

A New Imperative for the Next Generation of Data Platforms
Data latency divides the market leaders and laggards in the enterprise IT ecosystem today. Using data from yesterday to make today's decision is not sustainable anymore. Even more so, as organizations scale, they hit a wall of data from microservices, IoT devices, user interactions, and external APIs! This volume necessitates a transition from legacy batch processing to an event-driven data pipeline. An event-driven data pipeline architecture enables a new level of agility in business by viewing data as a never-ending flow instead of just static records. Such companies are strategic partners. In the transition to a more future-safe foundational structure, expertise in outreach through partnerships with professionals like DATAFOREST provides strategic oversight. In practice, an event driven data pipeline helps teams react to new signals the moment they appear.
Why Traditional Data Pipelines Break Under Load
We need to understand the limitations of enterprise-grade demands of legacy architectures to appreciate how modern architecture comes into play. Old-school pipelines were designed for a world where data volumes were predictable, and SLAs were more forgiving.
So, the limitation of batch processing in a real-time environment
Batch Processing collects data for a period of time and processes it in large batches. This method is effective for analyzing historical data but does not do so well in real-time situations. If your business logic requires near real-time reactions, then you cannot wait for an overnight cron job. This inflexible timetabling causes even slight delays in data availability, making organizations reactive to history rather than responsive to the present
System Downtime, Data Latency, and Bottlenecks
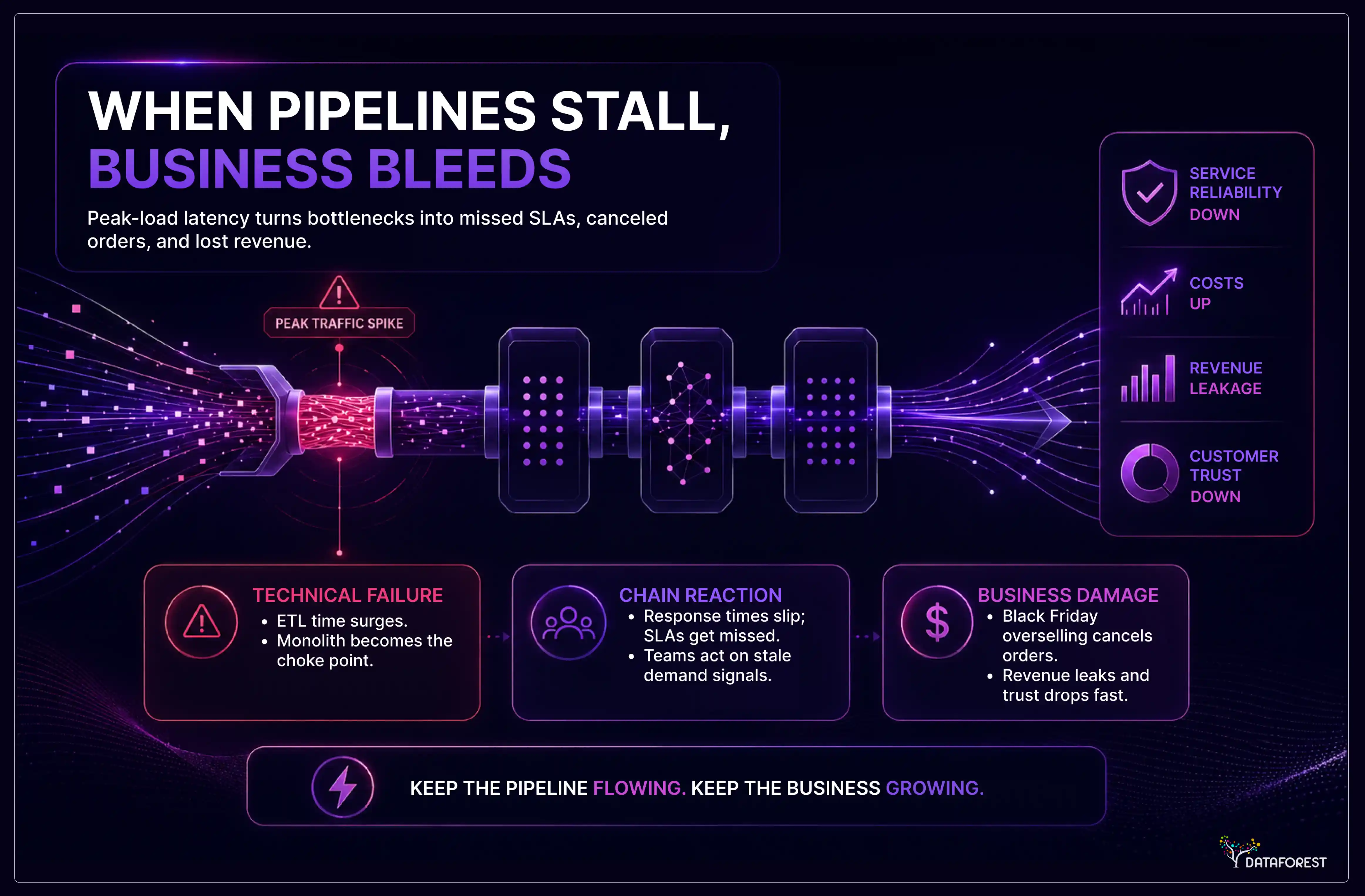
Classic systems often struggle with crippling data latency. When data volumes are large, ETL (extract, transform, load) times shoot up exponentially, leading to significant processing lags. Monolithic databases, which provide transactional writes and analytical queries in a single place, become a single point of failure. Ultimately, these flaws precipitate critical pipeline failures under peak traffic conditions, compromising response times and causing SLAs to be missed.
Scaling Monolithic and Tightly Coupled Architectures
Monolithic systems are tightly coupled, which creates a domino effect of a bottleneck in one component through the infrastructure. During high traffic, you can not scale only your ingestion layer — you have to scale the entire monolith. Such scaling issues hinder dynamic adaptation to unpredictable workloads and compel engineering teams to fight fires instead of innovating.
Business Impact: Lost Revenue, Delayed Decisions, and Lackluster Customer Experience.
The technical inadequacies end up becoming substantial business weaknesses. Data latency means losing out on intelligence and potential cash. As an illustration, e.g., if a Black Friday windfall leads to overselling of items because an e-commerce platform cannot instantly process inventory updates, followed, of course, by canceled orders. When looking more specifically in certain verticals like data architecture for finance, it becomes clear that addressing these limitations is a business imperative.
Overview on EDA: What Is Event-Driven Architecture (EDA) in Modern Data Systems
Event-Driven Architecture (EDA) is a design pattern in which decoupled applications publish and subscribe to events asynchronously. Time-series data changes that paradigm for data engineering from pulling it on a schedule to pushing it instantly across connected systems when a state change occurs.
Key Concepts: Events, Producers, Consumers & Streams
To understand EDA, one needs to understand its terminology:
Ex: Events: Record of a state change (e.g., User/Clicked ‘Buy’)
Producers — Systems or devices that generate events.
Consumers: Downstream Services consuming the events.
Streams: An ordered description of ongoing events
This fully decouples event producers from consumers, so producers need only care about the schema remaining consistent for a consumer to operate on the data they produce. Clear contracts between event producers and consumers keep the model decoupled.
What Makes Event-Driven Systems Different from Traditional Architectures
Event-driven architecture differs from synchronous request-response models (like REST APIs), as it is based on asynchronous processing. When Service A synchronously calls Service B and B fails, then A should also fail. In EDA mode, Service A sends out an event into an event stream (which is being listened to by anybody else), and it does nothing after that. This asynchronicity, by its very nature, increases resilience.
Event-Driven Data Pipelines Explained
An event-driven data pipeline uses EDA to build a data path to fetch, process, and direct the transiting data. It uses change data capture (CDC) rather than periodic batch snapshots. This leads to a very low-latency, highly horizontally scalable data pipeline architecture that can route even the most complex streams of data in real-time. Finding out about current data engineering services gives evidence of how it is used at an enterprise level.
Benefits: Scalable, Flexible, Real-Time Processing
Adopting EDA is already a game-changer. It also ensures unlimited scalability for business by enabling consumer addition without changing producers. Second, it enables real-time data processing for live dashboards and on-the-fly training of machine learning models. For one, separating components allows localized fault tolerance.
Event-Driven Data Pipeline Architecture Explained
Building a strong pipeline consists of specific components that work together to deal with high-speed data flow.
The Top 4 Building Blocks of an Event-Driven Pipeline
Hence, in a high-performing pipeline, there are usually four layers involved:
Ingestion: Extracts data from APIs, databases, or IoT.
Messaging/Streaming: Persistently stores events as the neural network of the pipeline.
Processing: Prepares and augments data in real-time.
Serving: It provides processed data to warehouses or operational apps.
Evaluating a Data Mesh layer is an important milestone to configure those layers. Check this article
Message Brokers and Event Streaming Platforms In Action
At the heart of any event streaming architecture is the message broker or streaming platform (Apache Kafka, Amazon Kinesis, etc). Traditional queues, for example, delete the messages after consuming them; on the contrary, streaming platforms keep the data around and allow many independent consumers to read from the same stream or replay events when you need to recover from a bug.
Implementing Decoupled and Asynchronous Data Flows
In a decoupled way, this is to treat the event broker as your source of truth. Pipelining can still be handled well when you impose strict schemas (via Schema Registry), allowing producers and consumers to evolve down independent paths without breaking the pipeline and ensuring that slow consumers do not adversely affect high-velocity producers.
Data Flow Lifecycle: From Ingestion to Consumption
A CDC tool captures a commit in the database and publishes it to Kafka, which is where our lifecycle starts. A stream processing framework (e.g., Apache Flink) consumes, enriches, and publishes an enriched event. Events are then written to a cloud data warehouse by a connector. To achieve optimal performance, you should ideally follow the best perf VS cost ratio and utilize any of the Databricks architecture solutions provided by Databricks. This event flow keeps ingestion, enrichment, and delivery aligned under load.

How to Build Robust Data Pipelines On Demand Under Heavy Load
An architectural resilience requirement arises when processing tens of thousands of transactions per second. For high-load systems, one has to pay extra attention to designing the system correctly in order for it to withstand some hardware failure or unpredictable spike in traffic.
Designing a distributed system and horizontal scaling
Horizontal scaling means that as the workload increases, writes are distributed across lower-cost commodity hardware. Topics are partitioned across distributed platforms. You can increase the throughput by adding more nodes to the cluster, which supports linear scaling.
Guaranteeing Fault Tolerance and High Availability
First of all, fault tolerance is achieved via aggressive data replication. In case of broker failure, the pipeline automatically switches to a replica. Checkpointing mechanisms at the processing layer ensure that a newly spawned node will begin processing at precisely the same checkpoint as the predecessor node if it crashes.
Handling Data Spikes and Backpressure
High-load systems often experience huge spikes in traffic. You need some solid backpressure…. for data spikes. If the downstream consumer is flooded, it should signal the upstream system to slow down, or a broker should be a buffer for the wave. Memory buffers overflow without backpressure, leading to cascading failures.
Data-Partitioning and Load-Balancing Strategy
The key to high throughput is a clear strategy: partition the data well by finding idempotent operations. Logical keys (i.e., CustomerID) determine how you partition data and make sure all related events are routed to the same logical consumer instance. For further exploration of advanced integration, it is recommended to check the expert data integration architecture principles.
At Scale Streaming and Real-Time Data Processing
The increasing need for real-time analytics makes it essential for enterprise architects to understand the principles of stream processing.
Stream Processing vs Batch Processing
Batch processing works on the principle that data is at rest; stream processing, that it is in motion. In other words, Batch gives us a historical view in time, while streaming provides a rolling version of truth. The industry is rapidly moving toward pure streaming (Kappa architectures) to simplify codebases.
Real-Time Analytics with Low-Latency Data Pipelines
You want to build a low-latency data pipeline with as few network hops and serialization formats as possible. Real-time platforms query streams directly without routing data to the warehouse for sub-second reporting. That is an essential must-have for lively sectors of the DATAFOREST fintech trade web page.
Continuous Data Processing with Event Streaming
We can process unbounded data by continuous queries against the incoming stream in event streaming. This is what allows complex event processing (CEP). If the event stream indicates a user changed their password, and another shows that same user logged in from a high-risk IP seconds later, for instance, it can immediately implement a security measure.
Enabling Real-Time Decision-Making
A key objective for C-level executives is real-time analytics. From adapting supply chain logistics on the fly to updating recommendation engines in the middle of a session, real-time pipelines bridge the latency between a real-world event and a business response, creating a strategic competitive moat. That speed improves data-driven decision making across operations, finance, and product teams.
Event-Driven System – Key Architecture Patterns
To implement (or design) EDA, the next step is to decide which architectural patterns are right for your use cases.
Publish/Subscribe (Pub/Sub) Model
Of them all, the Pub/Sub model is the most commonplace one. Messages are published by producers to a centralised topic and consumed by independent subscribers. Great for publishing events like "Customer Updated" to several enterprise systems at once.
Event Sourcing Pattern
Event Sourcing stores each and every state change as an immutable event in a single append-only ledger. The current state is reconstructed by replaying events. Enabling a tamper-proof audit trail is invaluable for financial institutions.
CQRS (Command Query Responsibility Segregation)
CQRS finds a clear separation between the way you modify data (Commands) and the way you retrieve it (Queries). You do this because writing and reading have different performance requirements, and by separating the two, you optimize your write database for inserts as fast as possible and your read database to query stored records as quickly as possible with very large loads.
Microservices and Event-Driven Communication
Microservices communicate with each other asynchronously through a message broker instead of calling each other via synchronous APIs. This allows application resiliency so that if one system goes down, it doesn't take the whole application with it. Research data architecture and DE consultancy in relation to wider IT strategies.
EVP Insights Bureau Business Benefits of Event-Driven Data Pipelines
Industry research strongly supports this: In order for investment in EDA to be justifiable, it needs to deliver concrete business value.
Faster Time-to-Insight with Real-Time Analytics
You eliminate the so-called "data waiting game" with a high-throughput data pipeline. Live data models can be accessed by teams, enabling marketers to optimize ad spend intra-day or the operations team to proactively reroute logistics based on rapidly changing conditions.
Improved Operational Efficiency and Automation
At the heart of EDA is improving operational efficiency through automation. As systems respond to events at their own pace, manual intervention drastically goes down, resulting in a direct decrease in operational overhead.
Scalability To Meet Increasing Data And User Needs
A streaming data pipeline easily absorbs digital spurts. The business can absorb massive traffic spikes without system failures because the architecture is horizontally scalable. To see an example of scalability in action, check out this e-commerce data management case study. That elasticity also supports business scalability without forcing costly full-stack rewrites.
Increased System Reliability and Uptime
The fault-tolerance of EDA prevents outages because the failure of an individual component does not bring down everything. This localised failure model increases application uptime dramatically and provides enterprise reputation guarantees.
Problems and the Weaknesses of Event-Driven Architecture
Shifting to an asynchronous model brings additional challenges for engineering leaders to navigate.
Debugging Distributed Systems
Debugging Event-Driven Architecture (EDA) systems, thanks to the breadth of the network, means that when a bug is traced back through all of its events, many tracing tools full of magic (such as Jaeger for distributed tracing) are needed to rebuild this map because one action can cause dozens of microservices.
Ensuring Data Consistency and Ordering
Events can arrive or be processed in a different order. Downstream reports can be 'damaged' due to these data consistency issues. Architects need ordering logic and idempotent consumer logicสัมประสิทธิภาพ
Managing System Complexity
The cognitive load is increased in an EDA. Engineers need to handle eventual consistency and dead-letter queues. When the architecture is left to itself, it can become an unwieldy mess of "event spaghetti" without strong top-down leadership.
Observability and Monitoring Challenges
Now, when it comes to traditional monitoring, this falls way short in the realm of asynchronous environments. To enable anomaly detection, teams require observability platforms capable of delivering real-time metrics about consumer lag and the percentage of error rates. If you're looking for advice on creating observable integrations, look over CDP & CRM data integration solutions.
Creating Event-Driven Data Pipelines – Best Practices
This is a big task, and to avoid such challenges, organisations need to follow enterprise-grade best practices.
Day One: Designing for Scalability
Think big here: design topic partitions and event schemas for massive scale. Spending a bit too much in the first few months is less expensive than rushing to re-architect a production system.
Implementing Robust Monitoring and Alerting
Set key Service Level Objectives (SLO) around latency. If a consumer lags behind the producer, automated alerts should fire to expand the consumer group.
Choosing the Right Technology Stack
Consider Kafka for durable streaming, Pulsar for unified messaging, or cloud-native alternatives for less operational burden. It is essential that the stack matches your team's skill set. Learn more about the US by visiting the About Us section of DATAFOREST.
Ensuring Data Governance and Security
Enforce invalid data with stricter schema registries. Encrypt data in transit and at rest, and implement Role-Based Access Control (RBAC) for sensitive event topics
Choosing Event-Driven Architecture for Your Business
Those needs require IT leaders to question whether the operational complexity of EDA is really necessary.
Are These The Signs That Your System Needs EDA?
If you are facing the following questions, then your organization needs a modern data pipeline service built on real-time event-driven principles:
Unpredictable traffic spikes are crashing databases.
A paramount requirement of sub-second decisions.
Your battery pack of tightly bound microservices has begun to develop a life of its own.
When EDA Might Be Overkill
For something like a daily reporting tool or a low-traffic, predictable system, it is probably overkill to manage Kafka clusters. A traditional database will do you more good if optimized correctly. You can get a more detailed understanding of these boundaries when you explore general data architecture best practices here.
Migration Strategy from Legacy Systems
The migration should not be a big bang rewrite. Utilize the Strangler Fig pattern: incrementally pull out certain domains, transforming each action into event-driven microservices, and gradually route the traffic so that at some point, with gradual erosion, you can simply kill your legacy system.
Implementing event-driven data pipelines the right way
Execution has to be done in phases with senior developers.
Assessing Your Current Data Architecture
Audit your existing infrastructure. For example, you could find where latency bottlenecks exist and map to where batch processing impacts the business outcome.
Designing a Scalable Data Strategy
Design your event taxonomy and schema governance before writing any code. Getting marketing and logistics to agree on the exact schema definition of a Purchase event is one way to prevent siloing within the organization.
Building and Deploying Production-Ready Pipelines
First, start with a pilot connecting one producer and one consumer. Make use of Infrastructure as Code (IaC) tools. Once the pilot is robust, bring in new sources. Take, for example, the way a medical lab gets it done with an implementation strategy.
Continuous Optimization and Scaling
Monitor performance continuously, refine partitions, and optimize consumer logic. As the volume of data that an organization handles grows, it is critical to establish FinOps practices for constant monitoring of cloud infrastructure cost-efficiency.
Strategic Imperative for Every Enterprise
Switching over from a batch pipeline to an event-driven data pattern is the most radical rewire of how a business responds to reality. Overcoming batch processing hurdles and moving towards real-time events allows organizations to achieve the agility necessary to win in high-load environments.
Get in touch with the experts to know how your organization can custom-build fault-tolerant pipeline building blocks that fit your market needs. If you want to book a consultation, do it with DATAFOREST today and get your first step into a future-proof data architecture!
FAQ
Which kinds of events are the most effective for building a pipeline?
The most minimal form of detailed action is encoding change, and the best events are discrete, permanent state changes that hold significant value for a business. These should incorporate rigid schemas with the context necessary to prevent consumers from needing to query the source system, as doing so would slow down perceptions. Refer to the DATAFOREST contact form for the Event Mapping Guide.
In an event-driven architecture, what mechanism do you use to guarantee idempotency?
Idempotency guarantees that the same event can be processed many times with the same result. This is done by creating consumer logic to validate a unique Event ID before consuming. You can either store processed IDs in a distributed cache and drop duplicates or work with database "UPSERT" operations.
What is the challenge of processing real-time events at high load?
Dealing with backpressure to avoid memory overload, ordering, and fault tolerance are all challenges to overcome. Using traditional logging, tracking data through complex data streams fails miserably in debugging scenarios, and therefore sophisticated tracing tools are required to track cross-service pipeline failures. Context on processing huge spiking data can be gleaned by looking into DATAFOREST utilities industry solutions.
How to Select a Message Broker for an Event-Driven Data Pipeline
Your choice depends on throughput and retention requirements. Up for huge scale and many years of maintenance, it is standard with Apache Kafka. Apache Pulsar is great for a hybrid between queuing and streaming. For managed cloud-native needs, AWS Kinesis or Google Cloud Pub/Sub will play a nice part. Check out data pipeline ETL intelligence services for advice on ETL.
How do you make an event-driven pipeline scale?
Horizontal scaling and Sharding provide scalability. A logical key allows the broker to distribute load by partitioning event topics. By deploying multiple consumer instances, the system can scale horizontally to balance load and create a genuinely scalable event-driven pipeline. To explore more, review how seamless data analytics helps businesses.


.webp)







