project to a managed service. Organizations that recognize this early will spend less time maintaining plumbing and more time building with their data.
Your next step depends on where you are. Use the maturity model to assess your starting point. If you're at Stage 2 or above, identify a pilot workload and run it through the vendor evaluation scorecard. Then start Phase 1 of the migration playbook. The frameworks in this guide are tools. They only work if you use them.
References
1. PLATFORM AS A SERVICE MARKET SIZE, SHARE & TRENDS (2026)
The PaaS market was valued at USD 167.93B in 2025 and is projected to reach USD 196.65B in 2026
Source: https://www.fortunebusinessinsights.com/platform-as-a-service-paas-market-105999
2. How Leaders Build an AI-First Cost Advantage (2026)
Most companies are still failing to realize meaningful returns from AI because they have not redesigned end-to-end processes.
https://www.bcg.com/publications/2026/how-leaders-build-an-ai-first-cost-advantage
3. Forecasting the Maintained Score from the OpenSSF Scorecard for GitHub Repositories linked to PyPI libraries (2026)
89.65% experienced core-developer detachment, 70% of those detachment events happened within 3 years, and only 27.07% of detached projects regained momentum.
https://arxiv.org/pdf/2601.18344


.webp)

.webp)
.webp)




